Author: Jason Brownlee
Image-to-image translation is the controlled conversion of a given source image to a target image.
An example might be the conversion of black and white photographs to color photographs.
Image-to-image translation is a challenging problem and often requires specialized models and loss functions for a given translation task or dataset.
The Pix2Pix GAN is a general approach for image-to-image translation. It is based on the conditional generative adversarial network, where a target image is generated, conditional on a given input image. In this case, the Pix2Pix GAN changes the loss function so that the generated image is both plausible in the content of the target domain, and is a plausible translation of the input image.
In this post, you will discover the Pix2Pix conditional generative adversarial network for image-to-image translation.
After reading this post, you will know:
- Image-to-image translation often requires specialized models and hand-crafted loss functions.
- Pix2Pix GAN provides a general purpose model and loss function for image-to-image translation.
- The Pix2Pix GAN was demonstrated on a wide variety of image generation tasks, including translating photographs from day to night and products sketches to photographs.
Discover how to develop DCGANs, conditional GANs, Pix2Pix, CycleGANs, and more with Keras in my new GANs book, with 29 step-by-step tutorials and full source code.
Let’s get started.
Overview
This tutorial is divided into five parts; they are:
- The Problem of Image-to-Image Translation
- Pix2Pix GAN for Image-to-Image Translation
- Pix2Pix Architectural Details
- Applications of the Pix2Pix GAN
- Insight into Pix2Pix Architectural Choices
The Problem of Image-to-Image Translation
Image-to-image translation is the problem of changing a given image in a specific or controlled way.
Examples include translating a photograph of a landscape from day to night or translating a segmented image to a photograph.
In analogy to automatic language translation, we define automatic image-to-image translation as the task of translating one possible representation of a scene into another, given sufficient training data.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
It is a challenging problem that typically requires the development of a specialized model and hand-crafted loss function for the type of translation task being performed.
Classical approaches use per-pixel classification or regression models, the problem with which is that each predicted pixel is independent of the pixels predicted before it and the broader structure of the image might be missed.
Image-to-image translation problems are often formulated as per-pixel classification or regression. These formulations treat the output space as “unstructured” in the sense that each output pixel is considered conditionally independent from all others given the input image.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
Ideally, a technique is required that is general, meaning that the same general model and loss function can be used for multiple different image-to-image translation tasks.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Pix2Pix GAN for Image-to-Image Translation
Pix2Pix is a Generative Adversarial Network, or GAN, model designed for general purpose image-to-image translation.
The approach was presented by Phillip Isola, et al. in their 2016 paper titled “Image-to-Image Translation with Conditional Adversarial Networks” and presented at CVPR in 2017.
The GAN architecture is an approach to training a generator model, typically used for generating images. A discriminator model is trained to classify images as real (from the dataset) or fake (generated), and the generator is trained to fool the discriminator model.
The Conditional GAN, or cGAN, is an extension of the GAN architecture that provides control over the image that is generated, e.g. allowing an image of a given class to be generated. Pix2Pix GAN is an implementation of the cGAN where the generation of an image is conditional on a given image.
Just as GANs learn a generative model of data, conditional GANs (cGANs) learn a conditional generative model. This makes cGANs suitable for image-to-image translation tasks, where we condition on an input image and generate a corresponding output image.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
The generator model is provided with a given image as input and generates a translated version of the image. The discriminator model is given an input image and a real or generated paired image and must determine whether the paired image is real or fake. Finally, the generator model is trained to both fool the discriminator model and to minimize the loss between the generated image and the expected target image.
As such, the Pix2Pix GAN must be trained on image datasets that are comprised of input images (before translation) and output or target images (after translation).
This general architecture allows the Pix2Pix model to be trained for a range of image-to-image translation tasks.
Pix2Pix Architectural Details
The Pix2Pix GAN architecture involves the careful specification of a generator model, discriminator model, and model optimization procedure.
Both the generator and discriminator models use standard Convolution-BatchNormalization-ReLU blocks of layers as is common for deep convolutional neural networks. Specific layer configurations are provided in the appendix of the paper.
Both generator and discriminator use modules of the form convolution-BatchNorm-ReLu.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
Let’s take a closer look at each of the two model architectures and the loss function used to optimize the model weights.
U-Net Generator Model
The generator model takes an image as input, and unlike a traditional GAN model, it does not take a point from the latent space as input.
Instead, the source of randomness comes from the use of dropout layers that are used both during training and when a prediction is made.
Instead, for our final models, we provide noise only in the form of dropout, applied on several layers of our generator at both training and test time.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
- Input: Image from source domain
- Output: Image in target domain
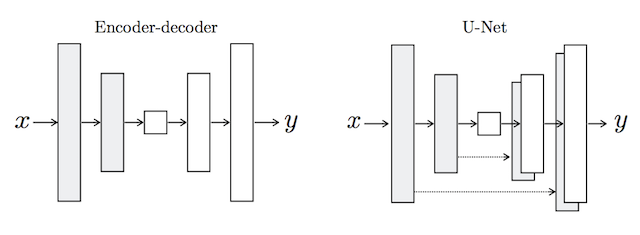
A U-Net model architecture is used for the generator, instead of the common encoder-decoder model.
The encoder-decoder generator architecture involves taking an image as input and downsampling it over a few layers until a bottleneck layer, where the representation is then upsampled again over a few layers before outputting the final image with the desired size.
The U-Net model architecture is very similar in that it involves downsampling to a bottleneck and upsampling again to an output image, but links or skip-connections are made between layers of the same size in the encoder and the decoder, allowing the bottleneck to be circumvented.
For many image translation problems, there is a great deal of low-level information shared between the input and output, and it would be desirable to shuttle this information directly across the net. […] To give the generator a means to circumvent the bottleneck for information like this, we add skip connections, following the general shape of a “U-Net”.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
For example, the first layer of the decoder has the same-sized feature maps as the last layer of the decoder and is merged with the decoder. This is repeated with each layer in the encoder and corresponding layer of the decoder, forming a U-shaped model.
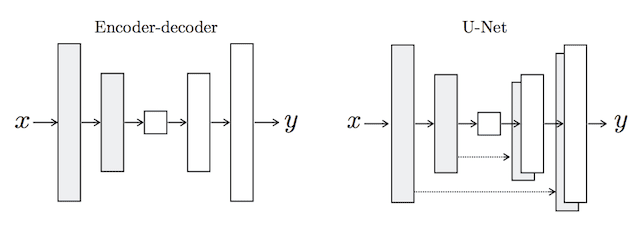
Depiction of the Encoder-Decoder Generator and U-Net Generator Models.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
PatchGAN Discriminator Model
The discriminator model takes an image from the source domain and an image from the target domain and predicts the likelihood of whether the image from the target domain is a real or generated version of the source image.
- Input: Image from source domain, and Image from the target domain.
- Output: Probability that the image from the target domain is a real translation of the source image.
The input to the discriminator model highlights the need to have an image dataset comprised of paired source and target images when training the model.
Unlike the traditional GAN model that uses a deep convolutional neural network to classify images, the Pix2Pix model uses a PatchGAN. This is a deep convolutional neural network designed to classify patches of an input image as real or fake, rather than the entire image.
… we design a discriminator architecture – which we term a PatchGAN – that only penalizes structure at the scale of patches. This discriminator tries to classify if each NxN patch in an image is real or fake. We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
The PatchGAN discriminator model is implemented as a deep convolutional neural network, but the number of layers is configured such that the effective receptive field of each output of the network maps to a specific size in the input image. The output of the network is a single feature map of real/fake predictions that can be averaged to give a single score.
A patch size of 70×70 was found to be effective across a range of image-to-image translation tasks.
Composite Adversarial and L1 Loss
The discriminator model is trained in a standalone manner in the same way as a traditional GAN model, minimizing the negative log likelihood of identifying real and fake images, although conditioned on a source image.
The training of the discriminator is too fast compared to the generator, therefore the discriminator loss is halved in order to slow down the training process.
- Discriminator Loss = 0.5 * Discriminator Loss
The generator model is trained using both the adversarial loss for the discriminator model and the L1 or mean absolute pixel difference between the generated translation of the source image and the expected target image.
The adversarial loss and the L1 loss are combined into a composite loss function, which is used to update the generator model. L2 loss was also evaluated and found to result in blurry images.
The discriminator’s job remains unchanged, but the generator is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense. We also explore this option, using L1 distance rather than L2 as L1 encourages less blurring
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
The adversarial loss influences whether the generator model can output images that are plausible in the target domain, whereas the L1 loss regularizes the generator model to output images that are a plausible translation of the source image. As such, the combination of the L1 loss to the adversarial loss is controlled by a new hyperparameter lambda, which is set to 10, e.g. giving 10 times the importance of the L1 loss than the adversarial loss to the generator during training.
- Generator Loss = Adversarial Loss + Lambda * L1 Loss
Applications of the Pix2Pix GAN
The Pix2Pix GAN was demonstrated on a range of interesting image-to-image translation tasks.
For example, the paper lists nine applications; they are:
- Semantic labels <-> photo, trained on the Cityscapes dataset.
- Architectural labels -> photo, trained on Facades.
- Map <-> aerial photo, trained on data scraped from Google Maps.
- Black and White -> color photos.
- Edges -> photo.
- Sketch -> photo.
- Day -> night photographs.
- Thermal -> color photos.
- Photo with missing pixels -> inpainted photo, trained on Paris StreetView.
In this section, we’ll review a few of the examples taken from the paper.
Semantic Labels to Photographs
The example below demonstrates the translation of semantic labeled images to photographs of street scenes.

Pix2Pix GAN Translation of Semantic Images to Photographs of a Cityscape.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Another example is provided demonstrating semantic labeled images of building facades to photographs.

Pix2Pix GAN Translation of Semantic Images to Photographs of Building Facades.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Daytime to Nighttime Photographs
The example below demonstrates the translation of daytime to nighttime photographs.

Pix2Pix GAN Translation of Daytime Photographs to Nighttime.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Product Sketch to Photograph
The example below demonstrates the translation of product sketches of bags to photographs.

Pix2Pix GAN Translation of Product Sketches of Bags to Photographs.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Similar examples are given for translating sketches of shoes to photographs.

Pix2Pix GAN Translation of Product Sketches of Shoes to Photographs.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Photograph Inpainting
The example below demonstrates inpainting photographs of streetscapes taken in Paris.

Pix2Pix GAN Inpainting Photographs of Paris.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Thermal Image to Color Photograph
The example below demonstrates the translation of thermal images to color photographs of streetscapes.

Pix2Pix GAN Translation of Thermal Images to Color Photographs.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Insight into Pix2Pix Architectural Choices
The authors explore and analyze the effect of different model configurations and loss functions on image quality, supporting the architectural choices.
The findings from these experiments shed light on perhaps why the Pix2Pix approach is effective across a wide range of image translation tasks.
Analysis of Loss Function
Experiments are performed to compare different loss functions used to train the generator model.
These included only using the L1 loss, only the conditional adversarial loss, only using unconditional adversarial loss, and combinations of L1 with each adversarial loss.
The results were interesting, showing that L1 and conditional adversarial loss alone can generate reasonable images, although the L1 images were blurry and the cGAN images introduced artifacts. The combination of the two gave the clearest results.
L1 alone leads to reasonable but blurry results. The cGAN alone […] gives much sharper results but introduces visual artifacts on certain applications. Adding both terms together (with lambda = 100) reduces these artifacts.
— Image-to-Image Translation With Conditional Adversarial Networks, 2016.

Generated Images Using L1, Conditional Adversarial (cGAN), and Composite Loss Functions.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Analysis of Generator Model
The U-Net generator model architecture was compared to a more common encoder-decoder generator model architecture.
Both approaches were compared with just L1 loss and L1 + conditional adversarial loss, showing that the encoder-decoder was able to generate images in both cases, but the images were much sharper when using the U-Net architecture.
The encoder-decoder is unable to learn to generate realistic images in our experiments. The advantages of the U-Net appear not to be specific to conditional GANs: when both U-Net and encoder-decoder are trained with an L1 loss, the U-Net again achieves the superior results.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.

Generated Images Using the Encoder-Decoder and U-Net Generator Models Under Different Loss.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Analysis of Discriminator Model
Experiments were performed comparing the PatchGAN discriminator with different sized effective receptive fields.
Versions of the model were tested from a 1×1 receptive field or PixelGAN, through to a full-sized 256×256 or ImageGAN, as well as smaller 16×16 and 70×70 PatchGANs.
The larger the receptive field, the deeper the network. This means that the 1×1 PixelGAN is the shallowest model and the 256×256 ImageGAN is the deepest model.
The results showed that very small receptive fields can generate effective images, although the full sized ImageGAN provides crisper results, but is harder to train. Using a smaller 70×70 receptive field provided a good trade-off of performance (model depth) and image quality.
The 70×70 PatchGAN […] achieves slightly better scores. Scaling beyond this, to the full 286×286 ImageGAN, does not appear to improve the visual quality […] This may be because the ImageGAN has many more parameters and greater depth than the 70 × 70 PatchGAN, and may be harder to train.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.

Generated Images Using PatchGANs With Different Sized Receptive Fields.
Taken from: Image-to-Image Translation With Conditional Adversarial Networks.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Image-to-Image Translation with Conditional Adversarial Networks, 2016.
- Image-to-Image Translation with Conditional Adversarial Nets, Homepage.
- Image-to-image translation with conditional adversarial nets, GitHub.
- pytorch-CycleGAN-and-pix2pix, GitHub.
- Interactive Image-to-Image Demo, 2017.
- Pix2Pix Datasets
Summary
In this post, you discovered the Pix2Pix conditional generative adversarial networks for image-to-image translation.
Specifically, you learned:
- Image-to-image translation often requires specialized models and hand-crafted loss functions.
- Pix2Pix GAN provides a general purpose model and loss function for image-to-image translation.
- The Pix2Pix GAN was demonstrated on a wide variety of image generation tasks, including translating photographs from day to night and products sketches to photographs.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post A Gentle Introduction to Pix2Pix Generative Adversarial Network appeared first on Machine Learning Mastery.