
Author: Jason Brownlee
Model averaging is an ensemble technique where multiple sub-models contribute equally to a combined prediction.
Model averaging can be improved by weighting the contributions of each sub-model to the combined prediction by the expected performance of the submodel. This can be extended further by training an entirely new model to learn how to best combine the contributions from each submodel. This approach is called stacked generalization, or stacking for short, and can result in better predictive performance than any single contributing model.
In this tutorial, you will discover how to develop a stacked generalization ensemble for deep learning neural networks.
After completing this tutorial, you will know:
- Stacked generalization is an ensemble method where a new model learns how to best combine the predictions from multiple existing models.
- How to develop a stacking model using neural networks as a submodel and a scikit-learn classifier as the meta-learner.
- How to develop a stacking model where neural network sub-models are embedded in a larger stacking ensemble model for training and prediction.
Let’s get started.

How to Develop a Stacking Ensemble for Deep Learning Neural Networks in Python With Keras
Photo by David Law, some rights reserved.
Tutorial Overview
This tutorial is divided into six parts; they are:
- Stacked Generalization Ensemble
- Multi-Class Classification Problem
- Multilayer Perceptron Model
- Train and Save Sub-Models
- Separate Stacking Model
- Integrated Stacking Model
Stacked Generalization Ensemble
A model averaging ensemble combines the predictions from multiple trained models.
A limitation of this approach is that each model contributes the same amount to the ensemble prediction, regardless of how well the model performed. A variation of this approach, called a weighted average ensemble, weighs the contribution of each ensemble member by the trust or expected performance of the model on a holdout dataset. This allows well-performing models to contribute more and less-well-performing models to contribute less. The weighted average ensemble provides an improvement over the model average ensemble.
A further generalization of this approach is replacing the linear weighted sum (e.g. linear regression) model used to combine the predictions of the sub-models with any learning algorithm. This approach is called stacked generalization, or stacking for short.
In stacking, an algorithm takes the outputs of sub-models as input and attempts to learn how to best combine the input predictions to make a better output prediction.
It may be helpful to think of the stacking procedure as having two levels: level 0 and level 1.
- Level 0: The level 0 data is the training dataset inputs and level 0 models learn to make predictions from this data.
- Level 1: The level 1 data takes the output of the level 0 models as input and the single level 1 model, or meta-learner, learns to make predictions from this data.
Stacked generalization works by deducing the biases of the generalizer(s) with respect to a provided learning set. This deduction proceeds by generalizing in a second space whose inputs are (for example) the guesses of the original generalizers when taught with part of the learning set and trying to guess the rest of it, and whose output is (for example) the correct guess.
— Stacked generalization, 1992.
Unlike a weighted average ensemble, a stacked generalization ensemble can use the set of predictions as a context and conditionally decide to weigh the input predictions differently, potentially resulting in better performance.
Interestingly, although stacking is described as an ensemble learning method with two or more level 0 models, it can be used in the case where there is only a single level 0 model. In this case, the level 1, or meta-learner, model learns to correct the predictions from the level 0 model.
… although it can also be used when one has only a single generalizer, as a technique to improve that single generalizer
— Stacked generalization, 1992.
It is important that the meta-learner is trained on a separate dataset to the examples used to train the level 0 models to avoid overfitting.
A simple way that this can be achieved is by splitting the training dataset into a train and validation set. The level 0 models are then trained on the train set. The level 1 model is then trained using the validation set, where the raw inputs are first fed through the level 0 models to get predictions that are used as inputs to the level 1 model.
A limitation of the hold-out validation set approach to training a stacking model is that level 0 and level 1 models are not trained on the full dataset.
A more sophisticated approach to training a stacked model involves using k-fold cross-validation to develop the training dataset for the meta-learner model. Each level 0 model is trained using k-fold cross-validation (or even leave-one-out cross-validation for maximum effect); the models are then discarded, but the predictions are retained. This means for each model, there are predictions made by a version of the model that was not trained on those examples, e.g. like having holdout examples, but in this case for the entire training dataset.
The predictions are then used as inputs to train the meta-learner. Level 0 models are then trained on the entire training dataset and together with the meta-learner, the stacked model can be used to make predictions on new data.
In practice, it is common to use different algorithms to prepare each of the level 0 models, to provide a diverse set of predictions.
… stacking is not normally used to combine models of the same type […] it is applied to models built by different learning algorithms.
— Practical Machine Learning Tools and Techniques, Second Edition, 2005.
It is also common to use a simple linear model to combine the predictions. Because use of a linear model is common, stacking is more recently referred to as “model blending” or simply “blending,” especially in machine learning competitions.
… the multi-response least squares linear regression technique should be employed as the high-level generalizer. This technique provides a method of combining level-0 models’ confidence
— Issues in Stacked Generalization, 1999.
A stacked generalization ensemble can be developed for regression and classification problems. In the case of classification problems, better results have been seen when using the prediction of class probabilities as input to the meta-learner instead of class labels.
… class probabilities should be used instead of the single predicted class as input attributes for higher-level learning. The class probabilities serve as the confidence measure for the prediction made.
— Issues in Stacked Generalization, 1999.
Now that we are familiar with stacked generalization, we can work through a case study of developing a stacked deep learning model.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Multi-Class Classification Problem
We will use a small multi-class classification problem as the basis to demonstrate the stacking ensemble.
The scikit-learn class provides the make_blobs() function that can be used to create a multi-class classification problem with the prescribed number of samples, input variables, classes, and variance of samples within a class.
The problem has two input variables (to represent the x and y coordinates of the points) and a standard deviation of 2.0 for points within each group. We will use the same random state (seed for the pseudorandom number generator) to ensure that we always get the same data points.
# generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
The results are the input and output elements of a dataset that we can model.
In order to get a feeling for the complexity of the problem, we can graph each point on a two-dimensional scatter plot and color each point by class value.
The complete example is listed below.
# scatter plot of blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue', 2:'green'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()
Running the example creates a scatter plot of the entire dataset. We can see that the standard deviation of 2.0 means that the classes are not linearly separable (separable by a line) causing many ambiguous points.
This is desirable as it means that the problem is non-trivial and will allow a neural network model to find many different “good enough” candidate solutions, resulting in a high variance.
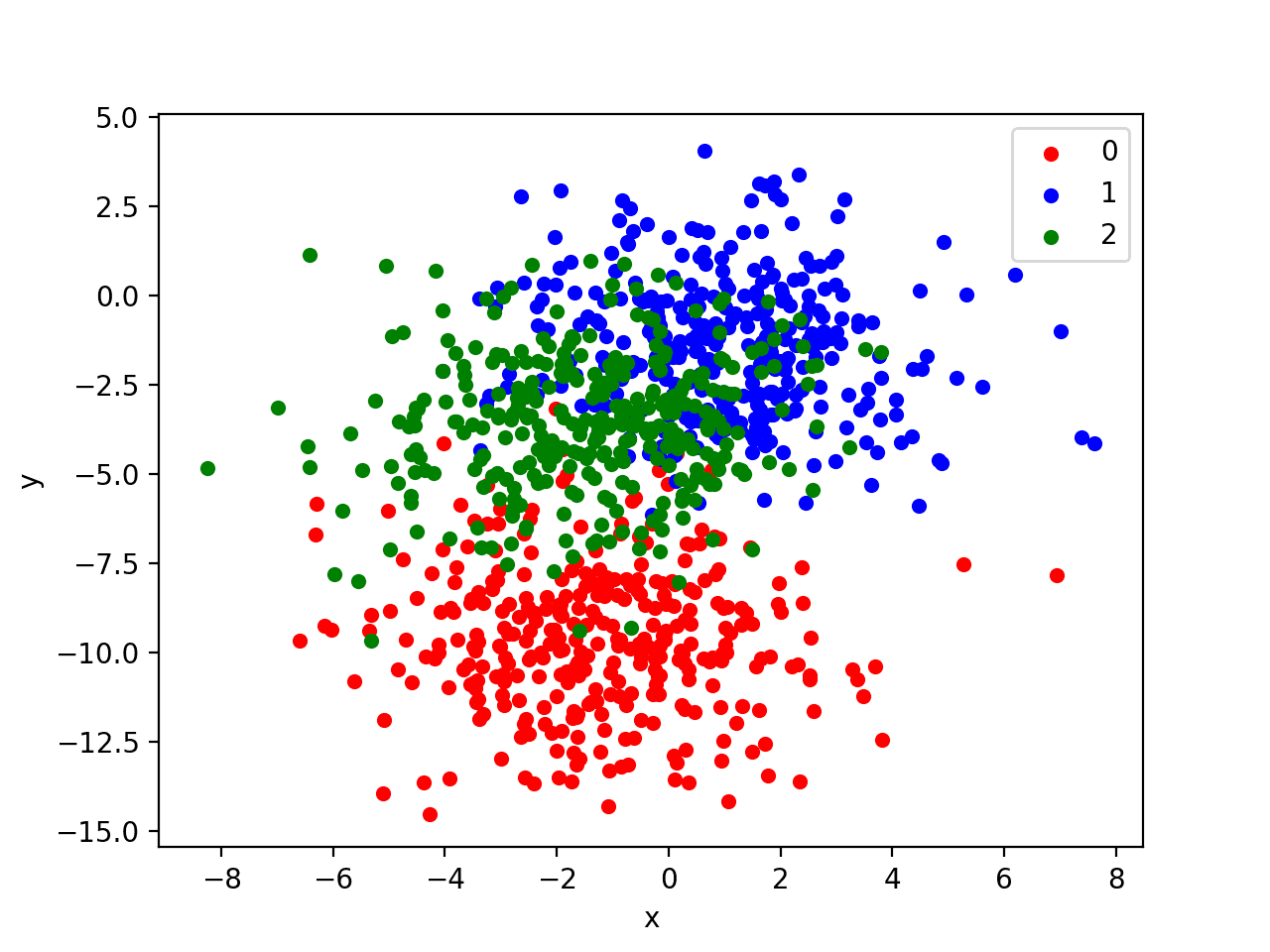
Scatter Plot of Blobs Dataset With Three Classes and Points Colored by Class Value
Multilayer Perceptron Model
Before we define a model, we need to contrive a problem that is appropriate for the stacking ensemble.
In our problem, the training dataset is relatively small. Specifically, there is a 10:1 ratio of examples in the training dataset to the holdout dataset. This mimics a situation where we may have a vast number of unlabeled examples and a small number of labeled examples with which to train a model.
We will create 1,100 data points from the blobs problem. The model will be trained on the first 100 points and the remaining 1,000 will be held back in a test dataset, unavailable to the model.
The problem is a multi-class classification problem, and we will model it using a softmax activation function on the output layer. This means that the model will predict a vector with three elements with the probability that the sample belongs to each of the three classes. Therefore, we must one hot encode the class values before we split the rows into the train and test datasets. We can do this using the Keras to_categorical() function.
# generate 2d classification dataset X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # one hot encode output variable y = to_categorical(y) # split into train and test n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape)
Next, we can define and combine the model.
The model will expect samples with two input variables. The model then has a single hidden layer with 25 nodes and a rectified linear activation function, then an output layer with three nodes to predict the probability of each of the three classes and a softmax activation function.
Because the problem is multi-class, we will use the categorical cross entropy loss function to optimize the model and the efficient Adam flavor of stochastic gradient descent.
# define model model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
The model is fit for 500 training epochs and we will evaluate the model each epoch on the test set, using the test set as a validation set.
# fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0)
At the end of the run, we will evaluate the performance of the model on the train and test sets.
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
Then finally, we will plot learning curves of the model accuracy over each training epoch on both the training and validation datasets.
# learning curves of model accuracy pyplot.plot(history.history['acc'], label='train') pyplot.plot(history.history['val_acc'], label='test') pyplot.legend() pyplot.show()
Tying all of this together, the complete example is listed below.
# develop an mlp for blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# define model
model = Sequential()
model.add(Dense(25, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# learning curves of model accuracy
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
Running the example first prints the shape of each dataset for confirmation, then the performance of the final model on the train and test datasets.
Your specific results will vary (by design!) given the high variance nature of the model.
In this case, we can see that the model achieved about 85% accuracy on the training dataset, which we know is optimistic, and about 80% on the test dataset, which we would expect to be more realistic.
(100, 2) (1000, 2) Train: 0.850, Test: 0.809
A line plot is also created showing the learning curves for the model accuracy on the train and test sets over each training epoch.
We can see that training accuracy is more optimistic over most of the run as we also noted with the final scores.
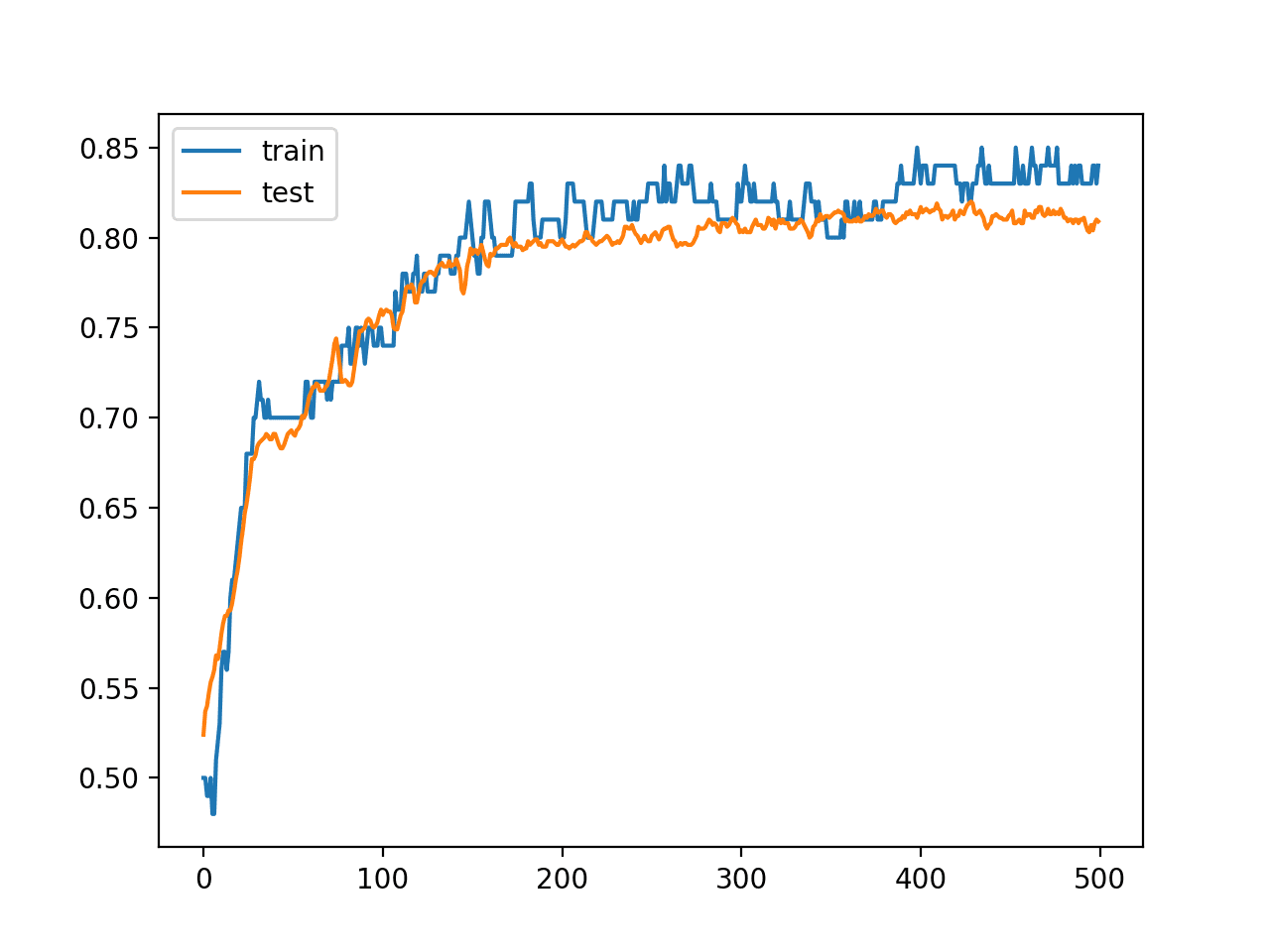
Line Plot Learning Curves of Model Accuracy on Train and Test Dataset Over Each Training Epoch
We can now look at using instances of this model as part of a stacking ensemble.
Train and Save Sub-Models
To keep this example simple, we will use multiple instances of the same model as level-0 or sub-models in the stacking ensemble.
We will also use a holdout validation dataset to train the level-1 or meta-learner in the ensemble.
A more advanced example may use different types of MLP models (deeper, wider, etc.) as sub-models and train the meta-learner using k-fold cross-validation.
In this section, we will train multiple sub-models and save them to file for later use in our stacking ensembles.
The first step is to create a function that will define and fit an MLP model on the training dataset.
# fit model on dataset def fit_model(trainX, trainy): # define model model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # fit model model.fit(trainX, trainy, epochs=500, verbose=0) return model
Next, we can create a sub-directory to store the models.
Note, if the directory already exists, you may have to delete it when re-running this code.
# create directory for models
makedirs('models')
Finally, we can create multiple instances of the MLP and save each to the “models/” subdirectory with a unique filename.
In this case, we will create five sub-models, but you can experiment with a different number of models and see how it impacts model performance.
# fit and save models
n_members = 5
for i in range(n_members):
# fit model
model = fit_model(trainX, trainy)
# save model
filename = 'models/model_' + str(i + 1) + '.h5'
model.save(filename)
print('>Saved %s' % filename)
We can tie all of these elements together; the complete example of training the sub-models and saving them to file is listed below.
# example of saving sub-models for later use in a stacking ensemble
from sklearn.datasets.samples_generator import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
from os import makedirs
# fit model on dataset
def fit_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(25, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy, epochs=500, verbose=0)
return model
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# create directory for models
makedirs('models')
# fit and save models
n_members = 5
for i in range(n_members):
# fit model
model = fit_model(trainX, trainy)
# save model
filename = 'models/model_' + str(i + 1) + '.h5'
model.save(filename)
print('>Saved %s' % filename)
Running the example creates the “models/” subfolder and saves five trained models with unique filenames.
(100, 2) (1000, 2) >Saved models/model_1.h5 >Saved models/model_2.h5 >Saved models/model_3.h5 >Saved models/model_4.h5 >Saved models/model_5.h5
Next, we can look at training a meta-learner to make best use of the predictions from these submodels.
Separate Stacking Model
We can now train a meta-learner that will best combine the predictions from the sub-models and ideally perform better than any single sub-model.
The first step is to load the saved models.
We can use the load_model() Keras function and create a Python list of loaded models.
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'models/model_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
We can call this function to load our five saved models from the “models/” sub-directory.
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
It would be useful to know how well the single models perform on the test dataset as we would expect a stacking model to perform better.
We can easily evaluate each single model on the training dataset and establish a baseline of performance.
# evaluate standalone models on test dataset
for model in members:
testy_enc = to_categorical(testy)
_, acc = model.evaluate(testX, testy_enc, verbose=0)
print('Model Accuracy: %.3f' % acc)
Next, we can train our meta-learner. This requires two steps:
- Prepare a training dataset for the meta-learner.
- Use the prepared training dataset to fit a meta-learner model.
We will prepare a training dataset for the meta-learner by providing examples from the test set to each of the submodels and collecting the predictions. In this case, each model will output three predictions for each example for the probabilities that a given example belongs to each of the three classes. Therefore, the 1,000 examples in the test set will result in five arrays with the shape [1000, 3].
We can combine these arrays into a three-dimensional array with the shape [1000, 5, 3] by using the dstack() NumPy function that will stack each new set of predictions.
As input for a new model, we will require 1,000 examples with some number of features. Given that we have five models and each model makes three predictions per example, then we would have 15 (3 x 5) features for each example provided to the submodels. We can transform the [1000, 5, 3] shaped predictions from the sub-models into a [1000, 15] shaped array to be used to train a meta-learner using the reshape() NumPy function and flattening the final two dimensions. The stacked_dataset() function implements this step.
# create stacked model input dataset as outputs from the ensemble def stacked_dataset(members, inputX): stackX = None for model in members: # make prediction yhat = model.predict(inputX, verbose=0) # stack predictions into [rows, members, probabilities] if stackX is None: stackX = yhat else: stackX = dstack((stackX, yhat)) # flatten predictions to [rows, members x probabilities] stackX = stackX.reshape((stackX.shape[0], stackX.shape[1]*stackX.shape[2])) return stackX
Once prepared, we can use this input dataset along with the output, or y part, of the test set to train a new meta-learner.
In this case, we will train a simple logistic regression algorithm from the scikit-learn library.
Logistic regression only supports binary classification, although the implementation of logistic regression in scikit-learn in the LogisticRegression class supports multi-class classification (more than two classes) using a one-vs-rest scheme. The function fit_stacked_model() below will prepare the training dataset for the meta-learner by calling the stacked_dataset() function, then fit a logistic regression model that is then returned.
# fit a model based on the outputs from the ensemble members def fit_stacked_model(members, inputX, inputy): # create dataset using ensemble stackedX = stacked_dataset(members, inputX) # fit standalone model model = LogisticRegression() model.fit(stackedX, inputy) return model
We can call this function and pass in the list of loaded models and the training dataset.
# fit stacked model using the ensemble model = fit_stacked_model(members, testX, testy)
Once fit, we can use the stacked model, including the members and the meta-learner, to make predictions on new data.
This can be achieved by first using the sub-models to make an input dataset for the meta-learner, e.g. by calling the stacked_dataset() function, then making a prediction with the meta-learner. The stacked_prediction() function below implements this.
# make a prediction with the stacked model def stacked_prediction(members, model, inputX): # create dataset using ensemble stackedX = stacked_dataset(members, inputX) # make a prediction yhat = model.predict(stackedX) return yhat
We can use this function to make a prediction on new data; in this case, we can demonstrate it by making predictions on the test set.
# evaluate model on test set
yhat = stacked_prediction(members, model, testX)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Tying all of these elements together, the complete example of fitting a linear meta-learner for the stacking ensemble of MLP sub-models is listed below.
# stacked generalization with linear meta model on blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from keras.models import load_model
from keras.utils import to_categorical
from numpy import dstack
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'models/model_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
# create stacked model input dataset as outputs from the ensemble
def stacked_dataset(members, inputX):
stackX = None
for model in members:
# make prediction
yhat = model.predict(inputX, verbose=0)
# stack predictions into [rows, members, probabilities]
if stackX is None:
stackX = yhat
else:
stackX = dstack((stackX, yhat))
# flatten predictions to [rows, members x probabilities]
stackX = stackX.reshape((stackX.shape[0], stackX.shape[1]*stackX.shape[2]))
return stackX
# fit a model based on the outputs from the ensemble members
def fit_stacked_model(members, inputX, inputy):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# fit standalone model
model = LogisticRegression()
model.fit(stackedX, inputy)
return model
# make a prediction with the stacked model
def stacked_prediction(members, model, inputX):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# make a prediction
yhat = model.predict(stackedX)
return yhat
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
# evaluate standalone models on test dataset
for model in members:
testy_enc = to_categorical(testy)
_, acc = model.evaluate(testX, testy_enc, verbose=0)
print('Model Accuracy: %.3f' % acc)
# fit stacked model using the ensemble
model = fit_stacked_model(members, testX, testy)
# evaluate model on test set
yhat = stacked_prediction(members, model, testX)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Running the example first loads the sub-models into a list and evaluates the performance of each.
We can see that the best performing model is the final model with an accuracy of about 81.3%.
Your specific results may vary given the stochastic nature of the neural network learning algorithm.
(100, 2) (1000, 2) >loaded models/model_1.h5 >loaded models/model_2.h5 >loaded models/model_3.h5 >loaded models/model_4.h5 >loaded models/model_5.h5 Loaded 5 models Model Accuracy: 0.805 Model Accuracy: 0.806 Model Accuracy: 0.804 Model Accuracy: 0.809 Model Accuracy: 0.813
Next, a logistic regression meta-learner is trained on the predicted probabilities from each sub-model on the test set, then the entire stacking model is evaluated on the test set.
We can see that in this case, the meta-learner out-performed each of the sub-models on the test set, achieving an accuracy of about 82.4%.
Stacked Test Accuracy: 0.824
Integrated Stacking Model
When using neural networks as sub-models, it may be desirable to use a neural network as a meta-learner.
Specifically, the sub-networks can be embedded in a larger multi-headed neural network that then learns how to best combine the predictions from each input sub-model. It allows the stacking ensemble to be treated as a single large model.
The benefit of this approach is that the outputs of the submodels are provided directly to the meta-learner. Further, it is also possible to update the weights of the submodels in conjunction with the meta-learner model, if this is desirable.
This can be achieved using the Keras functional interface for developing models.
After the models are loaded as a list, a larger stacking ensemble model can be defined where each of the loaded models is used as a separate input-head to the model. This requires that all of the layers in each of the loaded models be marked as not trainable so the weights cannot be updated when the new larger model is being trained. Keras also requires that each layer has a unique name, therefore the names of each layer in each of the loaded models will have to be updated to indicate to which ensemble member they belong.
# update all layers in all models to not be trainable for i in range(len(members)): model = members[i] for layer in model.layers: # make not trainable layer.trainable = False # rename to avoid 'unique layer name' issue layer.name = 'ensemble_' + str(i+1) + '_' + layer.name
Once the sub-models have been prepared, we can define the stacking ensemble model.
The input layer for each of the sub-models will be used as a separate input head to this new model. This means that k copies of any input data will have to be provided to the model, where k is the number of input models, in this case, 5.
The outputs of each of the models can then be merged. In this case, we will use a simple concatenation merge, where a single 15-element vector will be created from the three class-probabilities predicted by each of the 5 models.
We will then define a hidden layer to interpret this “input” to the meta-learner and an output layer that will make its own probabilistic prediction. The define_stacked_model() function below implements this and will return a stacked generalization neural network model given a list of trained sub-models.
# define stacked model from multiple member input models def define_stacked_model(members): # update all layers in all models to not be trainable for i in range(len(members)): model = members[i] for layer in model.layers: # make not trainable layer.trainable = False # rename to avoid 'unique layer name' issue layer.name = 'ensemble_' + str(i+1) + '_' + layer.name # define multi-headed input ensemble_visible = [model.input for model in members] # concatenate merge output from each model ensemble_outputs = [model.output for model in members] merge = concatenate(ensemble_outputs) hidden = Dense(10, activation='relu')(merge) output = Dense(3, activation='softmax')(hidden) model = Model(inputs=ensemble_visible, outputs=output) # plot graph of ensemble plot_model(model, show_shapes=True, to_file='model_graph.png') # compile model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model
A plot of the network graph is created when this function is called to give an idea of how the ensemble model fits together.
# define ensemble model stacked_model = define_stacked_model(members)
Creating the plot requires that pygraphviz is installed.
If this is a challenge on your workstation, you can comment out the call to the plot_model() function.
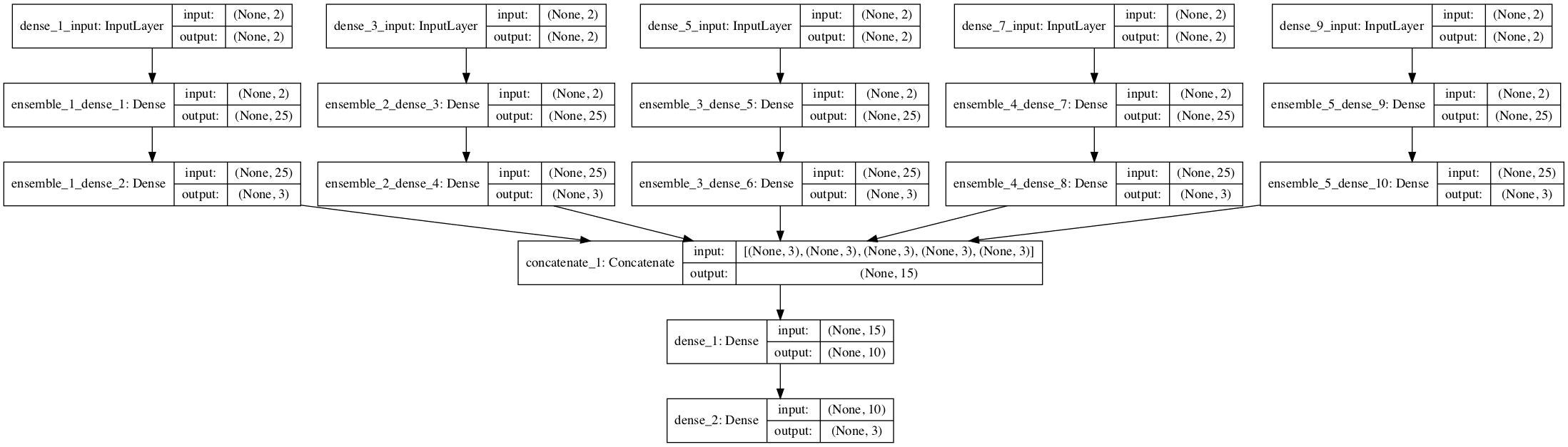
Visualization of Stacked Generalization Ensemble of Neural Network Models
Once the model is defined, it can be fit. We can fit it directly on the holdout test dataset.
Because the sub-models are not trainable, their weights will not be updated during training and only the weights of the new hidden and output layer will be updated. The fit_stacked_model() function below will fit the stacking neural network model on for 300 epochs.
# fit a stacked model def fit_stacked_model(model, inputX, inputy): # prepare input data X = [inputX for _ in range(len(model.input))] # encode output data inputy_enc = to_categorical(inputy) # fit model model.fit(X, inputy_enc, epochs=300, verbose=0)
We can call this function providing the defined stacking model and the test dataset.
# fit stacked model on test dataset fit_stacked_model(stacked_model, testX, testy)
Once fit, we can use the new stacked model to make a prediction on new data.
This is as simple as calling the predict() function on the model. One minor change is that we require k copies of the input data in a list to be provided to the model for each of the k sub-models. The predict_stacked_model() function below simplifies this process of making a prediction with the stacking model.
# make a prediction with a stacked model def predict_stacked_model(model, inputX): # prepare input data X = [inputX for _ in range(len(model.input))] # make prediction return model.predict(X, verbose=0)
We can call this function to make a prediction for the test dataset and report the accuracy.
We would expect the performance of the neural network learner to be better than any individual submodel and perhaps competitive with the linear meta-learner used in the previous section.
# make predictions and evaluate
yhat = predict_stacked_model(stacked_model, testX)
yhat = argmax(yhat, axis=1)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Tying all of these elements together, the complete example is listed below.
# stacked generalization with neural net meta model on blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from sklearn.metrics import accuracy_score
from keras.models import load_model
from keras.utils import to_categorical
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers.merge import concatenate
from numpy import argmax
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'models/model_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
# define stacked model from multiple member input models
def define_stacked_model(members):
# update all layers in all models to not be trainable
for i in range(len(members)):
model = members[i]
for layer in model.layers:
# make not trainable
layer.trainable = False
# rename to avoid 'unique layer name' issue
layer.name = 'ensemble_' + str(i+1) + '_' + layer.name
# define multi-headed input
ensemble_visible = [model.input for model in members]
# concatenate merge output from each model
ensemble_outputs = [model.output for model in members]
merge = concatenate(ensemble_outputs)
hidden = Dense(10, activation='relu')(merge)
output = Dense(3, activation='softmax')(hidden)
model = Model(inputs=ensemble_visible, outputs=output)
# plot graph of ensemble
plot_model(model, show_shapes=True, to_file='model_graph.png')
# compile
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# fit a stacked model
def fit_stacked_model(model, inputX, inputy):
# prepare input data
X = [inputX for _ in range(len(model.input))]
# encode output data
inputy_enc = to_categorical(inputy)
# fit model
model.fit(X, inputy_enc, epochs=300, verbose=0)
# make a prediction with a stacked model
def predict_stacked_model(model, inputX):
# prepare input data
X = [inputX for _ in range(len(model.input))]
# make prediction
return model.predict(X, verbose=0)
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
# define ensemble model
stacked_model = define_stacked_model(members)
# fit stacked model on test dataset
fit_stacked_model(stacked_model, testX, testy)
# make predictions and evaluate
yhat = predict_stacked_model(stacked_model, testX)
yhat = argmax(yhat, axis=1)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Running the example first loads the five sub-models.
A larger stacking ensemble neural network is defined and fit on the test dataset, then the new model is used to make a prediction on the test dataset. We can see that, in this case, the model achieved an accuracy of about 83.3%, out-performing the linear model from the previous section.
(100, 2) (1000, 2) >loaded models/model_1.h5 >loaded models/model_2.h5 >loaded models/model_3.h5 >loaded models/model_4.h5 >loaded models/model_5.h5 Loaded 5 models Stacked Test Accuracy: 0.833
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Alternate Meta-Learner. Update the example to use an alternate meta-learner classifier model to the logistic regression model.
- Single Level 0 Model. Update the example to use a single level-0 model and compare the results.
- Vary Level 0 Models. Develop a study that demonstrates the relationship between test classification accuracy and the number of sub-models used in the stacked ensemble.
- Cross-Validation Stacking Ensemble. Update the example to use k-fold cross-validation to prepare the training dataset for the meta-learner model.
- Use Raw Input in Meta-Learner. Update the example so that the meta-learner algorithms take the raw input data for the sample as well as the output from the sub-models and compare performance.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Section 8.8 Model Averaging and Stacking, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition, 2016.
- Section 7.5 Combining multiple models, Data Mining: Practical Machine Learning Tools and Techniques, Second Edition, 2005.
- Section 9.8.2 Stacked Generalization, Neural Networks for Pattern Recognition, 1995.
Papers
- Stacked generalization, 1992.
- Issues in Stacked Generalization, 1999.
API
- Getting started with the Keras Sequential model
- Keras Core Layers API
- numpy.argmax API
- sklearn.datasets.make_blobs API
- numpy.dstack API
- sklearn.linear_model.LogisticRegression API
Articles
Posts
Summary
In this tutorial, you discovered how to develop a stacked generalization ensemble for deep learning neural networks.
Specifically, you learned:
- Stacked generalization is an ensemble method where a new model learns how to best combine the predictions from multiple existing models.
- How to develop a stacking model using neural networks as a submodel and a scikit-learn classifier as the meta-learner.
- How to develop a stacking model where neural network sub-models are embedded in a larger stacking ensemble model for training and prediction.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Develop a Stacking Ensemble for Deep Learning Neural Networks in Python With Keras appeared first on Machine Learning Mastery.