
Author: Jason Brownlee
Face recognition is the problem of identifying and verifying people in a photograph by their face.
It is a task that is trivially performed by humans, even under varying light and when faces are changed by age or obstructed with accessories and facial hair. Nevertheless, it is remained a challenging computer vision problem for decades until recently.
Deep learning methods are able to leverage very large datasets of faces and learn rich and compact representations of faces, allowing modern models to first perform as-well and later to outperform the face recognition capabilities of humans.
In this post, you will discover the problem of face recognition and how deep learning methods can achieve superhuman performance.
After reading this post, you will know:
- Face recognition is a broad problem of identifying or verifying people in photographs and videos.
- Face recognition is a process comprised of detection, alignment, feature extraction, and a recognition task
- Deep learning models first approached then exceeded human performance for face recognition tasks.
Let’s get started.

A Gentle Introduction to Deep Learning for Face Recognition
Photo by Susanne Nilsson, some rights reserved.
Overview
This tutorial is divided into five parts; they are:
- Faces in Photographs
- Process of Automatic Face Recognition
- Face Detection Task
- Face Recognition Tasks
- Deep Learning for Face Recognition
Faces in Photographs
There is often a need to automatically recognize the people in a photograph.
There are many reasons why we might want to automatically recognize a person in a photograph.
For example:
- We may want to restrict access to a resource to one person, called face authentication.
- We may want to confirm that the person matches their ID, called face verification.
- We may want to assign a name to a face, called face identification.
Generally, we refer to this as the problem of automatic “face recognition” and it may apply to both still photographs or faces in streams of video.
Humans can perform this task very easily.
We can find the faces in an image and comment as to who the people are, if they are known. We can do this very well, such as when the people have aged, are wearing sunglasses, have different colored hair, are looking in different directions, and so on. We can do this so well that we find faces where there aren’t any, such as in clouds.
Nevertheless, this remains a hard problem to perform automatically with software, even after 60 or more years of research. Until perhaps very recently.
For example, recognition of face images acquired in an outdoor environment with changes in illumination and/or pose remains a largely unsolved problem. In other words, current systems are still far away from the capability of the human perception system.
— Face Recognition: A Literature Survey, 2003.
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Process of Automatic Face Recognition
Face recognition is the problem of identifying or verifying faces in a photograph.
A general statement of the problem of machine recognition of faces can be formulated as follows: given still or video images of a scene, identify or verify one or more persons in the scene using a stored database of faces
— Face Recognition: A Literature Survey, 2003.
Face recognition is often described as a process that first involves four steps; they are: face detection, face alignment, feature extraction, and finally face recognition.
- Face Detection. Locate one or more faces in the image and mark with a bounding box.
- Face Alignment. Normalize the face to be consistent with the database, such as geometry and photometrics.
- Feature Extraction. Extract features from the face that can be used for the recognition task.
- Face Recognition. Perform matching of the face against one or more known faces in a prepared database.
A given system may have a separate module or program for each step, which was traditionally the case, or may combine some or all of the steps into a single process.
A helpful overview of this process is provided in the book “Handbook of Face Recognition,” provided below:
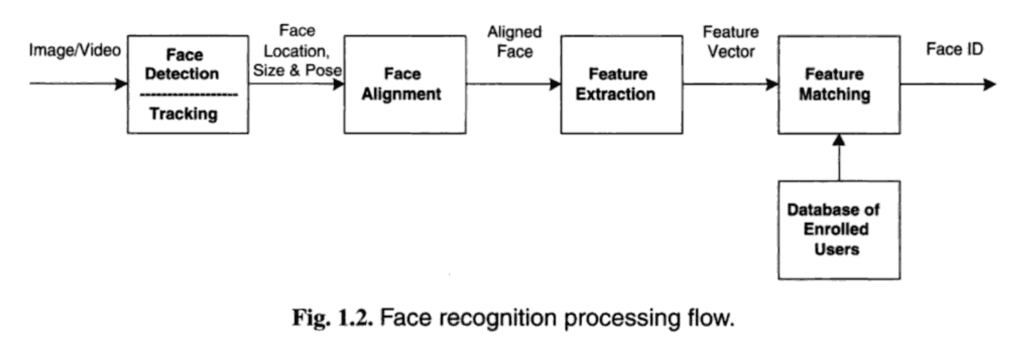
Overview of the Steps in a Face Recognition Process. Taken from “Handbook of Face Recognition,” 2011.
Face Detection Task
Face detection is the non-trivial first step in face recognition.
It is a problem of object recognition that requires that both the location of each face in a photograph is identified (e.g. the position) and the extent of the face is localized (e.g. with a bounding box). Object recognition itself is a challenging problem, although in this case, it is similar as there is only one type of object, e.g. faces, to be localized, although faces can vary wildly.
The human face is a dynamic object and has a high degree of variability in its appearance, which makes face detection a difficult problem in computer vision.
— Face Detection: A Survey, 2001.
Further, because it is the first step in a broader face recognition system, face detection must be robust. For example, a face cannot be recognized if it cannot first be detected. That means faces must be detected with all manner of orientations, angles, light levels, hairstyles, hats, glasses, facial hair, makeup, ages, and so on.
As a visual front-end processor, a face detection system should also be able to achieve the task regardless of illumination, orientation, and camera distance
— Face Detection: A Survey, 2001.
The 2001 paper titled “Face Detection: A Survey” provides a taxonomy of face detection methods that can be broadly divided into two main groups:
- Feature-Based.
- Image-Based.
The feature-based face detection uses hand-crafted filters that search for and locate faces in photographs based on a deep knowledge of the domain. They can be very fast and very effective when the filters match, although they can fail dramatically when they don’t, e.g. making them somewhat fragile.
… make explicit use of face knowledge and follow the classical detection methodology in which low level features are derived prior to knowledge-based analysis. The apparent properties of the face such as skin color and face geometry are exploited at different system levels.
— Face Detection: A Survey, 2001.
Alternately, image-based face detection is holistic and learns how to automatically locate and extract faces from the entire image. Neural networks fit into this class of methods.
… address face detection as a general recognition problem. Image-based representations of faces, for example in 2D intensity arrays, are directly classified into a face group using training algorithms without feature derivation and analysis. […] these relatively new techniques incorporate face knowledge implicitly into the system through mapping and training schemes.
— Face Detection: A Survey, 2001.
Perhaps the dominant method for face detection used for many years (and was used in many cameras) was described in the 2004 paper titled “Robust Real-time Object Detection,” called the detector cascade or simply “cascade.”
Their detector, called detector cascade, consists of a sequence of simple-to-complex face classifiers and has attracted extensive research efforts. Moreover, detector cascade has been deployed in many commercial products such as smartphones and digital cameras. While cascade detectors can accurately find visible upright faces, they often fail to detect faces from different angles, e.g. side view or partially occluded faces.
— Multi-view Face Detection Using Deep Convolutional Neural Networks, 2015.
Face Recognition Tasks
The task of face recognition is broad and can be tailored to the specific needs of a prediction problem.
For example, in the 1995 paper titled “Human and machine recognition of faces: A survey,” the authors describe three face recognition tasks:
- Face Matching: Find the best match for a given face.
- Face Similarity: Find faces that are most similar to a given face.
- Face Transformation: Generate new faces that are similar to a given face.
They summarize these three separate tasks as follows:
Matching requires that the candidate matching face image be in some set of face images selected by the system. Similarity detection requires in addition to matching that images of faces be found which are similar to a recalled face this requires that the similarity measure used by the recognition system closely match the similarity measures used by humans Transformation applications require that new images created by the system be similar to human recollections of a face.
— Human and machine recognition of faces: A survey, 1995.
The 2011 book on face recognition titled “Handbook of Face Recognition” describes two main modes for face recognition, as:
- Face Verification. A one-to-one mapping of a given face against a known identity (e.g. is this the person?).
- Face Identification. A one-to-many mapping for a given face against a database of known faces (e.g. who is this person?).
A face recognition system is expected to identify faces present in images and videos automatically. It can operate in either or both of two modes: (1) face verification (or authentication), and (2) face identification (or recognition).
— Page 1, Handbook of Face Recognition. 2011.
We can describe the problem of face recognition as a supervised predictive modeling task trained on samples with inputs and outputs.
In all tasks, the input is a photo that contains at least one face, most likely a detected face that may also have been aligned.
The output varies based on the type of prediction required for the task; for example:
- It may then be a binary class label or binary class probability in the case of a face verification task.
- It may be a categorical class label or set of probabilities for a face identification task.
- It may be a similarity metric in the case of a similarity type task.
Deep Learning for Face Recognition
Face recognition has remained an active area of research in computer vision.
Perhaps one of the more widely known and adopted “machine learning” methods for face recognition was described in the 1991 paper titled “Face Recognition Using Eigenfaces.” Their method, called simply “Eigenfaces,” was a milestone as it achieved impressive results and demonstrated the capability of simple holistic approaches.
Face images are projected onto a feature space (“face space”) that best encodes the variation among known face images. The face space is defined by the “eigenfaces”, which are the eigenvectors of the set of faces; they do not necessarily correspond to isolated features such as eyes, ears, and noses
— Face Recognition Using Eigenfaces, 1991.
The 2018 paper titled “Deep Face Recognition: A Survey,” provides a helpful summary of the state of face recognition research over the last nearly 30 years, highlighting the broad trend from holistic learning methods (such as Eigenfaces), to local handcrafted feature detection, to shallow learning methods, to finally deep learning methods that are currently state of the art.
The holistic approaches dominated the face recognition community in the 1990s. In the early 2000s, handcrafted local descriptors became popular, and the local feature learning approach were introduced in the late 2000s. […] [shallow learning method] performance steadily improves from around 60% to above 90%, while deep learning boosts the performance to 99.80% in just three years.
— Deep Face Recognition: A Survey, 2018.
Given the breakthrough of AlexNet in 2012 for the simpler problem of image classification, there was a flurry of research and publications in 2014 and 2015 on deep learning methods for face recognition. Capabilities quickly achieved near-human-level performance, then exceeded human-level performance on a standard face recognition dataset within a three year period, which is an astounding rate of improvement given the prior decades of effort.
There are perhaps four milestone systems on deep learning for face recognition that drove these innovations; they are: DeepFace, the DeepID series of systems, VGGFace, and FaceNet. Let’s briefly touch on each.
DeepFace is a system based on deep convolutional neural networks described by Yaniv Taigman, et al. from Facebook AI Research and Tel Aviv. It was described in the 2014 paper titled “DeepFace: Closing the Gap to Human-Level Performance in Face Verification.” It was perhaps the first major leap forward using deep learning for face recognition, achieving near human-level performance on a standard benchmark dataset.
Our method reaches an accuracy of 97.35% on the Labeled Faces in the Wild (LFW) dataset, reducing the error of the current state of the art by more than 27%, closely approaching human-level performance.
— DeepFace: Closing the Gap to Human-Level Performance in Face Verification, 2014.
The DeepID, or “Deep hidden IDentity features,” is a series of systems (e.g. DeepID, DeepID2, etc.), first described by Yi Sun, et al. in their 2014 paper titled “Deep Learning Face Representation from Predicting 10,000 Classes.” Their system was first described much like DeepFace, although was expanded in subsequent publications to support both identification and verification tasks by training via contrastive loss.
The key challenge of face recognition is to develop effective feature representations for reducing intra-personal variations while enlarging inter-personal differences. […] The face identification task increases the inter-personal variations by drawing DeepID2 features extracted from different identities apart, while the face verification task reduces the intra-personal variations by pulling DeepID2 features extracted from the same identity together, both of which are essential to face recognition.
— Deep Learning Face Representation by Joint Identification-Verification, 2014.
The DeepID systems were among the first deep learning models to achieve better-than-human performance on the task, e.g. DeepID2 achieved 99.15% on the Labeled Faces in the Wild (LFW) dataset, which is better-than-human performance of 97.53%. Subsequent systems such as FaceNet and VGGFace improved upon these results.
FaceNet was described by Florian Schroff, et al. at Google in their 2015 paper titled “FaceNet: A Unified Embedding for Face Recognition and Clustering.” Their system achieved then state-of-the-art results and presented an innovation called ‘triplet loss‘ that allowed images to be encoded efficiently as feature vectors that allowed rapid similarity calculation and matching via distance calculations.
FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. […] Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method
— FaceNet: A Unified Embedding for Face Recognition and Clustering, 2015.
The VGGFace (for lack of a better name) was developed by Omkar Parkhi, et al. from the Visual Geometry Group (VGG) at Oxford and was described in their 2015 paper titled “Deep Face Recognition.” In addition to a better-tuned model, the focus of their work was on how to collect a very large training dataset and use this to train a very deep CNN model for face recognition that allowed them to achieve then state-of-the-art results on standard datasets.
… we show how a very large scale dataset (2.6M images, over 2.6K people) can be assembled by a combination of automation and human in the loop
— Deep Face Recognition, 2015.
Although these may be the key early milestones in the field of deep learning for computer vision, progress has continued, with much innovation focused on loss functions to effectively train the models.
For an excellent up-to-date summary, see the 2018 paper “Deep Face Recognition: A Survey.”
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Handbook of Face Recognition, Second Edition, 2011.
Face Recognition Papers
- Face Recognition: A Literature Survey, 2003.
- Face Detection: A Survey, 2001.
- Human and machine recognition of faces: A survey, 1995.
- Robust Real-time Object Detection, 2004.
- Face Recognition Using Eigenfaces, 1991.
Deep Learning Face Recognition Papers
- Deep Face Recognition: A Survey, 2018.
- Deep face recognition, 2015.
- FaceNet: A Unified Embedding for Face Recognition and Clustering, 2015.
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification, 2014.
- Deep Learning Face Representation by Joint Identification-Verification, 2014.
- Deep Learning Face Representation from Predicting 10,000 Classes, 2014.
- Multi-view Face Detection Using Deep Convolutional Neural Networks, 2015.
- From Facial Parts Responses to Face Detection: A Deep Learning Approach, 2015.
- Surpassing Human-Level Face Verification Performance on LFW with GaussianFace, 2014.
Articles
- Facial recognition system, Wikipedia.
- Facial recognition, Wikipedia.
- Face detection, Wikipedia.
- Labeled Faces in the Wild Dataset
Summary
In this post, you discovered the problem of face recognition and how deep learning methods can achieve superhuman performance.
Specifically, you learned:
- Face recognition is a broad problem of identifying or verifying people in photographs and videos.
- Face recognition is a process comprised of detection, alignment, feature extraction, and a recognition task
- Deep learning models first approached then exceeded human performance for face recognition tasks.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post A Gentle Introduction to Deep Learning for Face Recognition appeared first on Machine Learning Mastery.