
Author: Jason Brownlee
Exponential smoothing is a time series forecasting method for univariate data that can be extended to support data with a systematic trend or seasonal component.
It is common practice to use an optimization process to find the model hyperparameters that result in the exponential smoothing model with the best performance for a given time series dataset. This practice applies only to the coefficients used by the model to describe the exponential structure of the level, trend, and seasonality.
It is also possible to automatically optimize other hyperparameters of an exponential smoothing model, such as whether or not to model the trend and seasonal component and if so, whether to model them using an additive or multiplicative method.
In this tutorial, you will discover how to develop a framework for grid searching all of the exponential smoothing model hyperparameters for univariate time series forecasting.
After completing this tutorial, you will know:
- How to develop a framework for grid searching ETS models from scratch using walk-forward validation.
- How to grid search ETS model hyperparameters for daily time series data for female births.
- How to grid search ETS model hyperparameters for monthly time series data for shampoo sales, car sales, and temperature.
Let’s get started.

How to Grid Search Triple Exponential Smoothing for Time Series Forecasting in Python
Photo by john mcsporran, some rights reserved.
Tutorial Overview
This tutorial is divided into six parts; they are:
- Exponential Smoothing for Time Series Forecasting
- Develop a Grid Search Framework
- Case Study 1: No Trend or Seasonality
- Case Study 2: Trend
- Case Study 3: Seasonality
- Case Study 4: Trend and Seasonality
Exponential Smoothing for Time Series Forecasting
Exponential smoothing is a time series forecasting method for univariate data.
Time series methods like the Box-Jenkins ARIMA family of methods develop a model where the prediction is a weighted linear sum of recent past observations or lags.
Exponential smoothing forecasting methods are similar in that a prediction is a weighted sum of past observations, but the model explicitly uses an exponentially decreasing weight for past observations.
Specifically, past observations are weighted with a geometrically decreasing ratio.
Forecasts produced using exponential smoothing methods are weighted averages of past observations, with the weights decaying exponentially as the observations get older. In other words, the more recent the observation, the higher the associated weight.
— Page 171, Forecasting: principles and practice, 2013.
Exponential smoothing methods may be considered as peers and an alternative to the popular Box-Jenkins ARIMA class of methods for time series forecasting.
Collectively, the methods are sometimes referred to as ETS models, referring to the explicit modeling of Error, Trend, and Seasonality.
There are three types of exponential smoothing; they are:
- Single Exponential Smoothing, or SES, for univariate data without trend or seasonality.
- Double Exponential Smoothing for univariate data with support for trends.
- Triple Exponential Smoothing, or Holt-Winters Exponential Smoothing, with support for both trends and seasonality.
A triple exponential smoothing model subsumes single and double exponential smoothing by the configuration of the nature of the trend (additive, multiplicative, or none) and the nature of the seasonality (additive, multiplicative, or none), as well as any dampening of the trend.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Develop a Grid Search Framework
In this section, we will develop a framework for grid searching exponential smoothing model hyperparameters for a given univariate time series forecasting problem.
We will use the implementation of Holt-Winters Exponential Smoothing provided by the statsmodels library.
This model has hyperparameters that control the nature of the exponential performed for the series, trend, and seasonality, specifically:
- smoothing_level (alpha): the smoothing coefficient for the level.
- smoothing_slope (beta): the smoothing coefficient for the trend.
- smoothing_seasonal (gamma): the smoothing coefficient for the seasonal component.
- damping_slope (phi): the coefficient for the damped trend.
All four of these hyperparameters can be specified when defining the model. If they are not specified, the library will automatically tune the model and find the optimal values for these hyperparameters (e.g. optimized=True).
There are other hyperparameters that the model will not automatically tune that you may want to specify; they are:
- trend: The type of trend component, as either “add” for additive or “mul” for multiplicative. Modeling the trend can be disabled by setting it to None.
- damped: Whether or not the trend component should be damped, either True or False.
- seasonal: The type of seasonal component, as either “add” for additive or “mul” for multiplicative. Modeling the seasonal component can be disabled by setting it to None.
- seasonal_periods: The number of time steps in a seasonal period, e.g. 12 for 12 months in a yearly seasonal structure.
- use_boxcox: Whether or not to perform a power transform of the series (True/False) or specify the lambda for the transform.
If you know enough about your problem to specify one or more of these parameters, then you should specify them. If not, you can try grid searching these parameters.
We can start-off by defining a function that will fit a model with a given configuration and make a one-step forecast.
The exp_smoothing_forecast() below implements this behavior.
The function takes an array or list of contiguous prior observations and a list of configuration parameters used to configure the model.
The configuration parameters in order are: the trend type, the dampening type, the seasonality type, the seasonal period, whether or not to use a Box-Cox transform, and whether or not to remove the bias when fitting the model.
# one-step Holt Winter's Exponential Smoothing forecast def exp_smoothing_forecast(history, config): t,d,s,p,b,r = config # define model model = ExponentialSmoothing(history, trend=t, damped=d, seasonal=s, seasonal_periods=p) # fit model model_fit = model.fit(optimized=True, use_boxcox=b, remove_bias=r) # make one step forecast yhat = model_fit.predict(len(history), len(history)) return yhat[0]
Next, we need to build up some functions for fitting and evaluating a model repeatedly via walk-forward validation, including splitting a dataset into train and test sets and evaluating one-step forecasts.
We can split a list or NumPy array of data using a slice given a specified size of the split, e.g. the number of time steps to use from the data in the test set.
The train_test_split() function below implements this for a provided dataset and a specified number of time steps to use in the test set.
# split a univariate dataset into train/test sets def train_test_split(data, n_test): return data[:-n_test], data[-n_test:]
After forecasts have been made for each step in the test dataset, they need to be compared to the test set in order to calculate an error score.
There are many popular errors scores for time series forecasting. In this case, we will use root mean squared error (RMSE), but you can change this to your preferred measure, e.g. MAPE, MAE, etc.
The measure_rmse() function below will calculate the RMSE given a list of actual (the test set) and predicted values.
# root mean squared error or rmse def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted))
We can now implement the walk-forward validation scheme. This is a standard approach to evaluating a time series forecasting model that respects the temporal ordering of observations.
First, a provided univariate time series dataset is split into train and test sets using the train_test_split() function. Then the number of observations in the test set are enumerated. For each, we fit a model on all of the history and make a one step forecast. The true observation for the time step is then added to the history, and the process is repeated. The exp_smoothing_forecast() function is called in order to fit a model and make a prediction. Finally, an error score is calculated by comparing all one-step forecasts to the actual test set by calling the measure_rmse() function.
The walk_forward_validation() function below implements this, taking a univariate time series, a number of time steps to use in the test set, and an array of model configurations.
# walk-forward validation for univariate data def walk_forward_validation(data, n_test, cfg): predictions = list() # split dataset train, test = train_test_split(data, n_test) # seed history with training dataset history = [x for x in train] # step over each time-step in the test set for i in range(len(test)): # fit model and make forecast for history yhat = exp_smoothing_forecast(history, cfg) # store forecast in list of predictions predictions.append(yhat) # add actual observation to history for the next loop history.append(test[i]) # estimate prediction error error = measure_rmse(test, predictions) return error
If you are interested in making multi-step predictions, you can change the call to predict() in the exp_smoothing_forecast() function and also change the calculation of error in the measure_rmse() function.
We can call walk_forward_validation() repeatedly with different lists of model configurations.
One possible issue is that some combinations of model configurations may not be called for the model and will throw an exception, e.g. specifying some but not all aspects of the seasonal structure in the data.
Further, some models may also raise warnings on some data, e.g. from the linear algebra libraries called by the statsmodels library.
We can trap exceptions and ignore warnings during the grid search by wrapping all calls to walk_forward_validation() with a try-except and a block to ignore warnings. We can also add debugging support to disable these protections in case we want to see what is really going on. Finally, if an error does occur, we can return a None result; otherwise, we can print some information about the skill of each model evaluated. This is helpful when a large number of models are evaluated.
The score_model() function below implements this and returns a tuple of (key and result), where the key is a string version of the tested model configuration.
# score a model, return None on failure
def score_model(data, n_test, cfg, debug=False):
result = None
# convert config to a key
key = str(cfg)
# show all warnings and fail on exception if debugging
if debug:
result = walk_forward_validation(data, n_test, cfg)
else:
# one failure during model validation suggests an unstable config
try:
# never show warnings when grid searching, too noisy
with catch_warnings():
filterwarnings("ignore")
result = walk_forward_validation(data, n_test, cfg)
except:
error = None
# check for an interesting result
if result is not None:
print(' > Model[%s] %.3f' % (key, result))
return (key, result)
Next, we need a loop to test a list of different model configurations.
This is the main function that drives the grid search process and will call the score_model() function for each model configuration.
We can dramatically speed up the grid search process by evaluating model configurations in parallel. One way to do that is to use the Joblib library.
We can define a Parallel object with the number of cores to use and set it to the number of CPU cores detected in your hardware.
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing')
We can then create a list of tasks to execute in parallel, which will be one call to the score_model() function for each model configuration we have.
tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
Finally, we can use the Parallel object to execute the list of tasks in parallel.
scores = executor(tasks)
That’s it.
We can also provide a non-parallel version of evaluating all model configurations in case we want to debug something.
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
The result of evaluating a list of configurations will be a list of tuples, each with a name that summarizes a specific model configuration and the error of the model evaluated with that configuration as either the RMSE or None if there was an error.
We can filter out all scores with a None.
scores = [r for r in scores if r[1] != None]
We can then sort all tuples in the list by the score in ascending order (best are first), then return this list of scores for review.
The grid_search() function below implements this behavior given a univariate time series dataset, a list of model configurations (list of lists), and the number of time steps to use in the test set. An optional parallel argument allows the evaluation of models across all cores to be tuned on or off, and is on by default.
# grid search configs def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # execute configs in parallel executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # remove empty results scores = [r for r in scores if r[1] != None] # sort configs by error, asc scores.sort(key=lambda tup: tup[1]) return scores
We’re nearly done.
The only thing left to do is to define a list of model configurations to try for a dataset.
We can define this generically. The only parameter we may want to specify is the periodicity of the seasonal component in the series, if one exists. By default, we will assume no seasonal component.
The exp_smoothing_configs() function below will create a list of model configurations to evaluate.
An optional list of seasonal periods can be specified, and you could even change the function to specify other elements that you may know about your time series.
In theory, there are 72 possible model configurations to evaluate, but in practice, many will not be valid and will result in an error that we will trap and ignore.
# create a set of exponential smoothing configs to try def exp_smoothing_configs(seasonal=[None]): models = list() # define config lists t_params = ['add', 'mul', None] d_params = [True, False] s_params = ['add', 'mul', None] p_params = seasonal b_params = [True, False] r_params = [True, False] # create config instances for t in t_params: for d in d_params: for s in s_params: for p in p_params: for b in b_params: for r in r_params: cfg = [t,d,s,p,b,r] models.append(cfg) return models
We now have a framework for grid searching triple exponential smoothing model hyperparameters via one-step walk-forward validation.
It is generic and will work for any in-memory univariate time series provided as a list or NumPy array.
We can make sure all the pieces work together by testing it on a contrived 10-step dataset.
The complete example is listed below.
# grid search holt winter's exponential smoothing
from math import sqrt
from multiprocessing import cpu_count
from joblib import Parallel
from joblib import delayed
from warnings import catch_warnings
from warnings import filterwarnings
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from sklearn.metrics import mean_squared_error
# one-step Holt Winter’s Exponential Smoothing forecast
def exp_smoothing_forecast(history, config):
t,d,s,p,b,r = config
# define model
model = ExponentialSmoothing(history, trend=t, damped=d, seasonal=s, seasonal_periods=p)
# fit model
model_fit = model.fit(optimized=True, use_boxcox=b, remove_bias=r)
# make one step forecast
yhat = model_fit.predict(len(history), len(history))
return yhat[0]
# root mean squared error or rmse
def measure_rmse(actual, predicted):
return sqrt(mean_squared_error(actual, predicted))
# split a univariate dataset into train/test sets
def train_test_split(data, n_test):
return data[:-n_test], data[-n_test:]
# walk-forward validation for univariate data
def walk_forward_validation(data, n_test, cfg):
predictions = list()
# split dataset
train, test = train_test_split(data, n_test)
# seed history with training dataset
history = [x for x in train]
# step over each time-step in the test set
for i in range(len(test)):
# fit model and make forecast for history
yhat = exp_smoothing_forecast(history, cfg)
# store forecast in list of predictions
predictions.append(yhat)
# add actual observation to history for the next loop
history.append(test[i])
# estimate prediction error
error = measure_rmse(test, predictions)
return error
# score a model, return None on failure
def score_model(data, n_test, cfg, debug=False):
result = None
# convert config to a key
key = str(cfg)
# show all warnings and fail on exception if debugging
if debug:
result = walk_forward_validation(data, n_test, cfg)
else:
# one failure during model validation suggests an unstable config
try:
# never show warnings when grid searching, too noisy
with catch_warnings():
filterwarnings("ignore")
result = walk_forward_validation(data, n_test, cfg)
except:
error = None
# check for an interesting result
if result is not None:
print(' > Model[%s] %.3f' % (key, result))
return (key, result)
# grid search configs
def grid_search(data, cfg_list, n_test, parallel=True):
scores = None
if parallel:
# execute configs in parallel
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing')
tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
scores = executor(tasks)
else:
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
# remove empty results
scores = [r for r in scores if r[1] != None]
# sort configs by error, asc
scores.sort(key=lambda tup: tup[1])
return scores
# create a set of exponential smoothing configs to try
def exp_smoothing_configs(seasonal=[None]):
models = list()
# define config lists
t_params = ['add', 'mul', None]
d_params = [True, False]
s_params = ['add', 'mul', None]
p_params = seasonal
b_params = [True, False]
r_params = [True, False]
# create config instances
for t in t_params:
for d in d_params:
for s in s_params:
for p in p_params:
for b in b_params:
for r in r_params:
cfg = [t,d,s,p,b,r]
models.append(cfg)
return models
if __name__ == '__main__':
# define dataset
data = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0]
print(data)
# data split
n_test = 4
# model configs
cfg_list = exp_smoothing_configs()
# grid search
scores = grid_search(data, cfg_list, n_test)
print('done')
# list top 3 configs
for cfg, error in scores[:3]:
print(cfg, error)
Running the example first prints the contrived time series dataset.
Next, the model configurations and their errors are reported as they are evaluated.
Finally, the configurations and the error for the top three configurations are reported.
[10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] > Model[[None, False, None, None, True, True]] 1.380 > Model[[None, False, None, None, True, False]] 10.000 > Model[[None, False, None, None, False, True]] 2.563 > Model[[None, False, None, None, False, False]] 10.000 done [None, False, None, None, True, True] 1.379824445857423 [None, False, None, None, False, True] 2.5628662672606612 [None, False, None, None, False, False] 10.0
We do not report the model parameters optimized by the model itself. It is assumed that you can achieve the same result again by specifying the broader hyperparameters and allow the library to find the same internal parameters.
You can access these internal parameters by refitting a standalone model with the same configuration and printing the contents of the ‘params‘ attribute on the model fit; for example:
print(model_fit.params)
Now that we have a robust framework for grid searching ETS model hyperparameters, let’s test it out on a suite of standard univariate time series datasets.
The datasets were chosen for demonstration purposes; I am not suggesting that an ETS model is the best approach for each dataset, and perhaps an SARIMA or something else would be more appropriate in some cases.
Case Study 1: No Trend or Seasonality
The ‘daily female births’ dataset summarizes the daily total female births in California, USA in 1959.
The dataset has no obvious trend or seasonal component.
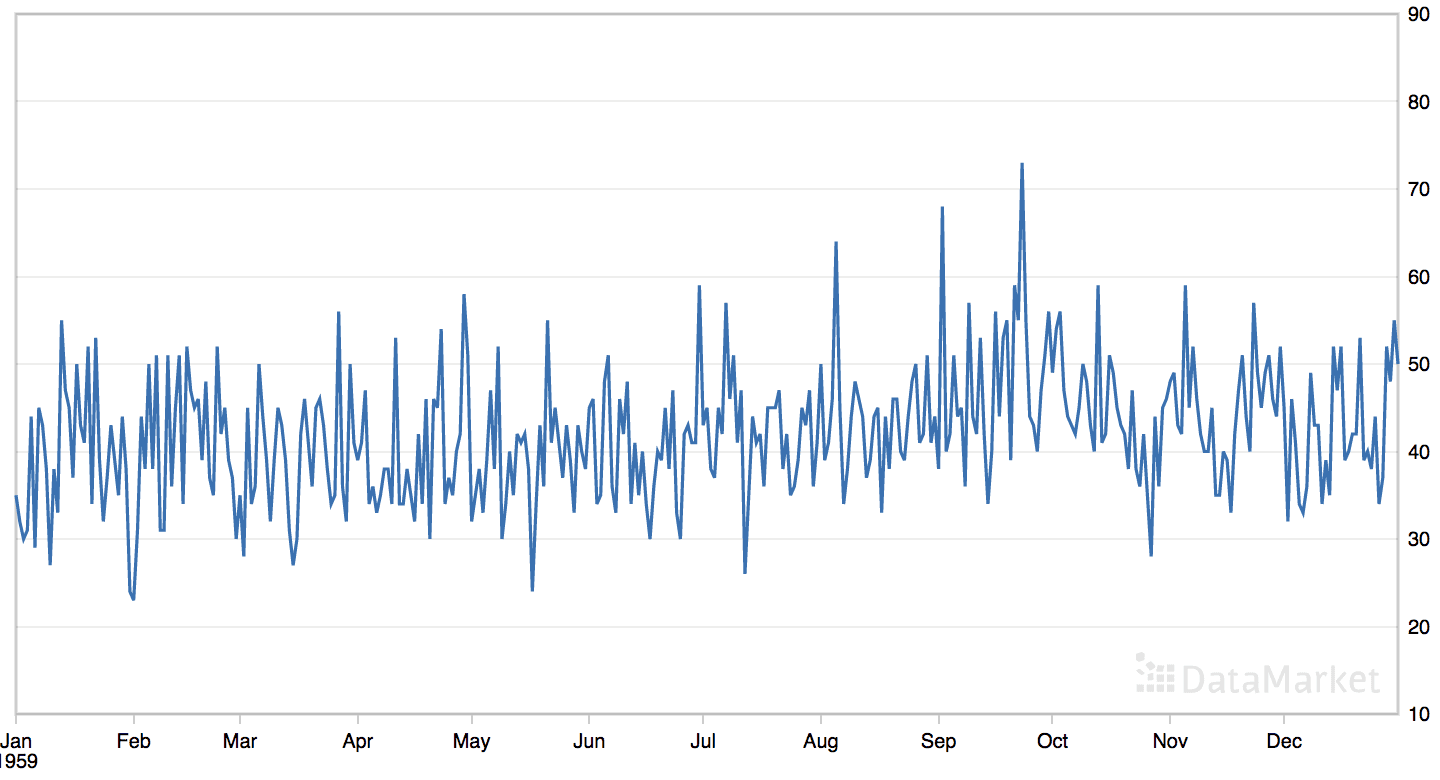
Line Plot of the Daily Female Births Dataset
You can learn more about the dataset from DataMarket.
Download the dataset directly from here:
Save the file with the filename ‘daily-total-female-births.csv‘ in your current working directory.
We can load this dataset as a Pandas series using the function read_csv().
series = read_csv('daily-total-female-births.csv', header=0, index_col=0)
The dataset has one year, or 365 observations. We will use the first 200 for training and the remaining 165 as the test set.
The complete example grid searching the daily female univariate time series forecasting problem is listed below.
# grid search ets models for daily female births
from math import sqrt
from multiprocessing import cpu_count
from joblib import Parallel
from joblib import delayed
from warnings import catch_warnings
from warnings import filterwarnings
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from sklearn.metrics import mean_squared_error
from pandas import read_csv
# one-step Holt Winter’s Exponential Smoothing forecast
def exp_smoothing_forecast(history, config):
t,d,s,p,b,r = config
# define model
model = ExponentialSmoothing(history, trend=t, damped=d, seasonal=s, seasonal_periods=p)
# fit model
model_fit = model.fit(optimized=True, use_boxcox=b, remove_bias=r)
# make one step forecast
yhat = model_fit.predict(len(history), len(history))
return yhat[0]
# root mean squared error or rmse
def measure_rmse(actual, predicted):
return sqrt(mean_squared_error(actual, predicted))
# split a univariate dataset into train/test sets
def train_test_split(data, n_test):
return data[:-n_test], data[-n_test:]
# walk-forward validation for univariate data
def walk_forward_validation(data, n_test, cfg):
predictions = list()
# split dataset
train, test = train_test_split(data, n_test)
# seed history with training dataset
history = [x for x in train]
# step over each time-step in the test set
for i in range(len(test)):
# fit model and make forecast for history
yhat = exp_smoothing_forecast(history, cfg)
# store forecast in list of predictions
predictions.append(yhat)
# add actual observation to history for the next loop
history.append(test[i])
# estimate prediction error
error = measure_rmse(test, predictions)
return error
# score a model, return None on failure
def score_model(data, n_test, cfg, debug=False):
result = None
# convert config to a key
key = str(cfg)
# show all warnings and fail on exception if debugging
if debug:
result = walk_forward_validation(data, n_test, cfg)
else:
# one failure during model validation suggests an unstable config
try:
# never show warnings when grid searching, too noisy
with catch_warnings():
filterwarnings("ignore")
result = walk_forward_validation(data, n_test, cfg)
except:
error = None
# check for an interesting result
if result is not None:
print(' > Model[%s] %.3f' % (key, result))
return (key, result)
# grid search configs
def grid_search(data, cfg_list, n_test, parallel=True):
scores = None
if parallel:
# execute configs in parallel
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing')
tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
scores = executor(tasks)
else:
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
# remove empty results
scores = [r for r in scores if r[1] != None]
# sort configs by error, asc
scores.sort(key=lambda tup: tup[1])
return scores
# create a set of exponential smoothing configs to try
def exp_smoothing_configs(seasonal=[None]):
models = list()
# define config lists
t_params = ['add', 'mul', None]
d_params = [True, False]
s_params = ['add', 'mul', None]
p_params = seasonal
b_params = [True, False]
r_params = [True, False]
# create config instances
for t in t_params:
for d in d_params:
for s in s_params:
for p in p_params:
for b in b_params:
for r in r_params:
cfg = [t,d,s,p,b,r]
models.append(cfg)
return models
if __name__ == '__main__':
# load dataset
series = read_csv('daily-total-female-births.csv', header=0, index_col=0)
data = series.values
print(data.shape)
# data split
n_test = 165
# model configs
cfg_list = exp_smoothing_configs()
# grid search
scores = grid_search(data, cfg_list, n_test)
print('done')
# list top 3 configs
for cfg, error in scores[:3]:
print(cfg, error)
Running the example may take a few minutes as fitting each ETS model can take about a minute on modern hardware.
Model configurations and the RMSE are printed as the models are evaluated The top three model configurations and their error are reported at the end of the run.
We can see that the best result was an RMSE of about 7.08 births with the following configuration:
- Trend: Additive
- Damped: False
- Seasonal: None
- Seasonal Periods: None
- Box-Cox Transform: True
- Remove Bias: True
What is surprising is that a model that assumed an additive trend performed better than one that didn’t.
We would not know that this is the case unless we threw out assumptions and grid searched models.
(365, 1) > Model[['add', False, None, None, True, True]] 7.081 > Model[['add', False, None, None, True, False]] 7.113 > Model[['add', False, None, None, False, True]] 7.112 > Model[['add', False, None, None, False, False]] 7.115 > Model[[None, False, None, None, True, True]] 7.169 > Model[[None, False, None, None, True, False]] 7.212 > Model[[None, False, None, None, False, True]] 7.117 > Model[[None, False, None, None, False, False]] 7.126 > Model[['add', True, None, None, True, False]] 7.170 > Model[['add', True, None, None, True, True]] 7.118 > Model[['add', True, None, None, False, True]] 7.113 > Model[['add', True, None, None, False, False]] 7.126 done ['add', False, None, None, True, True] 7.081359856193836 ['add', False, None, None, False, True] 7.111893396203345 ['add', True, None, None, False, True] 7.112743603181863
Case Study 2: Trend
The ‘shampoo’ dataset summarizes the monthly sales of shampoo over a three-year period.
The dataset contains an obvious trend but no obvious seasonal component.
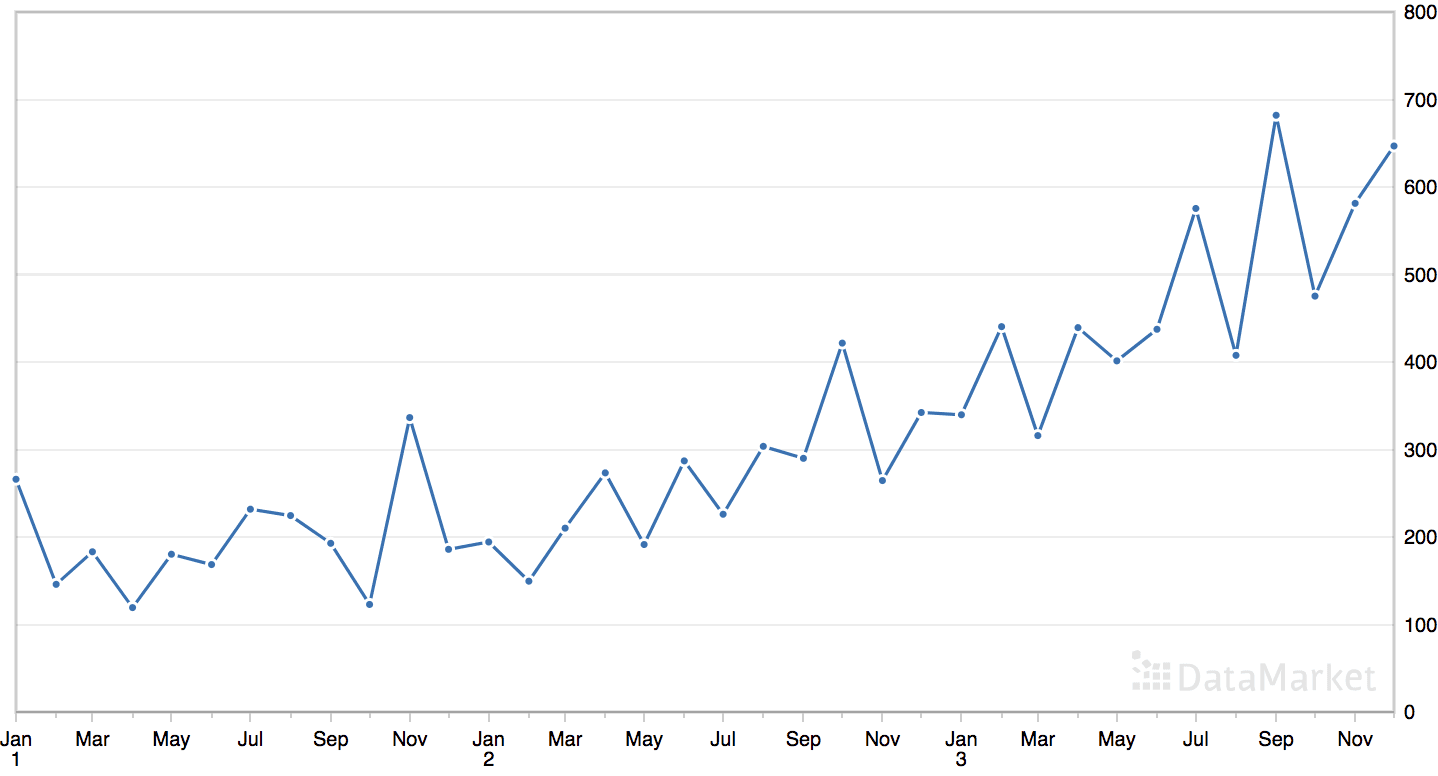
Line Plot of the Monthly Shampoo Sales Dataset
You can learn more about the dataset from DataMarket.
Download the dataset directly from here:
Save the file with the filename ‘shampoo.csv’ in your current working directory.
We can load this dataset as a Pandas series using the function read_csv().
# parse dates
def custom_parser(x):
return datetime.strptime('195'+x, '%Y-%m')
# load dataset
series = read_csv('shampoo.csv', header=0, index_col=0, date_parser=custom_parser)
The dataset has three years, or 36 observations. We will use the first 24 for training and the remaining 12 as the test set.
The complete example grid searching the shampoo sales univariate time series forecasting problem is listed below.
# grid search ets models for monthly shampoo sales
from math import sqrt
from multiprocessing import cpu_count
from joblib import Parallel
from joblib import delayed
from warnings import catch_warnings
from warnings import filterwarnings
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from sklearn.metrics import mean_squared_error
from pandas import read_csv
from pandas import datetime
# one-step Holt Winter’s Exponential Smoothing forecast
def exp_smoothing_forecast(history, config):
t,d,s,p,b,r = config
# define model
model = ExponentialSmoothing(history, trend=t, damped=d, seasonal=s, seasonal_periods=p)
# fit model
model_fit = model.fit(optimized=True, use_boxcox=b, remove_bias=r)
# make one step forecast
yhat = model_fit.predict(len(history), len(history))
return yhat[0]
# root mean squared error or rmse
def measure_rmse(actual, predicted):
return sqrt(mean_squared_error(actual, predicted))
# split a univariate dataset into train/test sets
def train_test_split(data, n_test):
return data[:-n_test], data[-n_test:]
# walk-forward validation for univariate data
def walk_forward_validation(data, n_test, cfg):
predictions = list()
# split dataset
train, test = train_test_split(data, n_test)
# seed history with training dataset
history = [x for x in train]
# step over each time-step in the test set
for i in range(len(test)):
# fit model and make forecast for history
yhat = exp_smoothing_forecast(history, cfg)
# store forecast in list of predictions
predictions.append(yhat)
# add actual observation to history for the next loop
history.append(test[i])
# estimate prediction error
error = measure_rmse(test, predictions)
return error
# score a model, return None on failure
def score_model(data, n_test, cfg, debug=False):
result = None
# convert config to a key
key = str(cfg)
# show all warnings and fail on exception if debugging
if debug:
result = walk_forward_validation(data, n_test, cfg)
else:
# one failure during model validation suggests an unstable config
try:
# never show warnings when grid searching, too noisy
with catch_warnings():
filterwarnings("ignore")
result = walk_forward_validation(data, n_test, cfg)
except:
error = None
# check for an interesting result
if result is not None:
print(' > Model[%s] %.3f' % (key, result))
return (key, result)
# grid search configs
def grid_search(data, cfg_list, n_test, parallel=True):
scores = None
if parallel:
# execute configs in parallel
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing')
tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
scores = executor(tasks)
else:
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
# remove empty results
scores = [r for r in scores if r[1] != None]
# sort configs by error, asc
scores.sort(key=lambda tup: tup[1])
return scores
# create a set of exponential smoothing configs to try
def exp_smoothing_configs(seasonal=[None]):
models = list()
# define config lists
t_params = ['add', 'mul', None]
d_params = [True, False]
s_params = ['add', 'mul', None]
p_params = seasonal
b_params = [True, False]
r_params = [True, False]
# create config instances
for t in t_params:
for d in d_params:
for s in s_params:
for p in p_params:
for b in b_params:
for r in r_params:
cfg = [t,d,s,p,b,r]
models.append(cfg)
return models
# parse dates
def custom_parser(x):
return datetime.strptime('195'+x, '%Y-%m')
if __name__ == '__main__':
# load dataset
series = read_csv('shampoo.csv', header=0, index_col=0, date_parser=custom_parser)
data = series.values
print(data.shape)
# data split
n_test = 12
# model configs
cfg_list = exp_smoothing_configs()
# grid search
scores = grid_search(data, cfg_list, n_test)
print('done')
# list top 3 configs
for cfg, error in scores[:3]:
print(cfg, error)
Running the example is fast given there are a small number of observations.
Model configurations and the RMSE are printed as the models are evaluated. The top three model configurations and their error are reported at the end of the run.
We can see that the best result was an RMSE of about 97.91 sales with the following configuration:
- Trend: Additive
- Damped: False
- Seasonal: None
- Seasonal Periods: None
- Box-Cox Transform: False
- Remove Bias: True
(36, 1) > Model[['add', False, None, None, False, True]] 106.431 > Model[['add', False, None, None, False, False]] 104.874 > Model[[None, False, None, None, False, True]] 99.416 > Model[[None, False, None, None, False, False]] 108.031 > Model[['add', True, None, None, False, True]] 97.918 > Model[['add', True, None, None, False, False]] 103.069 done ['add', True, None, None, False, True] 97.91815887268478 [None, False, None, None, False, True] 99.41551161747742 ['add', True, None, None, False, False] 103.06878140174923
Case Study 3: Seasonality
The ‘monthly mean temperatures’ dataset summarizes the monthly average air temperatures in Nottingham Castle, England from 1920 to 1939 in degrees Fahrenheit.
The dataset has an obvious seasonal component and no obvious trend.
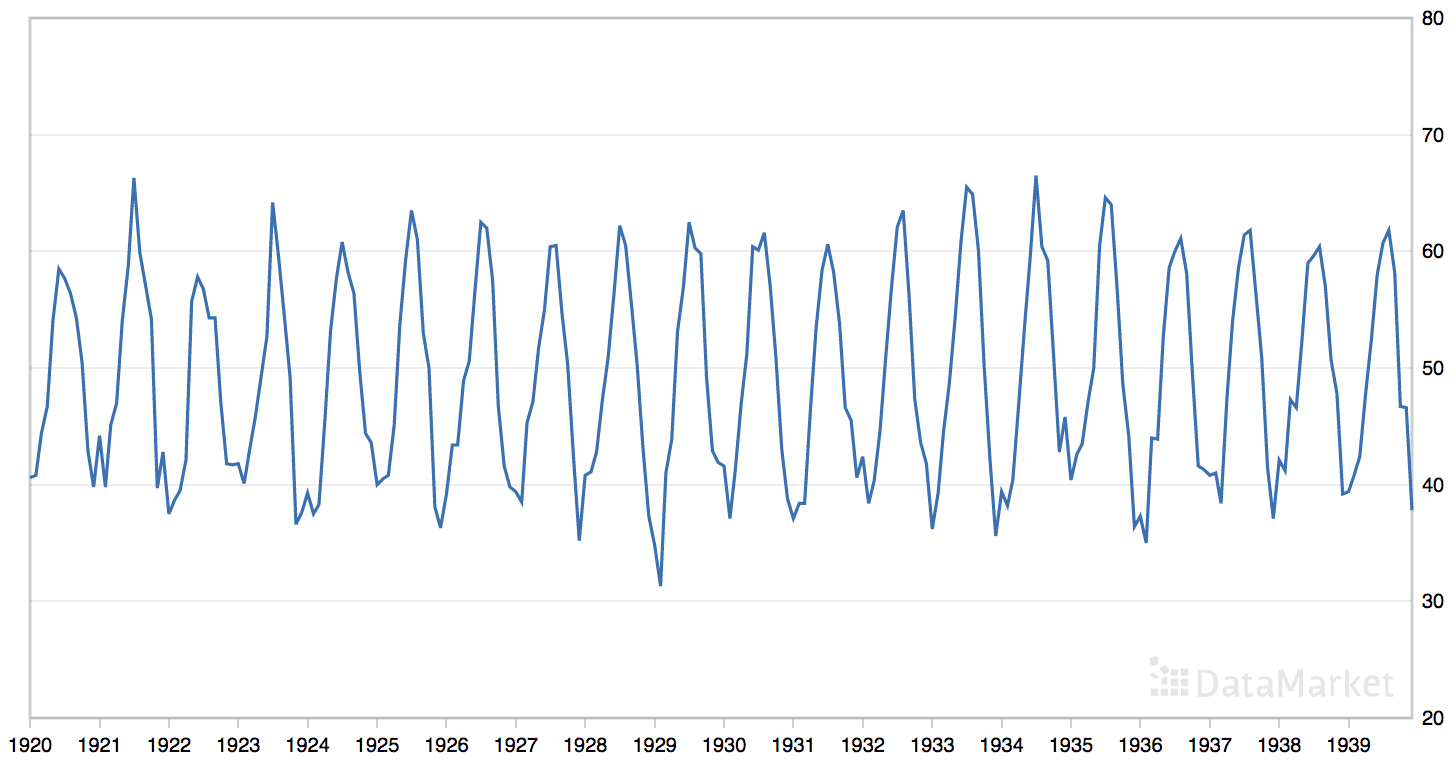
Line Plot of the Monthly Mean Temperatures Dataset
You can learn more about the dataset from DataMarket.
Download the dataset directly from here:
Save the file with the filename ‘monthly-mean-temp.csv’ in your current working directory.
We can load this dataset as a Pandas series using the function read_csv().
series = read_csv('monthly-mean-temp.csv', header=0, index_col=0)
The dataset has 20 years, or 240 observations.
We will trim the dataset to the last five years of data (60 observations) in order to speed up the model evaluation process and use the last year, or 12 observations, for the test set.
# trim dataset to 5 years data = data[-(5*12):]
The period of the seasonal component is about one year, or 12 observations.
We will use this as the seasonal period in the call to the exp_smoothing_configs() function when preparing the model configurations.
# model configs cfg_list = exp_smoothing_configs(seasonal=[0, 12])
The complete example grid searching the monthly mean temperature time series forecasting problem is listed below.
# grid search ets hyperparameters for monthly mean temp dataset
from math import sqrt
from multiprocessing import cpu_count
from joblib import Parallel
from joblib import delayed
from warnings import catch_warnings
from warnings import filterwarnings
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from sklearn.metrics import mean_squared_error
from pandas import read_csv
# one-step Holt Winter’s Exponential Smoothing forecast
def exp_smoothing_forecast(history, config):
t,d,s,p,b,r = config
# define model
model = ExponentialSmoothing(history, trend=t, damped=d, seasonal=s, seasonal_periods=p)
# fit model
model_fit = model.fit(optimized=True, use_boxcox=b, remove_bias=r)
# make one step forecast
yhat = model_fit.predict(len(history), len(history))
return yhat[0]
# root mean squared error or rmse
def measure_rmse(actual, predicted):
return sqrt(mean_squared_error(actual, predicted))
# split a univariate dataset into train/test sets
def train_test_split(data, n_test):
return data[:-n_test], data[-n_test:]
# walk-forward validation for univariate data
def walk_forward_validation(data, n_test, cfg):
predictions = list()
# split dataset
train, test = train_test_split(data, n_test)
# seed history with training dataset
history = [x for x in train]
# step over each time-step in the test set
for i in range(len(test)):
# fit model and make forecast for history
yhat = exp_smoothing_forecast(history, cfg)
# store forecast in list of predictions
predictions.append(yhat)
# add actual observation to history for the next loop
history.append(test[i])
# estimate prediction error
error = measure_rmse(test, predictions)
return error
# score a model, return None on failure
def score_model(data, n_test, cfg, debug=False):
result = None
# convert config to a key
key = str(cfg)
# show all warnings and fail on exception if debugging
if debug:
result = walk_forward_validation(data, n_test, cfg)
else:
# one failure during model validation suggests an unstable config
try:
# never show warnings when grid searching, too noisy
with catch_warnings():
filterwarnings("ignore")
result = walk_forward_validation(data, n_test, cfg)
except:
error = None
# check for an interesting result
if result is not None:
print(' > Model[%s] %.3f' % (key, result))
return (key, result)
# grid search configs
def grid_search(data, cfg_list, n_test, parallel=True):
scores = None
if parallel:
# execute configs in parallel
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing')
tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
scores = executor(tasks)
else:
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
# remove empty results
scores = [r for r in scores if r[1] != None]
# sort configs by error, asc
scores.sort(key=lambda tup: tup[1])
return scores
# create a set of exponential smoothing configs to try
def exp_smoothing_configs(seasonal=[None]):
models = list()
# define config lists
t_params = ['add', 'mul', None]
d_params = [True, False]
s_params = ['add', 'mul', None]
p_params = seasonal
b_params = [True, False]
r_params = [True, False]
# create config instances
for t in t_params:
for d in d_params:
for s in s_params:
for p in p_params:
for b in b_params:
for r in r_params:
cfg = [t,d,s,p,b,r]
models.append(cfg)
return models
if __name__ == '__main__':
# load dataset
series = read_csv('monthly-mean-temp.csv', header=0, index_col=0)
data = series.values
# trim dataset to 5 years
data = data[-(5*12):]
print(data.shape)
# data split
n_test = 12
# model configs
cfg_list = exp_smoothing_configs(seasonal=[12])
# grid search
scores = grid_search(data, cfg_list, n_test)
print('done')
# list top 3 configs
for cfg, error in scores[:3]:
print(cfg, error)
Running the example is relatively slow given the large amount of data.
Model configurations and the RMSE are printed as the models are evaluated. The top three model configurations and their error are reported at the end of the run.
We can see that the best result was an RMSE of about 1.50 degrees with the following configuration:
- Trend: None
- Damped: False
- Seasonal: Additive
- Seasonal Periods: 12
- Box-Cox Transform: False
- Remove Bias: False
(60, 1) > Model[['add', True, None, 12, True, True]] 4.654 > Model[['add', True, None, 12, True, False]] 4.597 > Model[['add', True, None, 12, False, True]] 4.800 > Model[['add', True, None, 12, False, False]] 4.760 > Model[['add', False, 'add', 12, True, False]] 1.826 > Model[['add', False, 'add', 12, True, True]] 1.860 > Model[['add', False, None, 12, True, True]] 4.980 > Model[['add', False, 'add', 12, False, True]] 1.707 > Model[['add', False, 'add', 12, False, False]] 1.683 > Model[['add', False, None, 12, True, False]] 4.900 > Model[['add', False, None, 12, False, True]] 5.203 > Model[['add', False, None, 12, False, False]] 5.151 > Model[[None, False, 'add', 12, True, True]] 1.508 > Model[[None, False, 'add', 12, True, False]] 1.507 > Model[[None, False, 'add', 12, False, True]] 1.502 > Model[[None, False, 'add', 12, False, False]] 1.502 > Model[[None, False, None, 12, True, True]] 5.188 > Model[[None, False, None, 12, True, False]] 5.143 > Model[[None, False, None, 12, False, True]] 5.187 > Model[[None, False, None, 12, False, False]] 5.143 > Model[['add', True, 'add', 12, True, False]] 1.638 > Model[['add', True, 'add', 12, False, True]] 1.568 > Model[['add', True, 'add', 12, False, False]] 1.555 > Model[['add', True, 'add', 12, True, True]] 1.646 done [None, False, 'add', 12, False, False] 1.5015471290238562 [None, False, 'add', 12, False, True] 1.5015526638829775 [None, False, 'add', 12, True, False] 1.5072252073652794
Case Study 4: Trend and Seasonality
The ‘monthly car sales’ dataset summarizes the monthly car sales in Quebec, Canada between 1960 and 1968.
The dataset has an obvious trend and seasonal component.
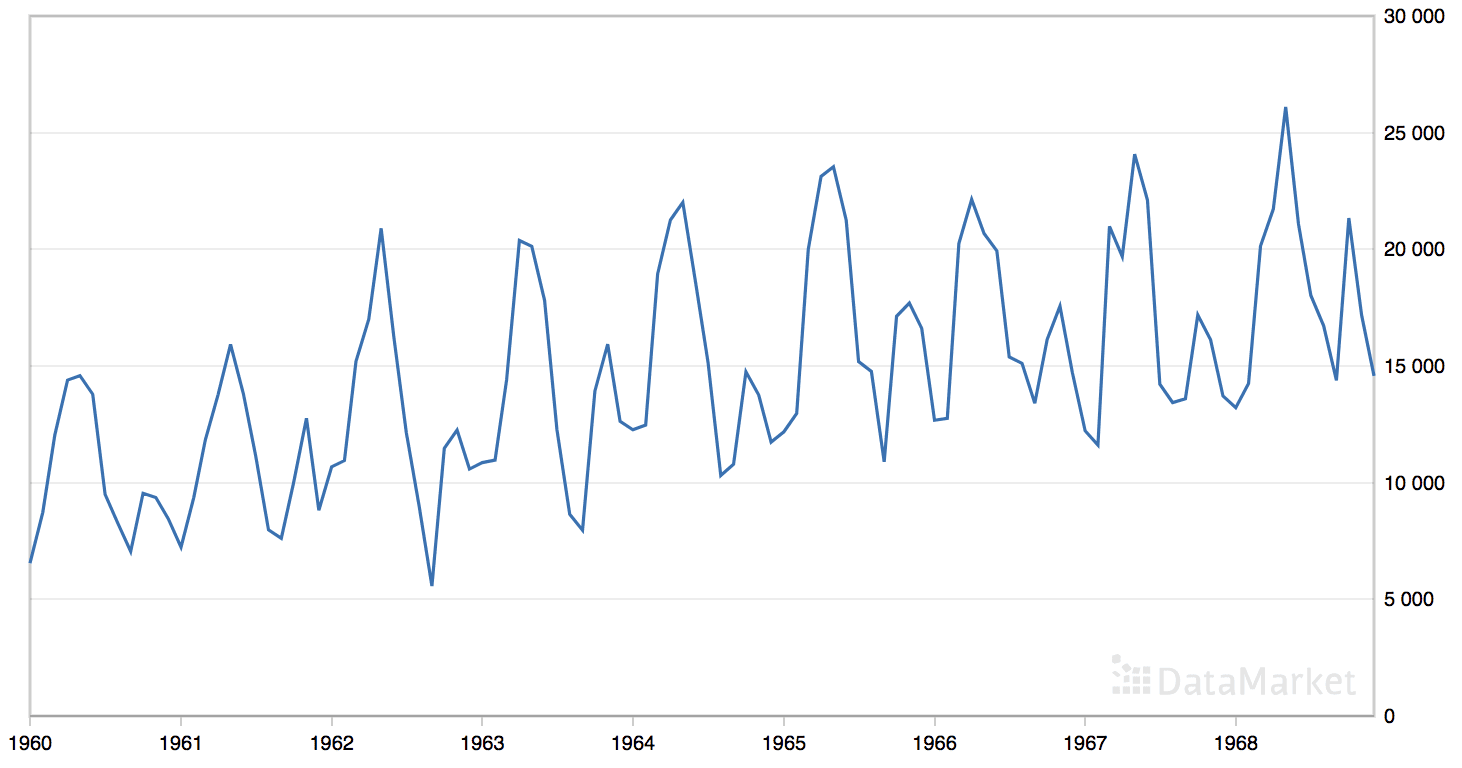
Line Plot of the Monthly Car Sales Dataset
You can learn more about the dataset from DataMarket.
Download the dataset directly from here:
Save the file with the filename ‘monthly-car-sales.csv’ in your current working directory.
We can load this dataset as a Pandas series using the function read_csv().
series = read_csv('monthly-car-sales.csv', header=0, index_col=0)
The dataset has nine years, or 108 observations. We will use the last year, or 12 observations, as the test set.
The period of the seasonal component could be six months or 12 months. We will try both as the seasonal period in the call to the exp_smoothing_configs() function when preparing the model configurations.
# model configs cfg_list = exp_smoothing_configs(seasonal=[6,12])
The complete example grid searching the monthly car sales time series forecasting problem is listed below.
# grid search ets models for monthly car sales
from math import sqrt
from multiprocessing import cpu_count
from joblib import Parallel
from joblib import delayed
from warnings import catch_warnings
from warnings import filterwarnings
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from sklearn.metrics import mean_squared_error
from pandas import read_csv
from pandas import datetime
# one-step Holt Winter’s Exponential Smoothing forecast
def exp_smoothing_forecast(history, config):
t,d,s,p,b,r = config
# define model
model = ExponentialSmoothing(history, trend=t, damped=d, seasonal=s, seasonal_periods=p)
# fit model
model_fit = model.fit(optimized=True, use_boxcox=b, remove_bias=r)
# make one step forecast
yhat = model_fit.predict(len(history), len(history))
return yhat[0]
# root mean squared error or rmse
def measure_rmse(actual, predicted):
return sqrt(mean_squared_error(actual, predicted))
# split a univariate dataset into train/test sets
def train_test_split(data, n_test):
return data[:-n_test], data[-n_test:]
# walk-forward validation for univariate data
def walk_forward_validation(data, n_test, cfg):
predictions = list()
# split dataset
train, test = train_test_split(data, n_test)
# seed history with training dataset
history = [x for x in train]
# step over each time-step in the test set
for i in range(len(test)):
# fit model and make forecast for history
yhat = exp_smoothing_forecast(history, cfg)
# store forecast in list of predictions
predictions.append(yhat)
# add actual observation to history for the next loop
history.append(test[i])
# estimate prediction error
error = measure_rmse(test, predictions)
return error
# score a model, return None on failure
def score_model(data, n_test, cfg, debug=False):
result = None
# convert config to a key
key = str(cfg)
# show all warnings and fail on exception if debugging
if debug:
result = walk_forward_validation(data, n_test, cfg)
else:
# one failure during model validation suggests an unstable config
try:
# never show warnings when grid searching, too noisy
with catch_warnings():
filterwarnings("ignore")
result = walk_forward_validation(data, n_test, cfg)
except:
error = None
# check for an interesting result
if result is not None:
print(' > Model[%s] %.3f' % (key, result))
return (key, result)
# grid search configs
def grid_search(data, cfg_list, n_test, parallel=True):
scores = None
if parallel:
# execute configs in parallel
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing')
tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
scores = executor(tasks)
else:
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
# remove empty results
scores = [r for r in scores if r[1] != None]
# sort configs by error, asc
scores.sort(key=lambda tup: tup[1])
return scores
# create a set of exponential smoothing configs to try
def exp_smoothing_configs(seasonal=[None]):
models = list()
# define config lists
t_params = ['add', 'mul', None]
d_params = [True, False]
s_params = ['add', 'mul', None]
p_params = seasonal
b_params = [True, False]
r_params = [True, False]
# create config instances
for t in t_params:
for d in d_params:
for s in s_params:
for p in p_params:
for b in b_params:
for r in r_params:
cfg = [t,d,s,p,b,r]
models.append(cfg)
return models
if __name__ == '__main__':
# load dataset
series = read_csv('monthly-car-sales.csv', header=0, index_col=0)
data = series.values
print(data.shape)
# data split
n_test = 12
# model configs
cfg_list = exp_smoothing_configs(seasonal=[6,12])
# grid search
scores = grid_search(data, cfg_list, n_test)
print('done')
# list top 3 configs
for cfg, error in scores[:3]:
print(cfg, error)
Running the example is slow given the large amount of data.
Model configurations and the RMSE are printed as the models are evaluated. The top three model configurations and their error are reported at the end of the run.
We can see that the best result was an RMSE of about 1,658 sales with the following configuration:
- Trend: Additive
- Damped: True
- Seasonal: Additive
- Seasonal Periods: 12
- Box-Cox Transform: False
- Remove Bias: True
This is a little surprising as I would have guessed that a six-month seasonal model would be the preferred approach.
(108, 1) > Model[['add', True, 'add', 6, False, True]] 3240.433 > Model[['add', True, 'add', 6, False, False]] 3226.384 > Model[['add', True, 'add', 6, True, False]] 2823.588 > Model[['add', True, 'add', 6, True, True]] 2810.103 > Model[['add', True, 'add', 12, False, False]] 1684.424 > Model[['add', True, 'add', 12, False, True]] 1658.925 > Model[['add', True, None, 6, True, True]] 3933.443 > Model[['add', True, None, 6, True, False]] 3915.510 > Model[['add', True, None, 6, False, True]] 3924.489 > Model[['add', True, None, 6, False, False]] 3905.487 > Model[['add', True, None, 12, True, True]] 3935.659 > Model[['add', True, None, 12, True, False]] 3915.499 > Model[['add', True, 'add', 12, True, False]] 2067.595 > Model[['add', True, 'add', 12, True, True]] 2095.083 > Model[['add', False, 'add', 6, True, True]] 3220.532 > Model[['add', False, 'add', 6, True, False]] 3199.766 > Model[['add', True, None, 12, False, True]] 3934.066 > Model[['add', True, None, 12, False, False]] 3905.367 > Model[['add', False, None, 6, True, True]] 3815.765 > Model[['add', False, None, 6, True, False]] 3813.234 > Model[['add', False, None, 6, False, True]] 3805.651 > Model[['add', False, 'add', 6, False, True]] 3243.478 > Model[['add', False, None, 6, False, False]] 3813.920 > Model[['add', False, None, 12, True, True]] 3815.765 > Model[['add', False, 'add', 6, False, False]] 3226.955 > Model[['add', False, None, 12, True, False]] 3813.234 > Model[['add', False, None, 12, False, True]] 3805.700 > Model[['add', False, None, 12, False, False]] 3809.819 > Model[['add', False, 'add', 12, False, True]] 1675.977 > Model[[None, False, 'add', 6, True, True]] 3204.875 > Model[['add', False, 'add', 12, False, False]] 1733.999 > Model[['add', False, 'add', 12, True, True]] 1833.418 > Model[['add', False, 'add', 12, True, False]] 1833.608 > Model[[None, False, 'add', 6, True, False]] 3190.972 > Model[[None, False, 'add', 6, False, True]] 3147.644 > Model[[None, False, 'add', 6, False, False]] 3049.932 > Model[[None, False, 'add', 12, True, True]] 1834.905 > Model[[None, False, 'add', 12, True, False]] 1872.182 > Model[[None, False, 'add', 12, False, True]] 1751.538 > Model[[None, False, 'add', 12, False, False]] 1800.867 > Model[[None, False, None, 6, True, True]] 3801.741 > Model[[None, False, None, 6, True, False]] 3783.966 > Model[[None, False, None, 6, False, True]] 3801.560 > Model[[None, False, None, 6, False, False]] 3783.966 > Model[[None, False, None, 12, True, True]] 3801.741 > Model[[None, False, None, 12, True, False]] 3783.966 > Model[[None, False, None, 12, False, True]] 3801.560 > Model[[None, False, None, 12, False, False]] 3783.966 done ['add', True, 'add', 12, False, True] 1658.9253551827699 ['add', False, 'add', 12, False, True] 1675.9766454275066 ['add', True, 'add', 12, False, False] 1684.4244861443897
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Data Transforms. Update the framework to support configurable data transforms such as normalization and standardization.
- Plot Forecast. Update the framework to re-fit a model with the best configuration and forecast the entire test dataset, then plot the forecast compared to the actual observations in the test set.
- Tune Amount of History. Update the framework to tune the amount of historical data used to fit the model (e.g. in the case of the 10 years of max temperature data).
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Chapter 7 Exponential smoothing, Forecasting: principles and practice, 2013.
- Section 6.4. Introduction to Time Series Analysis, Engineering Statistics Handbook, 2012.
- Practical Time Series Forecasting with R, 2016.
APIs
- statsmodels.tsa.holtwinters.ExponentialSmoothing API
- statsmodels.tsa.holtwinters.HoltWintersResults API
- Joblib: running Python functions as pipeline jobs
Articles
Summary
In this tutorial, you discovered how to develop a framework for grid searching all of the exponential smoothing model hyperparameters for univariate time series forecasting.
Specifically, you learned:
- How to develop a framework for grid searching ETS models from scratch using walk-forward validation.
- How to grid search ETS model hyperparameters for daily time series data for births.
- How to grid search ETS model hyperparameters for monthly time series data for shampoo sales, car sales and temperature.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Grid Search Triple Exponential Smoothing for Time Series Forecasting in Python appeared first on Machine Learning Mastery.