Author: Jason Brownlee
The Pix2Pix Generative Adversarial Network, or GAN, is an approach to training a deep convolutional neural network for image-to-image translation tasks.
The careful configuration of architecture as a type of image-conditional GAN allows for both the generation of large images compared to prior GAN models (e.g. such as 256×256 pixels) and the capability of performing well on a variety of different image-to-image translation tasks.
In this tutorial, you will discover how to develop a Pix2Pix generative adversarial network for image-to-image translation.
After completing this tutorial, you will know:
- How to load and prepare the satellite image to Google maps image-to-image translation dataset.
- How to develop a Pix2Pix model for translating satellite photographs to Google map images.
- How to use the final Pix2Pix generator model to translate ad hoc satellite images.
Discover how to develop DCGANs, conditional GANs, Pix2Pix, CycleGANs, and more with Keras in my new GANs book, with 29 step-by-step tutorials and full source code.
Let’s get started.

How to Develop a Pix2Pix Generative Adversarial Network for Image-to-Image Translation
Photo by European Southern Observatory, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- What Is the Pix2Pix GAN?
- Satellite to Map Image Translation Dataset
- How to Develop and Train a Pix2Pix Model
- How to Translate Images With a Pix2Pix Model
- How to Translate Google Maps to Satellite Images
What Is the Pix2Pix GAN?
Pix2Pix is a Generative Adversarial Network, or GAN, model designed for general purpose image-to-image translation.
The approach was presented by Phillip Isola, et al. in their 2016 paper titled “Image-to-Image Translation with Conditional Adversarial Networks” and presented at CVPR in 2017.
The GAN architecture is comprised of a generator model for outputting new plausible synthetic images, and a discriminator model that classifies images as real (from the dataset) or fake (generated). The discriminator model is updated directly, whereas the generator model is updated via the discriminator model. As such, the two models are trained simultaneously in an adversarial process where the generator seeks to better fool the discriminator and the discriminator seeks to better identify the counterfeit images.
The Pix2Pix model is a type of conditional GAN, or cGAN, where the generation of the output image is conditional on an input, in this case, a source image. The discriminator is provided both with a source image and the target image and must determine whether the target is a plausible transformation of the source image.
The generator is trained via adversarial loss, which encourages the generator to generate plausible images in the target domain. The generator is also updated via L1 loss measured between the generated image and the expected output image. This additional loss encourages the generator model to create plausible translations of the source image.
The Pix2Pix GAN has been demonstrated on a range of image-to-image translation tasks such as converting maps to satellite photographs, black and white photographs to color, and sketches of products to product photographs.
Now that we are familiar with the Pix2Pix GAN, let’s prepare a dataset that we can use with image-to-image translation.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Satellite to Map Image Translation Dataset
In this tutorial, we will use the so-called “maps” dataset used in the Pix2Pix paper.
This is a dataset comprised of satellite images of New York and their corresponding Google maps pages. The image translation problem involves converting satellite photos to Google maps format, or the reverse, Google maps images to Satellite photos.
The dataset is provided on the pix2pix website and can be downloaded as a 255-megabyte zip file.
Download the dataset and unzip it into your current working directory. This will create a directory called “maps” with the following structure:
maps ├── train └── val
The train folder contains 1,097 images, whereas the validation dataset contains 1,099 images.
Images have a digit filename and are in JPEG format. Each image is 1,200 pixels wide and 600 pixels tall and contains both the satellite image on the left and the Google maps image on the right.

Sample Image From the Maps Dataset Including Both Satellite and Google Maps Image.
We can prepare this dataset for training a Pix2Pix GAN model in Keras. We will just work with the images in the training dataset. Each image will be loaded, rescaled, and split into the satellite and Google map elements. The result will be 1,097 color image pairs with the width and height of 256×256 pixels.
The load_images() function below implements this. It enumerates the list of images in a given directory, loads each with the target size of 256×512 pixels, splits each image into satellite and map elements and returns an array of each.
# load all images in a directory into memory def load_images(path, size=(256,512)): src_list, tar_list = list(), list() # enumerate filenames in directory, assume all are images for filename in listdir(path): # load and resize the image pixels = load_img(path + filename, target_size=size) # convert to numpy array pixels = img_to_array(pixels) # split into satellite and map sat_img, map_img = pixels[:, :256], pixels[:, 256:] src_list.append(sat_img) tar_list.append(map_img) return [asarray(src_list), asarray(tar_list)]
We can call this function with the path to the training dataset. Once loaded, we can save the prepared arrays to a new file in compressed format for later use.
The complete example is listed below.
# load, split and scale the maps dataset ready for training
from os import listdir
from numpy import asarray
from numpy import vstack
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import load_img
from numpy import savez_compressed
# load all images in a directory into memory
def load_images(path, size=(256,512)):
src_list, tar_list = list(), list()
# enumerate filenames in directory, assume all are images
for filename in listdir(path):
# load and resize the image
pixels = load_img(path + filename, target_size=size)
# convert to numpy array
pixels = img_to_array(pixels)
# split into satellite and map
sat_img, map_img = pixels[:, :256], pixels[:, 256:]
src_list.append(sat_img)
tar_list.append(map_img)
return [asarray(src_list), asarray(tar_list)]
# dataset path
path = 'maps/train/'
# load dataset
[src_images, tar_images] = load_images(path)
print('Loaded: ', src_images.shape, tar_images.shape)
# save as compressed numpy array
filename = 'maps_256.npz'
savez_compressed(filename, src_images, tar_images)
print('Saved dataset: ', filename)
Running the example loads all images in the training dataset, summarizes their shape to ensure the images were loaded correctly, then saves the arrays to a new file called maps_256.npz in compressed NumPy array format.
Loaded: (1096, 256, 256, 3) (1096, 256, 256, 3) Saved dataset: maps_256.npz
This file can be loaded later via the load() NumPy function and retrieving each array in turn.
We can then plot some images pairs to confirm the data has been handled correctly.
# load the prepared dataset
from numpy import load
from matplotlib import pyplot
# load the face dataset
data = load('maps_256.npz')
src_images, tar_images = data['arr_0'], data['arr_1']
print('Loaded: ', src_images.shape, tar_images.shape)
# plot source images
n_samples = 3
for i in range(n_samples):
pyplot.subplot(2, n_samples, 1 + i)
pyplot.axis('off')
pyplot.imshow(src_images[i].astype('uint8'))
# plot target image
for i in range(n_samples):
pyplot.subplot(2, n_samples, 1 + n_samples + i)
pyplot.axis('off')
pyplot.imshow(tar_images[i].astype('uint8'))
pyplot.show()
Running this example loads the prepared dataset and summarizes the shape of each array, confirming our expectations of a little over one thousand 256×256 image pairs.
Loaded: (1096, 256, 256, 3) (1096, 256, 256, 3)
A plot of three image pairs is also created showing the satellite images on the top and Google map images on the bottom.
We can see that satellite images are quite complex and that although the Google map images are much simpler, they have color codings for things like major roads, water, and parks.

Plot of Three Image Pairs Showing Satellite Images (top) and Google Map Images (bottom).
Now that we have prepared the dataset for image translation, we can develop our Pix2Pix GAN model.
How to Develop and Train a Pix2Pix Model
In this section, we will develop the Pix2Pix model for translating satellite photos to Google maps images.
The same model architecture and configuration described in the paper was used across a range of image translation tasks. This architecture is both described in the body of the paper, with additional detail in the appendix of the paper, and a fully working implementation provided as open source with the Torch deep learning framework.
The implementation in this section will use the Keras deep learning framework based directly on the model described in the paper and implemented in the author’s code base, designed to take and generate color images with the size 256×256 pixels.
The architecture is comprised of two models: the discriminator and the generator.
The discriminator is a deep convolutional neural network that performs image classification. Specifically, conditional-image classification. It takes both the source image (e.g. satellite photo) and the target image (e.g. Google maps image) as input and predicts the likelihood of whether target image is real or a fake translation of the source image.
The discriminator design is based on the effective receptive field of the model, which defines the relationship between one output of the model to the number of pixels in the input image. This is called a PatchGAN model and is carefully designed so that each output prediction of the model maps to a 70×70 square or patch of the input image. The benefit of this approach is that the same model can be applied to input images of different sizes, e.g. larger or smaller than 256×256 pixels.
The output of the model depends on the size of the input image but may be one value or a square activation map of values. Each value is a probability for the likelihood that a patch in the input image is real. These values can be averaged to give an overall likelihood or classification score if needed.
The define_discriminator() function below implements the 70×70 PatchGAN discriminator model as per the design of the model in the paper. The model takes two input images that are concatenated together and predicts a patch output of predictions. The model is optimized using binary cross entropy, and a weighting is used so that updates to the model have half (0.5) the usual effect. The authors of Pix2Pix recommend this weighting of model updates to slow down changes to the discriminator, relative to the generator model during training.
# define the discriminator model
def define_discriminator(image_shape):
# weight initialization
init = RandomNormal(stddev=0.02)
# source image input
in_src_image = Input(shape=image_shape)
# target image input
in_target_image = Input(shape=image_shape)
# concatenate images channel-wise
merged = Concatenate()([in_src_image, in_target_image])
# C64
d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(merged)
d = LeakyReLU(alpha=0.2)(d)
# C128
d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C256
d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C512
d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# second last output layer
d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# patch output
d = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d)
patch_out = Activation('sigmoid')(d)
# define model
model = Model([in_src_image, in_target_image], patch_out)
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt, loss_weights=[0.5])
return model
The generator model is more complex than the discriminator model.
The generator is an encoder-decoder model using a U-Net architecture. The model takes a source image (e.g. satellite photo) and generates a target image (e.g. Google maps image). It does this by first downsampling or encoding the input image down to a bottleneck layer, then upsampling or decoding the bottleneck representation to the size of the output image. The U-Net architecture means that skip-connections are added between the encoding layers and the corresponding decoding layers, forming a U-shape.
The image below makes the skip-connections clear, showing how the first layer of the encoder is connected to the last layer of the decoder, and so on.
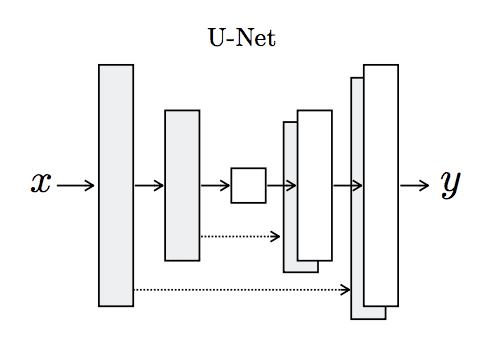
Architecture of the U-Net Generator Model
Taken from Image-to-Image Translation With Conditional Adversarial Networks
The encoder and decoder of the generator are comprised of standardized blocks of convolutional, batch normalization, dropout, and activation layers. This standardization means that we can develop helper functions to create each block of layers and call it repeatedly to build-up the encoder and decoder parts of the model.
The define_generator() function below implements the U-Net encoder-decoder generator model. It uses the define_encoder_block() helper function to create blocks of layers for the encoder and the decoder_block() function to create blocks of layers for the decoder. The tanh activation function is used in the output layer, meaning that pixel values in the generated image will be in the range [-1,1].
# define an encoder block
def define_encoder_block(layer_in, n_filters, batchnorm=True):
# weight initialization
init = RandomNormal(stddev=0.02)
# add downsampling layer
g = Conv2D(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in)
# conditionally add batch normalization
if batchnorm:
g = BatchNormalization()(g, training=True)
# leaky relu activation
g = LeakyReLU(alpha=0.2)(g)
return g
# define a decoder block
def decoder_block(layer_in, skip_in, n_filters, dropout=True):
# weight initialization
init = RandomNormal(stddev=0.02)
# add upsampling layer
g = Conv2DTranspose(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in)
# add batch normalization
g = BatchNormalization()(g, training=True)
# conditionally add dropout
if dropout:
g = Dropout(0.5)(g, training=True)
# merge with skip connection
g = Concatenate()([g, skip_in])
# relu activation
g = Activation('relu')(g)
return g
# define the standalone generator model
def define_generator(image_shape=(256,256,3)):
# weight initialization
init = RandomNormal(stddev=0.02)
# image input
in_image = Input(shape=image_shape)
# encoder model
e1 = define_encoder_block(in_image, 64, batchnorm=False)
e2 = define_encoder_block(e1, 128)
e3 = define_encoder_block(e2, 256)
e4 = define_encoder_block(e3, 512)
e5 = define_encoder_block(e4, 512)
e6 = define_encoder_block(e5, 512)
e7 = define_encoder_block(e6, 512)
# bottleneck, no batch norm and relu
b = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(e7)
b = Activation('relu')(b)
# decoder model
d1 = decoder_block(b, e7, 512)
d2 = decoder_block(d1, e6, 512)
d3 = decoder_block(d2, e5, 512)
d4 = decoder_block(d3, e4, 512, dropout=False)
d5 = decoder_block(d4, e3, 256, dropout=False)
d6 = decoder_block(d5, e2, 128, dropout=False)
d7 = decoder_block(d6, e1, 64, dropout=False)
# output
g = Conv2DTranspose(3, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d7)
out_image = Activation('tanh')(g)
# define model
model = Model(in_image, out_image)
return model
The discriminator model is trained directly on real and generated images, whereas the generator model is not.
Instead, the generator model is trained via the discriminator model. It is updated to minimize the loss predicted by the discriminator for generated images marked as “real.” As such, it is encouraged to generate more real images. The generator is also updated to minimize the L1 loss or mean absolute error between the generated image and the target image.
The generator is updated via a weighted sum of both the adversarial loss and the L1 loss, where the authors of the model recommend a weighting of 100 to 1 in favor of the L1 loss. This is to encourage the generator strongly toward generating plausible translations of the input image, and not just plausible images in the target domain.
This can be achieved by defining a new logical model comprised of the weights in the existing standalone generator and discriminator model. This logical or composite model involves stacking the generator on top of the discriminator. A source image is provided as input to the generator and to the discriminator, although the output of the generator is connected to the discriminator as the corresponding “target” image. The discriminator then predicts the likelihood that the generator was a real translation of the source image.
The discriminator is updated in a standalone manner, so the weights are reused in this composite model but are marked as not trainable. The composite model is updated with two targets, one indicating that the generated images were real (cross entropy loss), forcing large weight updates in the generator toward generating more realistic images, and the executed real translation of the image, which is compared against the output of the generator model (L1 loss).
The define_gan() function below implements this, taking the already-defined generator and discriminator models as arguments and using the Keras functional API to connect them together into a composite model. Both loss functions are specified for the two outputs of the model and the weights used for each are specified in the loss_weights argument to the compile() function.
# define the combined generator and discriminator model, for updating the generator def define_gan(g_model, d_model, image_shape): # make weights in the discriminator not trainable d_model.trainable = False # define the source image in_src = Input(shape=image_shape) # connect the source image to the generator input gen_out = g_model(in_src) # connect the source input and generator output to the discriminator input dis_out = d_model([in_src, gen_out]) # src image as input, generated image and classification output model = Model(in_src, [dis_out, gen_out]) # compile model opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss=['binary_crossentropy', 'mae'], optimizer=opt, loss_weights=[1,100]) return model
Next, we can load our paired images dataset in compressed NumPy array format.
This will return a list of two NumPy arrays: the first for source images and the second for corresponding target images.
# load and prepare training images def load_real_samples(filename): # load compressed arrays data = load(filename) # unpack arrays X1, X2 = data['arr_0'], data['arr_1'] # scale from [0,255] to [-1,1] X1 = (X1 - 127.5) / 127.5 X2 = (X2 - 127.5) / 127.5 return [X1, X2]
Training the discriminator will require batches of real and fake images.
The generate_real_samples() function below will prepare a batch of random pairs of images from the training dataset, and the corresponding discriminator label of class=1 to indicate they are real.
# select a batch of random samples, returns images and target def generate_real_samples(dataset, n_samples, patch_shape): # unpack dataset trainA, trainB = dataset # choose random instances ix = randint(0, trainA.shape[0], n_samples) # retrieve selected images X1, X2 = trainA[ix], trainB[ix] # generate 'real' class labels (1) y = ones((n_samples, patch_shape, patch_shape, 1)) return [X1, X2], y
The generate_fake_samples() function below uses the generator model and a batch of real source images to generate an equivalent batch of target images for the discriminator.
These are returned with the label class-0 to indicate to the discriminator that they are fake.
# generate a batch of images, returns images and targets def generate_fake_samples(g_model, samples, patch_shape): # generate fake instance X = g_model.predict(samples) # create 'fake' class labels (0) y = zeros((len(X), patch_shape, patch_shape, 1)) return X, y
Typically, GAN models do not converge; instead, an equilibrium is found between the generator and discriminator models. As such, we cannot easily judge when training should stop. Therefore, we can save the model and use it to generate sample image-to-image translations periodically during training, such as every 10 training epochs.
We can then review the generated images at the end of training and use the image quality to choose a final model.
The summarize_performance() function implements this, taking the generator model at a point during training and using it to generate a number, in this case three, of translations of randomly selected images in the dataset. The source, generated image, and expected target are then plotted as three rows of images and the plot saved to file. Additionally, the model is saved to an H5 formatted file that makes it easier to load later.
Both the image and model filenames include the training iteration number, allowing us to easily tell them apart at the end of training.
# generate samples and save as a plot and save the model
def summarize_performance(step, g_model, dataset, n_samples=3):
# select a sample of input images
[X_realA, X_realB], _ = generate_real_samples(dataset, n_samples, 1)
# generate a batch of fake samples
X_fakeB, _ = generate_fake_samples(g_model, X_realA, 1)
# scale all pixels from [-1,1] to [0,1]
X_realA = (X_realA + 1) / 2.0
X_realB = (X_realB + 1) / 2.0
X_fakeB = (X_fakeB + 1) / 2.0
# plot real source images
for i in range(n_samples):
pyplot.subplot(3, n_samples, 1 + i)
pyplot.axis('off')
pyplot.imshow(X_realA[i])
# plot generated target image
for i in range(n_samples):
pyplot.subplot(3, n_samples, 1 + n_samples + i)
pyplot.axis('off')
pyplot.imshow(X_fakeB[i])
# plot real target image
for i in range(n_samples):
pyplot.subplot(3, n_samples, 1 + n_samples*2 + i)
pyplot.axis('off')
pyplot.imshow(X_realB[i])
# save plot to file
filename1 = 'plot_%06d.png' % (step+1)
pyplot.savefig(filename1)
pyplot.close()
# save the generator model
filename2 = 'model_%06d.h5' % (step+1)
g_model.save(filename2)
print('>Saved: %s and %s' % (filename1, filename2))
Finally, we can train the generator and discriminator models.
The train() function below implements this, taking the defined generator, discriminator, composite model, and loaded dataset as input. The number of epochs is set at 100 to keep training times down, although 200 was used in the paper. A batch size of 1 is used as is recommended in the paper.
Training involves a fixed number of training iterations. There are 1,097 images in the training dataset. One epoch is one iteration through this number of examples, with a batch size of one means 1,097 training steps. The generator is saved and evaluated every 10 epochs or every 10,097 training steps, and the model will run for 100 epochs, or a total of 100,097 training steps.
Each training step involves first selecting a batch of real examples, then using the generator to generate a batch of matching fake samples using the real source images. The discriminator is then updated with the batch of real images and then fake images.
Next, the generator model is updated providing the real source images as input and providing class labels of 1 (real) and the real target images as the expected outputs of the model required for calculating loss. The generator has two loss scores as well as the weighted sum score returned from the call to train_on_batch(). We are only interested in the weighted sum score (the first value returned) as it is used to update the model weights.
Finally, the loss for each update is reported to the console each training iteration and model performance is evaluated every 10 training epochs.
# train pix2pix model
def train(d_model, g_model, gan_model, dataset, n_epochs=100, n_batch=1):
# determine the output square shape of the discriminator
n_patch = d_model.output_shape[1]
# unpack dataset
trainA, trainB = dataset
# calculate the number of batches per training epoch
bat_per_epo = int(len(trainA) / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# manually enumerate epochs
for i in range(n_steps):
# select a batch of real samples
[X_realA, X_realB], y_real = generate_real_samples(dataset, n_batch, n_patch)
# generate a batch of fake samples
X_fakeB, y_fake = generate_fake_samples(g_model, X_realA, n_patch)
# update discriminator for real samples
d_loss1 = d_model.train_on_batch([X_realA, X_realB], y_real)
# update discriminator for generated samples
d_loss2 = d_model.train_on_batch([X_realA, X_fakeB], y_fake)
# update the generator
g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB])
# summarize performance
print('>%d, d1[%.3f] d2[%.3f] g[%.3f]' % (i+1, d_loss1, d_loss2, g_loss))
# summarize model performance
if (i+1) % (bat_per_epo * 10) == 0:
summarize_performance(i, g_model, dataset)
Tying all of this together, the complete code example of training a Pix2Pix GAN to translate satellite photos to Google maps images is listed below.
# example of pix2pix gan for satellite to map image-to-image translation
from numpy import load
from numpy import zeros
from numpy import ones
from numpy.random import randint
from keras.optimizers import Adam
from keras.initializers import RandomNormal
from keras.models import Model
from keras.models import Input
from keras.layers import Conv2D
from keras.layers import Conv2DTranspose
from keras.layers import LeakyReLU
from keras.layers import Activation
from keras.layers import Concatenate
from keras.layers import Dropout
from keras.layers import BatchNormalization
from keras.layers import LeakyReLU
from matplotlib import pyplot
# define the discriminator model
def define_discriminator(image_shape):
# weight initialization
init = RandomNormal(stddev=0.02)
# source image input
in_src_image = Input(shape=image_shape)
# target image input
in_target_image = Input(shape=image_shape)
# concatenate images channel-wise
merged = Concatenate()([in_src_image, in_target_image])
# C64
d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(merged)
d = LeakyReLU(alpha=0.2)(d)
# C128
d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C256
d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# C512
d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# second last output layer
d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d)
d = BatchNormalization()(d)
d = LeakyReLU(alpha=0.2)(d)
# patch output
d = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d)
patch_out = Activation('sigmoid')(d)
# define model
model = Model([in_src_image, in_target_image], patch_out)
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt, loss_weights=[0.5])
return model
# define an encoder block
def define_encoder_block(layer_in, n_filters, batchnorm=True):
# weight initialization
init = RandomNormal(stddev=0.02)
# add downsampling layer
g = Conv2D(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in)
# conditionally add batch normalization
if batchnorm:
g = BatchNormalization()(g, training=True)
# leaky relu activation
g = LeakyReLU(alpha=0.2)(g)
return g
# define a decoder block
def decoder_block(layer_in, skip_in, n_filters, dropout=True):
# weight initialization
init = RandomNormal(stddev=0.02)
# add upsampling layer
g = Conv2DTranspose(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in)
# add batch normalization
g = BatchNormalization()(g, training=True)
# conditionally add dropout
if dropout:
g = Dropout(0.5)(g, training=True)
# merge with skip connection
g = Concatenate()([g, skip_in])
# relu activation
g = Activation('relu')(g)
return g
# define the standalone generator model
def define_generator(image_shape=(256,256,3)):
# weight initialization
init = RandomNormal(stddev=0.02)
# image input
in_image = Input(shape=image_shape)
# encoder model
e1 = define_encoder_block(in_image, 64, batchnorm=False)
e2 = define_encoder_block(e1, 128)
e3 = define_encoder_block(e2, 256)
e4 = define_encoder_block(e3, 512)
e5 = define_encoder_block(e4, 512)
e6 = define_encoder_block(e5, 512)
e7 = define_encoder_block(e6, 512)
# bottleneck, no batch norm and relu
b = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(e7)
b = Activation('relu')(b)
# decoder model
d1 = decoder_block(b, e7, 512)
d2 = decoder_block(d1, e6, 512)
d3 = decoder_block(d2, e5, 512)
d4 = decoder_block(d3, e4, 512, dropout=False)
d5 = decoder_block(d4, e3, 256, dropout=False)
d6 = decoder_block(d5, e2, 128, dropout=False)
d7 = decoder_block(d6, e1, 64, dropout=False)
# output
g = Conv2DTranspose(3, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d7)
out_image = Activation('tanh')(g)
# define model
model = Model(in_image, out_image)
return model
# define the combined generator and discriminator model, for updating the generator
def define_gan(g_model, d_model, image_shape):
# make weights in the discriminator not trainable
d_model.trainable = False
# define the source image
in_src = Input(shape=image_shape)
# connect the source image to the generator input
gen_out = g_model(in_src)
# connect the source input and generator output to the discriminator input
dis_out = d_model([in_src, gen_out])
# src image as input, generated image and classification output
model = Model(in_src, [dis_out, gen_out])
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss=['binary_crossentropy', 'mae'], optimizer=opt, loss_weights=[1,100])
return model
# load and prepare training images
def load_real_samples(filename):
# load compressed arrays
data = load(filename)
# unpack arrays
X1, X2 = data['arr_0'], data['arr_1']
# scale from [0,255] to [-1,1]
X1 = (X1 - 127.5) / 127.5
X2 = (X2 - 127.5) / 127.5
return [X1, X2]
# select a batch of random samples, returns images and target
def generate_real_samples(dataset, n_samples, patch_shape):
# unpack dataset
trainA, trainB = dataset
# choose random instances
ix = randint(0, trainA.shape[0], n_samples)
# retrieve selected images
X1, X2 = trainA[ix], trainB[ix]
# generate 'real' class labels (1)
y = ones((n_samples, patch_shape, patch_shape, 1))
return [X1, X2], y
# generate a batch of images, returns images and targets
def generate_fake_samples(g_model, samples, patch_shape):
# generate fake instance
X = g_model.predict(samples)
# create 'fake' class labels (0)
y = zeros((len(X), patch_shape, patch_shape, 1))
return X, y
# generate samples and save as a plot and save the model
def summarize_performance(step, g_model, dataset, n_samples=3):
# select a sample of input images
[X_realA, X_realB], _ = generate_real_samples(dataset, n_samples, 1)
# generate a batch of fake samples
X_fakeB, _ = generate_fake_samples(g_model, X_realA, 1)
# scale all pixels from [-1,1] to [0,1]
X_realA = (X_realA + 1) / 2.0
X_realB = (X_realB + 1) / 2.0
X_fakeB = (X_fakeB + 1) / 2.0
# plot real source images
for i in range(n_samples):
pyplot.subplot(3, n_samples, 1 + i)
pyplot.axis('off')
pyplot.imshow(X_realA[i])
# plot generated target image
for i in range(n_samples):
pyplot.subplot(3, n_samples, 1 + n_samples + i)
pyplot.axis('off')
pyplot.imshow(X_fakeB[i])
# plot real target image
for i in range(n_samples):
pyplot.subplot(3, n_samples, 1 + n_samples*2 + i)
pyplot.axis('off')
pyplot.imshow(X_realB[i])
# save plot to file
filename1 = 'plot_%06d.png' % (step+1)
pyplot.savefig(filename1)
pyplot.close()
# save the generator model
filename2 = 'model_%06d.h5' % (step+1)
g_model.save(filename2)
print('>Saved: %s and %s' % (filename1, filename2))
# train pix2pix models
def train(d_model, g_model, gan_model, dataset, n_epochs=100, n_batch=1):
# determine the output square shape of the discriminator
n_patch = d_model.output_shape[1]
# unpack dataset
trainA, trainB = dataset
# calculate the number of batches per training epoch
bat_per_epo = int(len(trainA) / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# manually enumerate epochs
for i in range(n_steps):
# select a batch of real samples
[X_realA, X_realB], y_real = generate_real_samples(dataset, n_batch, n_patch)
# generate a batch of fake samples
X_fakeB, y_fake = generate_fake_samples(g_model, X_realA, n_patch)
# update discriminator for real samples
d_loss1 = d_model.train_on_batch([X_realA, X_realB], y_real)
# update discriminator for generated samples
d_loss2 = d_model.train_on_batch([X_realA, X_fakeB], y_fake)
# update the generator
g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB])
# summarize performance
print('>%d, d1[%.3f] d2[%.3f] g[%.3f]' % (i+1, d_loss1, d_loss2, g_loss))
# summarize model performance
if (i+1) % (bat_per_epo * 10) == 0:
summarize_performance(i, g_model, dataset)
# load image data
dataset = load_real_samples('maps_256.npz')
print('Loaded', dataset[0].shape, dataset[1].shape)
# define input shape based on the loaded dataset
image_shape = dataset[0].shape[1:]
# define the models
d_model = define_discriminator(image_shape)
g_model = define_generator(image_shape)
# define the composite model
gan_model = define_gan(g_model, d_model, image_shape)
# train model
train(d_model, g_model, gan_model, dataset)
The example can be run on CPU hardware, although GPU hardware is recommended.
The example might take about two hours to run on modern GPU hardware.
Note: your specific results may vary given the stochastic nature of the learning algorithm. Consider running the example a few times.
The loss is reported each training iteration, including the discriminator loss on real examples (d1), discriminator loss on generated or fake examples (d2), and generator loss, which is a weighted average of adversarial and L1 loss (g).
If loss for the discriminator goes to zero and stays there for a long time, consider re-starting the training run as it is an example of a training failure.
>1, d1[0.566] d2[0.520] g[82.266] >2, d1[0.469] d2[0.484] g[66.813] >3, d1[0.428] d2[0.477] g[79.520] >4, d1[0.362] d2[0.405] g[78.143] >5, d1[0.416] d2[0.406] g[72.452] ... >109596, d1[0.303] d2[0.006] g[5.792] >109597, d1[0.001] d2[1.127] g[14.343] >109598, d1[0.000] d2[0.381] g[11.851] >109599, d1[1.289] d2[0.547] g[6.901] >109600, d1[0.437] d2[0.005] g[10.460] >Saved: plot_109600.png and model_109600.h5
Models are saved every 10 epochs and saved to a file with the training iteration number. Additionally, images are generated every 10 epochs and compared to the expected target images. These plots can be assessed at the end of the run and used to select a final generator model based on generated image quality.
At the end of the run, will you will have 10 saved model files and 10 plots of generated images.
After the first 10 epochs, map images are generated that look plausible, although the lines for streets are not entirely straight and images contain some blurring. Nevertheless, large structures are in the right places with mostly the right colors.

Plot of Satellite to Google Map Translated Images Using Pix2Pix After 10 Training Epochs
Generated images after about 50 training epochs begin to look very realistic, at least to mean, and quality appears to remain good for the remainder of the training process.
Note the first generated image example below (right column, middle row) that includes more useful detail than the real Google map image.

Plot of Satellite to Google Map Translated Images Using Pix2Pix After 100 Training Epochs
Now that we have developed and trained the Pix2Pix model, we can explore how they can be used in a standalone manner.
How to Translate Images With a Pix2Pix Model
Training the Pix2Pix model results in many saved models and samples of generated images for each.
More training epochs does not necessarily mean a better quality model. Therefore, we can choose a model based on the quality of the generated images and use it to perform ad hoc image-to-image translation.
In this case, we will use the model saved at the end of the run, e.g. after 10 epochs or 109,600 training iterations.
A good starting point is to load the model and use it to make ad hoc translations of source images in the training dataset.
First, we can load the training dataset. We can use the same function named load_real_samples() for loading the dataset as was used when training the model.
# load and prepare training images def load_real_samples(filename): # load compressed ararys data = load(filename) # unpack arrays X1, X2 = data['arr_0'], data['arr_1'] # scale from [0,255] to [-1,1] X1 = (X1 - 127.5) / 127.5 X2 = (X2 - 127.5) / 127.5 return [X1, X2]
This function can be called as follows:
...
# load dataset
[X1, X2] = load_real_samples('maps_256.npz')
print('Loaded', X1.shape, X2.shape)
Next, we can load the saved Keras model.
...
# load model
model = load_model('model_109600.h5')
Next, we can choose a random image pair from the training dataset to use as an example.
... # select random example ix = randint(0, len(X1), 1) src_image, tar_image = X1[ix], X2[ix]
We can provide the source satellite image as input to the model and use it to predict a Google map image.
... # generate image from source gen_image = model.predict(src_image)
Finally, we can plot the source, generated image, and the expected target image.
The plot_images() function below implements this, providing a nice title above each image.
# plot source, generated and target images
def plot_images(src_img, gen_img, tar_img):
images = vstack((src_img, gen_img, tar_img))
# scale from [-1,1] to [0,1]
images = (images + 1) / 2.0
titles = ['Source', 'Generated', 'Expected']
# plot images row by row
for i in range(len(images)):
# define subplot
pyplot.subplot(1, 3, 1 + i)
# turn off axis
pyplot.axis('off')
# plot raw pixel data
pyplot.imshow(images[i])
# show title
pyplot.title(titles[i])
pyplot.show()
This function can be called with each of our source, generated, and target images.
... # plot all three images plot_images(src_image, gen_image, tar_image)
Tying all of this together, the complete example of performing an ad hoc image-to-image translation with an example from the training dataset is listed below.
# example of loading a pix2pix model and using it for image to image translation
from keras.models import load_model
from numpy import load
from numpy import vstack
from matplotlib import pyplot
from numpy.random import randint
# load and prepare training images
def load_real_samples(filename):
# load compressed arrays
data = load(filename)
# unpack arrays
X1, X2 = data['arr_0'], data['arr_1']
# scale from [0,255] to [-1,1]
X1 = (X1 - 127.5) / 127.5
X2 = (X2 - 127.5) / 127.5
return [X1, X2]
# plot source, generated and target images
def plot_images(src_img, gen_img, tar_img):
images = vstack((src_img, gen_img, tar_img))
# scale from [-1,1] to [0,1]
images = (images + 1) / 2.0
titles = ['Source', 'Generated', 'Expected']
# plot images row by row
for i in range(len(images)):
# define subplot
pyplot.subplot(1, 3, 1 + i)
# turn off axis
pyplot.axis('off')
# plot raw pixel data
pyplot.imshow(images[i])
# show title
pyplot.title(titles[i])
pyplot.show()
# load dataset
[X1, X2] = load_real_samples('maps_256.npz')
print('Loaded', X1.shape, X2.shape)
# load model
model = load_model('model_109600.h5')
# select random example
ix = randint(0, len(X1), 1)
src_image, tar_image = X1[ix], X2[ix]
# generate image from source
gen_image = model.predict(src_image)
# plot all three images
plot_images(src_image, gen_image, tar_image)
Running the example will select a random image from the training dataset, translate it to a Google map, and plot the result compared to the expected image.
Your specific results will vary; try running the example a few times.
In this case, we can see that the generated image captures large roads with orange and yellow as well as green park areas. The generated image is not perfect but is very close to the expected image.
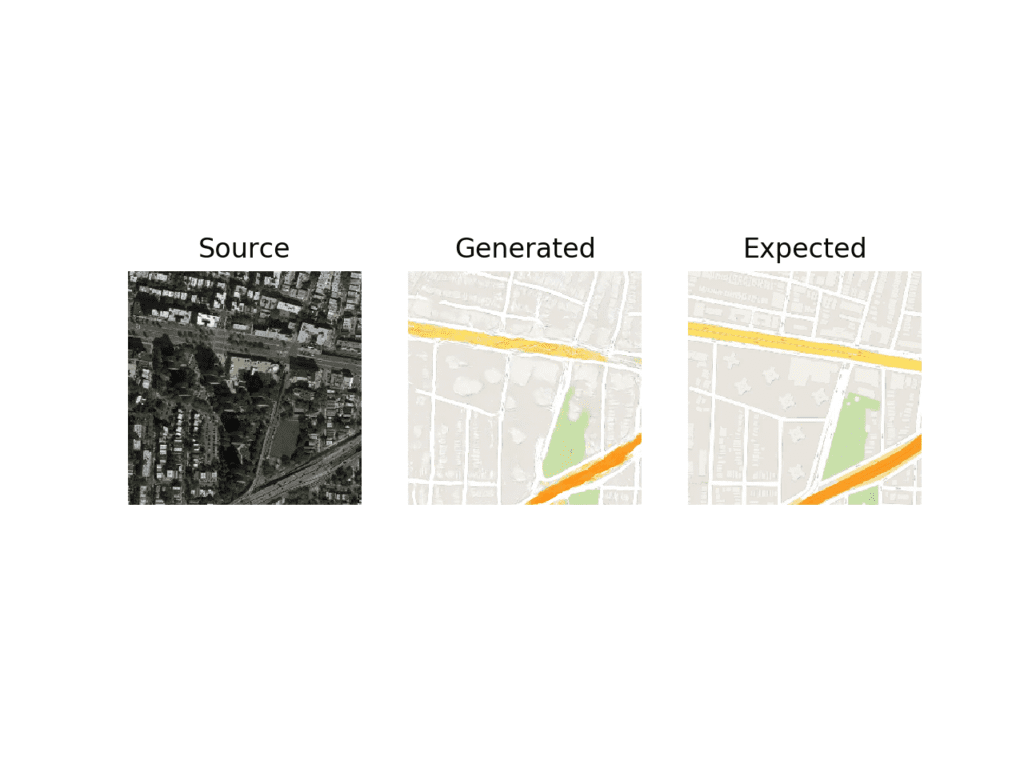
Plot of Satellite to Google Map Image Translation With Final Pix2Pix GAN Model
We may also want to use the model to translate a given standalone image.
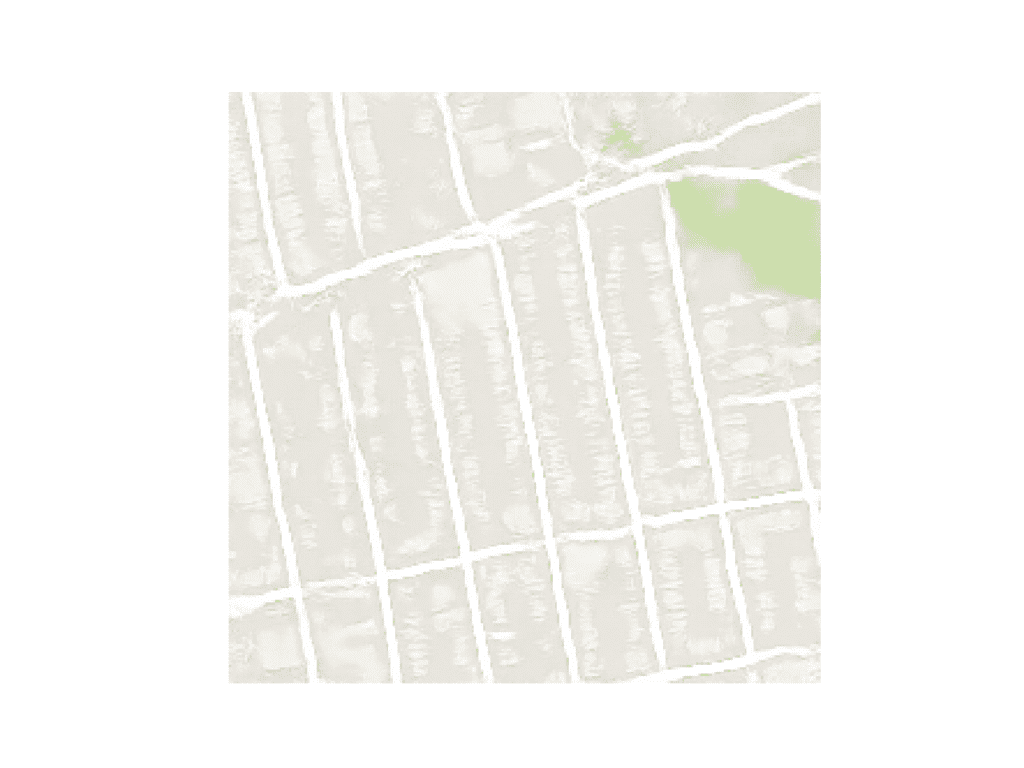
We can select an image from the validation dataset under maps/val and crop the satellite element of the image. This can then be saved and used as input to the model.
In this case, we will use “maps/val/1.jpg“.
Example Image From the Validation Part of the Maps Dataset
We can use an image program to create a rough crop of the satellite element of this image to use as input and save the file as satellite.jpg in the current working directory.
Example of a Cropped Satellite Image to Use as Input to the Pix2Pix Model.
We must load the image as a NumPy array of pixels with the size of 256×256, rescale the pixel values to the range [-1,1], and then expand the single image dimensions to represent one input sample.
The load_image() function below implements this, returning image pixels that can be provided directly to a loaded Pix2Pix model.
# load an image def load_image(filename, size=(256,256)): # load image with the preferred size pixels = load_img(filename, target_size=size) # convert to numpy array pixels = img_to_array(pixels) # scale from [0,255] to [-1,1] pixels = (pixels - 127.5) / 127.5 # reshape to 1 sample pixels = expand_dims(pixels, 0) return pixels
We can then load our cropped satellite image.
...
# load source image
src_image = load_image('satellite.jpg')
print('Loaded', src_image.shape)
As before, we can load our saved Pix2Pix generator model and generate a translation of the loaded image.
...
# load model
model = load_model('model_109600.h5')
# generate image from source
gen_image = model.predict(src_image)
Finally, we can scale the pixel values back to the range [0,1] and plot the result.
...
# scale from [-1,1] to [0,1]
gen_image = (gen_image + 1) / 2.0
# plot the image
pyplot.imshow(gen_image[0])
pyplot.axis('off')
pyplot.show()
Tying this all together, the complete example of performing an ad hoc image translation with a single image file is listed below.
# example of loading a pix2pix model and using it for one-off image translation
from keras.models import load_model
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import load_img
from numpy import load
from numpy import expand_dims
from matplotlib import pyplot
# load an image
def load_image(filename, size=(256,256)):
# load image with the preferred size
pixels = load_img(filename, target_size=size)
# convert to numpy array
pixels = img_to_array(pixels)
# scale from [0,255] to [-1,1]
pixels = (pixels - 127.5) / 127.5
# reshape to 1 sample
pixels = expand_dims(pixels, 0)
return pixels
# load source image
src_image = load_image('satellite.jpg')
print('Loaded', src_image.shape)
# load model
model = load_model('model_109600.h5')
# generate image from source
gen_image = model.predict(src_image)
# scale from [-1,1] to [0,1]
gen_image = (gen_image + 1) / 2.0
# plot the image
pyplot.imshow(gen_image[0])
pyplot.axis('off')
pyplot.show()
Running the example loads the image from file, creates a translation of it, and plots the result.
The generated image appears to be a reasonable translation of the source image.
The streets do not appear to be straight lines and the detail of the buildings is a bit lacking. Perhaps with further training or choice of a different model, higher-quality images could be generated.
Plot of Satellite Image Translated to Google Maps With Final Pix2Pix GAN Model
How to Translate Google Maps to Satellite Images
Now that we are familiar with how to develop and use a Pix2Pix model for translating satellite images to Google maps, we can also explore the reverse.
That is, we can develop a Pix2Pix model to translate Google map images to plausible satellite images. This requires that the model invent or hallucinate plausible buildings, roads, parks, and more.
We can use the same code to train the model with one small difference. We can change the order of the datasets returned from the load_real_samples() function; for example:
# load and prepare training images def load_real_samples(filename): # load compressed arrays data = load(filename) # unpack arrays X1, X2 = data['arr_0'], data['arr_1'] # scale from [0,255] to [-1,1] X1 = (X1 - 127.5) / 127.5 X2 = (X2 - 127.5) / 127.5 # return in reverse order return [X2, X1]
Note: the order of X1 and X2 is reversed.
This means that the model will take Google map images as input and learn to generate satellite images.
Run the example as before.
Note: your specific results may vary given the stochastic nature of the learning algorithm. Consider running the example a few times.
As before, the loss of the model is reported each training iteration. If loss for the discriminator goes to zero and stays there for a long time, consider re-starting the training run as it is an example of a training failure.
>1, d1[0.442] d2[0.650] g[49.790] >2, d1[0.317] d2[0.478] g[56.476] >3, d1[0.376] d2[0.450] g[48.114] >4, d1[0.396] d2[0.406] g[62.903] >5, d1[0.496] d2[0.460] g[40.650] ... >109596, d1[0.311] d2[0.057] g[25.376] >109597, d1[0.028] d2[0.070] g[16.618] >109598, d1[0.007] d2[0.208] g[18.139] >109599, d1[0.358] d2[0.076] g[22.494] >109600, d1[0.279] d2[0.049] g[9.941] >Saved: plot_109600.png and model_109600.h5
It is harder to judge the quality of generated satellite images, nevertheless, plausible images are generated after just 10 epochs.

Plot of Google Map to Satellite Translated Images Using Pix2Pix After 10 Training Epochs
As before, image quality will improve and will continue to vary over the training process. A final model can be chosen based on generated image quality, not total training epochs.
The model appears to have little difficulty in generating reasonable water, parks, roads, and more.

Plot of Google Map to Satellite Translated Images Using Pix2Pix After 90 Training Epochs
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Standalone Satellite. Develop an example of translating standalone Google map images to satellite images, as we did for satellite to Google map images.
- New Image. Locate a satellite image for an entirely new location and translate it to a Google map and consider the result compared to the actual image in Google maps.
- More Training. Continue training the model for another 100 epochs and evaluate whether the additional training results in further improvements in image quality.
- Image Augmentation. Use some minor image augmentation during training as described in the Pix2Pix paper and evaluate whether it results in better quality generated images.
If you explore any of these extensions, I’d love to know.
Post your findings in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Official
- Image-to-Image Translation with Conditional Adversarial Networks, 2016.
- Image-to-Image Translation with Conditional Adversarial Nets, Homepage.
- Image-to-image translation with conditional adversarial nets, GitHub.
- pytorch-CycleGAN-and-pix2pix, GitHub.
- Interactive Image-to-Image Demo, 2017.
- Pix2Pix Datasets
API
- Keras Datasets API.
- Keras Sequential Model API
- Keras Convolutional Layers API
- How can I “freeze” Keras layers?
Summary
In this tutorial, you discovered how to develop a Pix2Pix generative adversarial network for image-to-image translation.
Specifically, you learned:
- How to load and prepare the satellite image to Google maps image-to-image translation dataset.
- How to develop a Pix2Pix model for translating satellite photographs to Google map images.
- How to use the final Pix2Pix generator model to translate ad hoc satellite images.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Develop a Pix2Pix GAN for Image-to-Image Translation appeared first on Machine Learning Mastery.