
Author: Jason Brownlee
One-shot learning is a classification task where one, or a few, examples are used to classify many new examples in the future.
This characterizes tasks seen in the field of face recognition, such as face identification and face verification, where people must be classified correctly with different facial expressions, lighting conditions, accessories, and hairstyles given one or a few template photos.
Modern face recognition systems approach the problem of one-shot learning via face recognition by learning a rich low-dimensional feature representation, called a face embedding, that can be calculated for faces easily and compared for verification and identification tasks.
Historically, embeddings were learned for one-shot learning problems using a Siamese network. The training of Siamese networks with comparative loss functions resulted in better performance, later leading to the triplet loss function used in the FaceNet system by Google that achieved then state-of-the-art results on benchmark face recognition tasks.
In this post, you will discover the challenge of one-shot learning in face recognition and how comparative and triplet loss functions can be used to learn high-quality face embeddings.
After reading this post, you will know:
- One-shot learning are classification tasks where many predictions are required given one (or a few) examples of each class, and face recognition is an example of one-shot learning.
- Siamese networks are an approach to addressing one-shot learning in which a learned feature vector for the known and candidate example are compared.
- Contrastive loss and later triplet loss functions can be used to learn high-quality face embedding vectors that provide the basis for modern face recognition systems.
Let’s get started.

One-Shot Learning with Siamese Networks, Contrastive, and Triplet Loss for Face Recognition
Photo by Heath Cajandig, some rights reserved.
Overview
This tutorial is divided into four parts; they are:
- One-Shot Learning and Face Recognition
- Siamese Network for One-Shot Learning
- Contrastive Loss for Dimensionality Reduction
- Triplet Loss for Learning Face Embeddings
One-Shot Learning and Face Recognition
Typically, classification involves fitting a model given many examples of each class, then using the fit model to make predictions on many examples of each class.
For example, we may have thousands of measurements of plants from three different species. A model can be fit on these examples, generalizing from the commonalities among the measurements for a given species and contrasting differences in the measurements across species. The result, hopefully, is a robust model that, given a new set of measurements in the future, can accurately predict the plant species.
One-shot learning is a classification task where one example (or a very small number of examples) is given for each class, that is used to prepare a model, that in turn must make predictions about many unknown examples in the future.
In the case of one-shot learning, a single exemplar of an object class is presented to the algorithm.
— Knowledge transfer in learning to recognize visual objects classes, 2006.
This is a relatively easy problem for humans. For example, a person may see a Ferrari sports car one time, and in the future, be able to recognize Ferraris in new situations, on the road, in movies, in books, and with different lighting and colors.
Humans learn new concepts with very little supervision – e.g. a child can generalize the concept of “giraffe” from a single picture in a book – yet our best deep learning systems need hundreds or thousands of examples.
— Matching Networks for One Shot Learning, 2017.
One-shot learning is related to but different from zero-shot learning.
This should be distinguished from zero-shot learning, in which the model cannot look at any examples from the target classes.
— Siamese Neural Networks for One-shot Image Recognition, 2015.
Face recognition tasks provide examples of one-shot learning.
Specifically, in the case of face identification, a model or system may only have one or a few examples of a given person’s face and must correctly identify the person from new photographs with changes to expression, hairstyle, lighting, accessories, and more.
In the case of face verification, a model or system may only have one example of a persons face on record and must correctly verify new photos of that person, perhaps each day.
As such, face recognition is a common example of one-shot learning.
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Siamese Network for One-Shot Learning
A network that has been popularized given its use for one-shot learning is the Siamese network.
A Siamese network is an architecture with two parallel neural networks, each taking a different input, and whose outputs are combined to provide some prediction.
It is a network designed for verification tasks, first proposed for signature verification by Jane Bromley et al. in the 2005 paper titled “Signature Verification using a Siamese Time Delay Neural Network.”
The algorithm is based on a novel, artificial neural network, called a “Siamese” neural network. This network consists of two identical sub-networks joined at their outputs.
— Signature Verification using a “Siamese” Time Delay Neural Network, 2005.
Two identical networks are used, one taking the known signature for the person, and another taking a candidate signature. The outputs of both networks are combined and scored to indicate whether the candidate signature is real or a forgery.
Verification consists of comparing an extracted feature vector with a stored feature vector for the signer. Signatures closer to this stored representation than a chosen threshold are accepted, all other signatures are rejected as forgeries.
— Signature Verification using a “Siamese” Time Delay Neural Network, 2005.
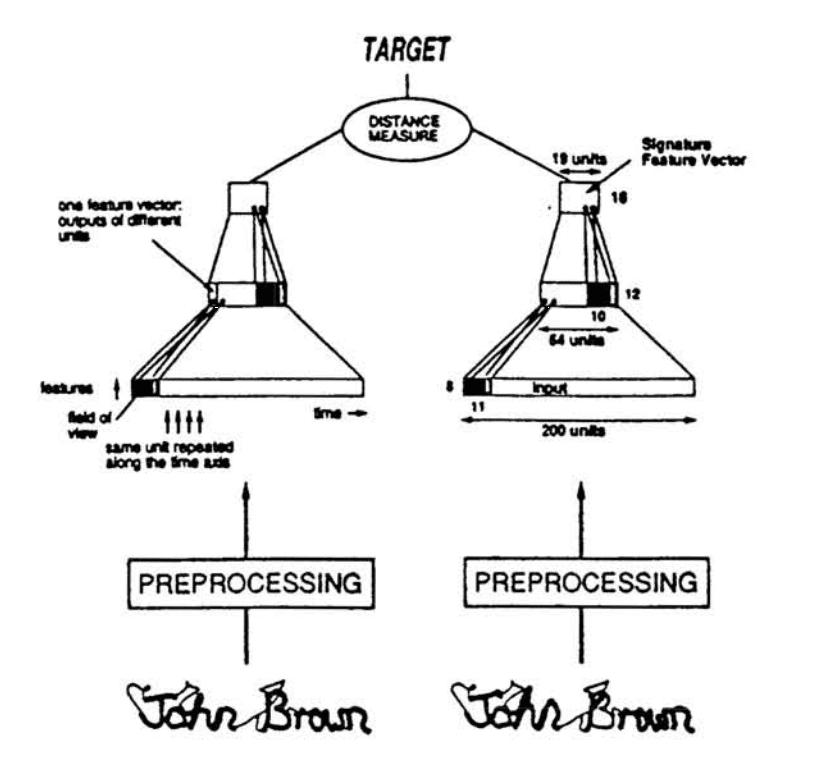
Example of a Siamese Network for Signature Verification.
Taken from: Signature Verification using a “Siamese” Time Delay Neural Network.
Siamese networks were used more recently, where deep convolutional neural networks were used in parallel image inputs in a 2015 paper by Gregory Koch, et al. titled “Siamese Neural Networks for One-Shot Image Recognition.”
The deep CNNs are first trained to discriminate between examples of each class. The idea is to have the models learn feature vectors that are effective at extracting abstract features from the input images.

Example of Image Verification Used to Train a Siamese Network.
Taken from: Siamese Neural Networks for One-Shot Image Recognition.
The models are then re-purposed for verification to predict whether new examples match a template for each class.
Specifically, each network produces a feature vector for an input image, which are then compared using the L1 distance and a sigmoid activation. The model was applied to benchmark handwritten character datasets used in computer vision.

Example of One-Shot Image Classification Used to Test a Siamese Network.
Taken from: Siamese Neural Networks for One-Shot Image Recognition.
The Siamese Network is interesting for its approach to solving one-shot learning by learning feature representations (feature vectors) that are then compared for verification tasks.
An example of a face recognition system that was developed using a Siamese Network is DeepFace, described by Yaniv Taigman, et al. in the 2014 paper titled “DeepFace: Closing the Gap to Human-Level Performance in Face Verification.”
Their approach involved first training the model for face identification, then removing the classifier layer of the model and using the activations as a feature vector that were then calculated and compared for two different faces for face verification.
We have also tested an end-to-end metric learning approach, known as Siamese network: once learned, the face recognition network (without the top layer) is replicated twice (one for each input image) and the features are used to directly predict whether the two input images belong to the same person.
— DeepFace: Closing the Gap to Human-Level Performance in Face Verification, 2014.
Contrastive Loss for Dimensionality Reduction
Learning a vector representation of a complex input, like an image, is an example of dimensionality reduction.
Dimensionality reduction aims to translate high dimensional data to a low dimensional representation such that similar input objects are mapped to nearby points on a manifold.
— Dimensionality Reduction by Learning an Invariant Mapping, 2006.
The goal of effective dimensionality reduction is to learn a new lower dimensional representation that preserves the structure of the input such that distances between output vectors meaningfully capture the differences in the input. Yet, the vectors must capture the invariant features in the input.
The problem is to find a function that maps high dimensional input patterns to lower dimensional outputs, given neighborhood relationships between samples in input space.
— Dimensionality Reduction by Learning an Invariant Mapping, 2006.
Dimensionality reduction is the approach that Siamese networks use to address one-shot learning.
In their 2006 paper titled “Dimensionality Reduction by Learning an Invariant Mapping,” Raia Hadsell, et al. explore using a Siamese network for dimensionality reduction with convolutional neural networks with image data and propose training the models via contrastive loss.
Unlike other loss functions that may evaluate the performance of a model across all input examples in the training dataset, contrastive loss is calculated between pairs of inputs, such as between the two inputs provided to a Siamese network.
Pairs of examples are provided to the network, and the loss function penalizes the model differently based on whether the classes of the samples are the same or different. Specifically, if the classes are the same, the loss function encourages the models to output feature vectors that are more similar, whereas if the classes differ, the loss function encourages the models to output feature vectors that are less similar.
The contrastive loss requires face image pairs and then pulls together positive pairs and pushes apart negative pairs. […] However, the main problem with the contrastive loss is that the margin parameters are often difficult to choose.
— Deep Face Recognition: A Survey, 2018.
The loss function requires that a margin is selected that is used to determine the limit to which examples from different pairs are penalized. Choosing this margin requires careful consideration and is one downside of using the loss function.
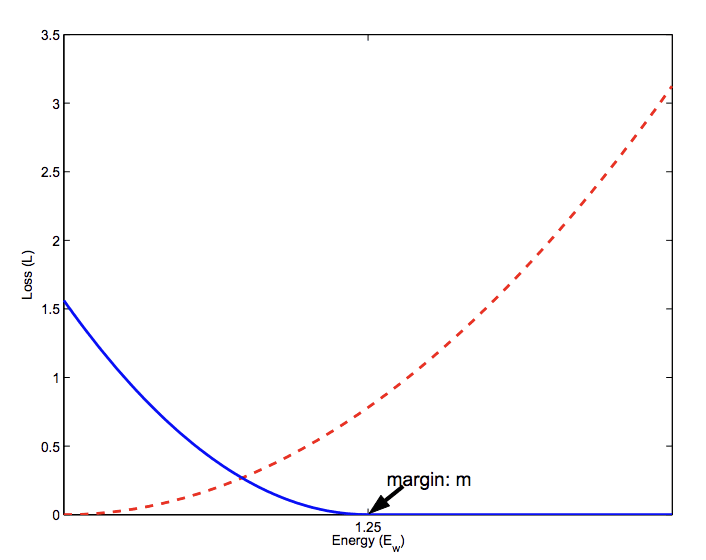
Plot of Contrastive Loss Calculation for Similar (red) and Dissimilar (blue) Pairs.
Taken From: Dimensionality reduction by learning an invariant mapping
Contrastive loss can be used to train a face recognition system, specifically for the task of face verification. Further, this can be achieved without the need for parallel models used in the Siamese network architecture by providing pairs of examples sequentially and saving the predicted feature vectors before calculating the loss and updating the model.
An example is the DeepID2 and subsequent systems (DeepID2+ and DeepID3) that used deep convolutional neural networks, but not a Siamese network architecture, and achieved then state-of-the-art results on benchmark face recognition datasets.
The verification signal directly regularize DeepID2 and can effectively reduce the intra-personal variations. Commonly used constraints include the L1/L2 norm and cosine similarity. We adopt the following loss function based on the L2 norm, which was originally proposed by Hadsell et al. for dimensionality reduction.
— Deep Learning Face Representation by Joint Identification-Verification, 2014.
Triplet Loss for Learning Face Embeddings
The idea of comparative loss can be further extended from two examples to three, called triplet loss.
Triplet loss was introduced by Florian Schroff, et al. from Google in their 2015 paper titled “FaceNet: A Unified Embedding for Face Recognition and Clustering.”
Rather than calculating loss based on two examples, triplet loss involves an anchor example and one positive or matching example (same class) and one negative or non-matching example (differing class).
The loss function penalizes the model such that the distance between the matching examples is reduced and the distance between the non-matching examples is increased.
It requires the face triplets, and then it minimizes the distance between an anchor and a positive sample of the same identity and maximizes the distance between the anchor and a negative sample of a different identity.
— Deep Face Recognition: A Survey, 2018.
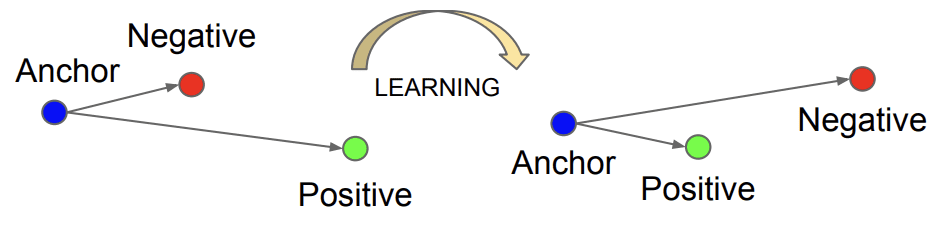
Example of The Effect on Anchor, Positive, and Negative Both Before and After Applying Triplet Loss.
Taken from: Facenet: A unified embedding for face recognition and clustering.
The result is a feature vector, referred to as a ‘face embedding,’ that has a meaningful Euclidean relationship, such that similar faces produce embeddings that have small distances (e.g. can be clustered) and different examples of the same face produce embeddings that are very small and allow verification and discrimination from other identities.
This approach is used as the basis behind the FaceNet system that achieved then state-of-the-art results on benchmark face recognition datasets.
In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity.
— Facenet: A unified embedding for face recognition and clustering, 2015.
The triplets that are used to train the model are carefully chosen.
Triplets that are easy, result in a small loss, and are not effective at updating the model. Instead, hard triplets are sought that encourage changes to the model and the predicted face embeddings.
Choosing which triplets to use turns out to be very important for achieving good performance and, inspired by curriculum learning, we present a novel online negative exemplar mining strategy which ensures consistently increasing difficulty of triplets as the network trains.
— Facenet: A unified embedding for face recognition and clustering, 2015.
Triplets are generated in an online manner, and so-called hard positive (matching) and hard negative (non-matching) cases are found and used in the estimate of the loss for the batch.
It is crucial to select hard triplets, that are active and can therefore contribute to improving the model.
— Facenet: A unified embedding for face recognition and clustering, 2015.
The approach of directly training face embeddings, such as via triplet loss, and using the embeddings as the basis for face identification and face verification models, such as FaceNet, is the basis for modern and state-of-the-art methods for face recognition.
… for models trained from scratch as well as pretrained ones, using a variant of the triplet loss to perform end-to-end deep metric learning outperforms most other published methods by a large margin.
— In Defense of the Triplet Loss for Person Re-Identification, 2017.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- Knowledge transfer in learning to recognize visual objects classes, 2006.
- Matching Networks for One Shot Learning, 2017.
- Siamese Neural Networks for One-shot Image Recognition, 2015.
- Signature Verification using a “Siamese” Time Delay Neural Network, 2005.
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification, 2014.
- Dimensionality Reduction by Learning an Invariant Mapping, 2006.
- Deep Face Recognition: A Survey, 2018.
- Deep Learning Face Representation by Joint Identification-Verification, 2014.
- Facenet: A unified embedding for face recognition and clustering, 2015.
- In Defense of the Triplet Loss for Person Re-Identification, 2017.
Articles
Summary
In this post, you discovered the challenge of one-shot learning in face recognition and how comparative and triplet loss functions can be used to learn high-quality face embeddings.
Specifically, you learned:
- One-shot learning are classification tasks where many predictions are required given one (or a few) examples of each class, and face recognition is an example of one-shot learning.
- Siamese networks are an approach to addressing one-shot learning in which a learned feature vector for the known and candidate example are compared.
- Contrastive loss and later triplet loss functions can be used to learn high-quality face embedding vectors that provide the basis for modern face recognition systems.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post One-Shot Learning with Siamese Networks, Contrastive Loss, and Triplet Loss for Face Recognition appeared first on Machine Learning Mastery.