
Author: Jason Brownlee
The progressive growing generative adversarial network is an approach for training a deep convolutional neural network model for generating synthetic images.
It is an extension of the more traditional GAN architecture that involves incrementally growing the size of the generated image during training, starting with a very small image, such as a 4×4 pixels. This allows the stable training and growth of GAN models capable of generating very large high-quality images, such as images of synthetic celebrity faces with the size of 1024×1024 pixels.
In this tutorial, you will discover how to develop progressive growing generative adversarial network models from scratch with Keras.
After completing this tutorial, you will know:
- How to develop pre-defined discriminator and generator models at each level of output image growth.
- How to define composite models for training the generator models via the discriminator models.
- How to cycle the training of fade-in version and normal versions of models at each level of output image growth.
Discover how to develop DCGANs, conditional GANs, Pix2Pix, CycleGANs, and more with Keras in my new GANs book, with 29 step-by-step tutorials and full source code.
Let’s get started.

How to Implement Progressive Growing GAN Models in Keras
Photo by Diogo Santos Silva, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- What Is the Progressive Growing GAN Architecture?
- How to Implement the Progressive Growing GAN Discriminator Model
- How to Implement the Progressive Growing GAN Generator Model
- How to Implement Composite Models for Updating the Generator
- How to Train Discriminator and Generator Models
What Is the Progressive Growing GAN Architecture?
GANs are effective at generating crisp synthetic images, although are typically limited in the size of the images that can be generated.
The Progressive Growing GAN is an extension to the GAN that allows the training of generator models capable of outputting large high-quality images, such as photorealistic faces with the size 1024×1024 pixels. It was described in the 2017 paper by Tero Karras, et al. from Nvidia titled “Progressive Growing of GANs for Improved Quality, Stability, and Variation.”
The key innovation of the Progressive Growing GAN is the incremental increase in the size of images output by the generator starting with a 4×4 pixel image and double to 8×8, 16×16, and so on until the desired output resolution.
Our primary contribution is a training methodology for GANs where we start with low-resolution images, and then progressively increase the resolution by adding layers to the networks.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
This is achieved by a training procedure that involves periods of fine-tuning the model with a given output resolution, and periods of slowly phasing in a new model with a larger resolution.
When doubling the resolution of the generator (G) and discriminator (D) we fade in the new layers smoothly
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
All layers remain trainable during the training process, including existing layers when new layers are added.
All existing layers in both networks remain trainable throughout the training process.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Progressive Growing GAN involves using a generator and discriminator model with the same general structure and starting with very small images. During training, new blocks of convolutional layers are systematically added to both the generator model and the discriminator models.
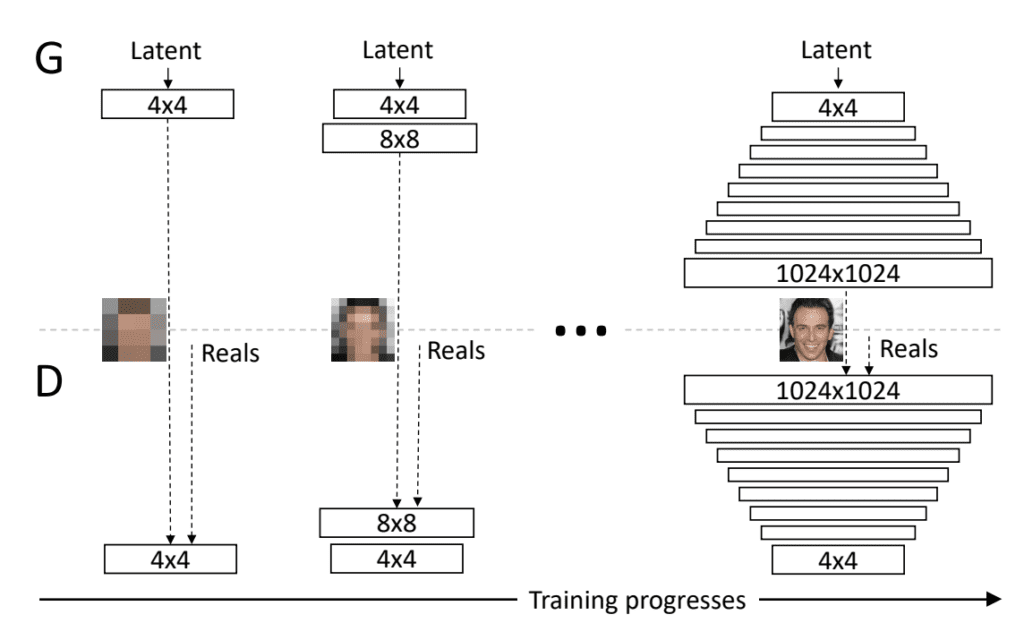
Example of Progressively Adding Layers to Generator and Discriminator Models.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
The incremental addition of the layers allows the models to effectively learn coarse-level detail and later learn ever finer detail, both on the generator and discriminator side.
This incremental nature allows the training to first discover the large-scale structure of the image distribution and then shift attention to increasingly finer-scale detail, instead of having to learn all scales simultaneously.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
The model architecture is complex and cannot be implemented directly.
In this tutorial, we will focus on how the progressive growing GAN can be implemented using the Keras deep learning library.
We will step through how each of the discriminator and generator models can be defined, how the generator can be trained via the discriminator model, and how each model can be updated during the training process.
These implementation details will provide the basis for you developing a progressive growing GAN for your own applications.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
How to Implement the Progressive Growing GAN Discriminator Model
The discriminator model is given images as input and must classify them as either real (from the dataset) or fake (generated).
During the training process, the discriminator must grow to support images with ever-increasing size, starting with 4×4 pixel color images and doubling to 8×8, 16×16, 32×32, and so on.
This is achieved by inserting a new input layer to support the larger input image followed by a new block of layers. The output of this new block is then downsampled. Additionally, the new image is also downsampled directly and passed through the old input processing layer before it is combined with the output of the new block.
During the transition from a lower resolution to a higher resolution, e.g. 16×16 to 32×32, the discriminator model will have two input pathways as follows:
- [32×32 Image] -> [fromRGB Conv] -> [NewBlock] -> [Downsample] ->
- [32×32 Image] -> [Downsample] -> [fromRGB Conv] ->
The output of the new block that is downsampled and the output of the old input processing layer are combined using a weighted average, where the weighting is controlled by a new hyperparameter called alpha. The weighted sum is calculated as follows:
- Output = ((1 – alpha) * fromRGB) + (alpha * NewBlock)
The weighted average of the two pathways is then fed into the rest of the existing model.
Initially, the weighting is completely biased towards the old input processing layer (alpha=0) and is linearly increased over training iterations so that the new block is given more weight until eventually, the output is entirely the product of the new block (alpha=1). At this time, the old pathway can be removed.
This can be summarized with the following figure taken from the paper showing a model before growing (a), during the phase-in of the larger resolution (b), and the model after the phase-in (c).
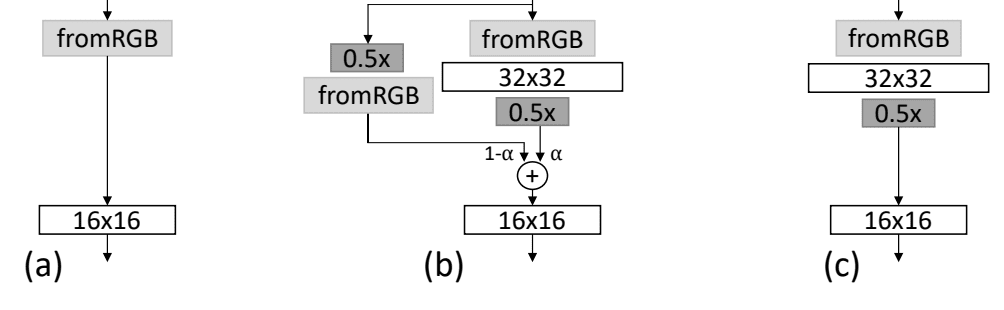
Figure Showing the Growing of the Discriminator Model, Before (a) During (b) and After (c) the Phase-In of a High Resolution.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
The fromRGB layers are implemented as a 1×1 convolutional layer. A block is comprised of two convolutional layers with 3×3 sized filters and the leaky ReLU activation function with a slope of 0.2, followed by a downsampling layer. Average pooling is used for downsampling, which is unlike most other GAN models that use transpose convolutional layers.
The output of the model involves two convolutional layers with 3×3 and 4×4 sized filters and Leaky ReLU activation, followed by a fully connected layer that outputs the single value prediction. The model uses a linear activation function instead of a sigmoid activation function like other discriminator models and is trained directly either by Wasserstein loss (specifically WGAN-GP) or least squares loss; we will use the latter in this tutorial. Model weights are initialized using He Gaussian (he_normal), which is very similar to the method used in the paper.
The model uses a custom layer called Minibatch standard deviation at the beginning of the output block, and instead of batch normalization, each layer uses local response normalization, referred to as pixel-wise normalization in the paper. We will leave out the minibatch normalization and use batch normalization in this tutorial for brevity.
One approach to implementing the progressive growing GAN would be to manually expand a model on demand during training. Another approach is to pre-define all of the models prior to training and carefully use the Keras functional API to ensure that layers are shared across the models and continue training.
I believe the latter approach might be easier and is the approach we will use in this tutorial.
First, we must define a custom layer that we can use when fading in a new higher-resolution input image and block. This new layer must take two sets of activation maps with the same dimensions (width, height, channels) and add them together using a weighted sum.
We can implement this as a new layer called WeightedSum that extends the Add merge layer and uses a hyperparameter ‘alpha‘ to control the contribution of each input. This new class is defined below. The layer assumes only two inputs: the first for the output of the old or existing layers and the second for the newly added layers. The new hyperparameter is defined as a backend variable, meaning that we can change it any time via changing the value of the variable.
# weighted sum output class WeightedSum(Add): # init with default value def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # output a weighted sum of inputs def _merge_function(self, inputs): # only supports a weighted sum of two inputs assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output
The discriminator model is by far more complex than the generator to grow because we have to change the model input, so let’s step through this slowly.
Firstly, we can define a discriminator model that takes a 4×4 color image as input and outputs a prediction of whether the image is real or fake. The model is comprised of a 1×1 input processing layer (fromRGB) and an output block.
... # base model input in_image = Input(shape=(4,4,3)) # conv 1x1 g = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) g = LeakyReLU(alpha=0.2)(g) # conv 3x3 (output block) g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 4x4 g = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # dense output layer g = Flatten()(g) out_class = Dense(1)(g) # define model model = Model(in_image, out_class) # compile model model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
Next, we need to define a new model that handles the intermediate stage between this model and a new discriminator model that takes 8×8 color images as input.
The existing input processing layer must receive a downsampled version of the new 8×8 image. A new input process layer must be defined that takes the 8×8 input image and passes it through a new block of two convolutional layers and a downsampling layer. The output of the new block after downsampling and the old input processing layer must be added together using a weighted sum via our new WeightedSum layer and then must reuse the same output block (two convolutional layers and the output layer).
Given the first defined model and our knowledge about this model (e.g. the number of layers in the input processing layer is 2 for the Conv2D and LeakyReLU), we can construct this new intermediate or fade-in model using layer indexes from the old model.
... old_model = model # get shape of existing model in_shape = list(old_model.input.shape) # define new input shape as double the size input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # define new input processing layer g = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) g = LeakyReLU(alpha=0.2)(g) # define new block g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = AveragePooling2D()(g) # downsample the new larger image downsample = AveragePooling2D()(in_image) # connect old input processing to downsampled new input block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # fade in output of old model input layer with new input g = WeightedSum()([block_old, g]) # skip the input, 1x1 and activation for the old model for i in range(3, len(old_model.layers)): g = old_model.layers[i](g) # define straight-through model model = Model(in_image, g) # compile model model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
So far, so good.
We also need a version of the same model with the same layers without the fade-in of the input from the old model’s input processing layers.
This straight-through version is required for training before we fade-in the next doubling of the input image size.
We can update the above example to create two versions of the model. First, the straight-through version as it is simpler, then the version used for the fade-in that reuses the layers from the new block and the output layers of the old model.
The add_discriminator_block() function below implements this, returning a list of the two defined models (straight-through and fade-in), and takes the old model as an argument and defines the number of input layers as a default argument (3).
To ensure that the WeightedSum layer works correctly, we have fixed all convolutional layers to always have 64 filters, and in turn, output 64 feature maps. If there is a mismatch between the old model’s input processing layer and the new blocks output in terms of the number of feature maps (channels), then the weighted sum will fail.
# add a discriminator block def add_discriminator_block(old_model, n_input_layers=3): # get shape of existing model in_shape = list(old_model.input.shape) # define new input shape as double the size input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # define new input processing layer d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # define new block d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # skip the input, 1x1 and activation for the old model for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # define straight-through model model1 = Model(in_image, d) # compile model model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # downsample the new larger image downsample = AveragePooling2D()(in_image) # connect old input processing to downsampled new input block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # fade in output of old model input layer with new input d = WeightedSum()([block_old, block_new]) # skip the input, 1x1 and activation for the old model for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # define straight-through model model2 = Model(in_image, d) # compile model model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2]
It is not an elegant function as we have some repetition, but it is readable and will get the job done.
We can then call this function again and again as we double the size of input images. Importantly, the function expects the straight-through version of the prior model as input.
The example below defines a new function called define_discriminator() that defines our base model that expects a 4×4 color image as input, then repeatedly adds blocks to create new versions of the discriminator model each time that expects images with quadruple the area.
# define the discriminator models for each image resolution def define_discriminator(n_blocks, input_shape=(4,4,3)): model_list = list() # base model input in_image = Input(shape=input_shape) # conv 1x1 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # conv 3x3 (output block) d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # conv 4x4 d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # dense output layer d = Flatten()(d) out_class = Dense(1)(d) # define model model = Model(in_image, out_class) # compile model model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # store model model_list.append([model, model]) # create submodels for i in range(1, n_blocks): # get prior model without the fade-on old_model = model_list[i - 1][0] # create new model for next resolution models = add_discriminator_block(old_model) # store model model_list.append(models) return model_list
This function will return a list of models, where each item in the list is a two-element list that contains first the straight-through version of the model at that resolution, and second the fade-in version of the model for that resolution.
We can tie all of this together and define a new “discriminator model” that will grow from 4×4, through to 8×8, and finally to 16×16. This is achieved by passing he n_blocks argument to 3 when calling the define_discriminator() function, for the creation of three sets of models.
The complete example is listed below.
# example of defining discriminator models for the progressive growing gan from keras.optimizers import Adam from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Flatten from keras.layers import Conv2D from keras.layers import AveragePooling2D from keras.layers import LeakyReLU from keras.layers import BatchNormalization from keras.layers import Add from keras.utils.vis_utils import plot_model from keras import backend # weighted sum output class WeightedSum(Add): # init with default value def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # output a weighted sum of inputs def _merge_function(self, inputs): # only supports a weighted sum of two inputs assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # add a discriminator block def add_discriminator_block(old_model, n_input_layers=3): # get shape of existing model in_shape = list(old_model.input.shape) # define new input shape as double the size input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # define new input processing layer d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # define new block d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # skip the input, 1x1 and activation for the old model for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # define straight-through model model1 = Model(in_image, d) # compile model model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # downsample the new larger image downsample = AveragePooling2D()(in_image) # connect old input processing to downsampled new input block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # fade in output of old model input layer with new input d = WeightedSum()([block_old, block_new]) # skip the input, 1x1 and activation for the old model for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # define straight-through model model2 = Model(in_image, d) # compile model model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] # define the discriminator models for each image resolution def define_discriminator(n_blocks, input_shape=(4,4,3)): model_list = list() # base model input in_image = Input(shape=input_shape) # conv 1x1 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # conv 3x3 (output block) d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # conv 4x4 d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # dense output layer d = Flatten()(d) out_class = Dense(1)(d) # define model model = Model(in_image, out_class) # compile model model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # store model model_list.append([model, model]) # create submodels for i in range(1, n_blocks): # get prior model without the fade-on old_model = model_list[i - 1][0] # create new model for next resolution models = add_discriminator_block(old_model) # store model model_list.append(models) return model_list # define models discriminators = define_discriminator(3) # spot check m = discriminators[2][1] m.summary() plot_model(m, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True)
Running the example first summarizes the fade-in version of the third model showing the 16×16 color image inputs and the single value output.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) (None, 16, 16, 3) 0
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 64) 256 input_3[0][0]
__________________________________________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 16, 16, 64) 0 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 16, 16, 64) 256 conv2d_8[0][0]
__________________________________________________________________________________________________
leaky_re_lu_8 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_8[0][0]
__________________________________________________________________________________________________
average_pooling2d_4 (AveragePoo (None, 8, 8, 3) 0 input_3[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 16, 16, 64) 256 conv2d_9[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 64) 256 average_pooling2d_4[0][0]
__________________________________________________________________________________________________
leaky_re_lu_9 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 conv2d_4[1][0]
__________________________________________________________________________________________________
average_pooling2d_3 (AveragePoo (None, 8, 8, 64) 0 leaky_re_lu_9[0][0]
__________________________________________________________________________________________________
weighted_sum_2 (WeightedSum) (None, 8, 8, 64) 0 leaky_re_lu_4[1][0]
average_pooling2d_3[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928 weighted_sum_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_5[2][0]
__________________________________________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_3[2][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 8, 8, 64) 36928 leaky_re_lu_5[2][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_6[2][0]
__________________________________________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[2][0]
__________________________________________________________________________________________________
average_pooling2d_1 (AveragePoo (None, 4, 4, 64) 0 leaky_re_lu_6[2][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 4, 4, 128) 73856 average_pooling2d_1[2][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 4, 4, 128) 512 conv2d_2[4][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_1[4][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 4, 4, 128) 262272 leaky_re_lu_2[4][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 4, 4, 128) 512 conv2d_3[4][0]
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_2[4][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 2048) 0 leaky_re_lu_3[4][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 2049 flatten_1[4][0]
==================================================================================================
Total params: 488,449
Trainable params: 487,425
Non-trainable params: 1,024
__________________________________________________________________________________________________
A plot of the same fade-in version of the model is created and saved to file.
Note: creating this plot assumes that the pygraphviz and pydot libraries are installed. If this is a problem, comment out the import statement and call to plot_model().
The plot shows the 16×16 input image that is downsampled and passed through the 8×8 input processing layers from the prior model (left). It also shows the addition of the new block (right) and the weighted average that combines both streams of input, before using the existing model layers to continue processing and outputting a prediction.
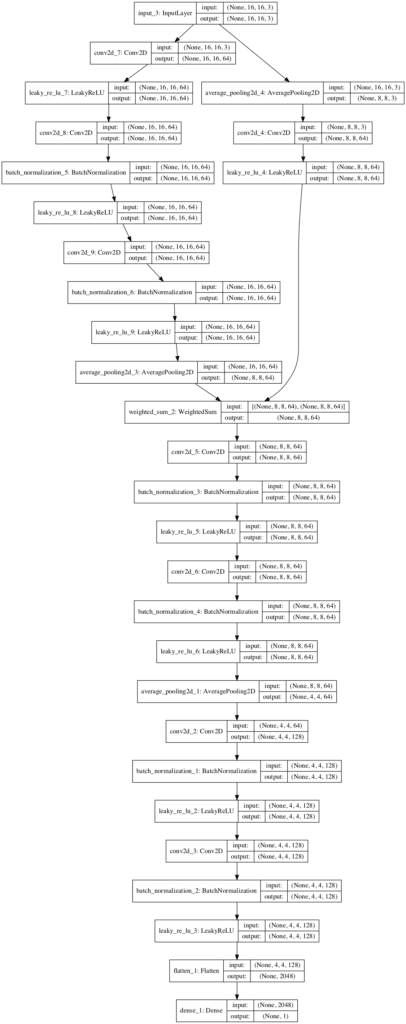
Plot of the Fade-In Discriminator Model For the Progressive Growing GAN Transitioning From 8×8 to 16×16 Input Images
Now that we have seen how we can define the discriminator models, let’s look at how we can define the generator models.
How to Implement the Progressive Growing GAN Generator Model
The generator models for the progressive growing GAN are easier to implement in Keras than the discriminator models.
The reason for this is because each fade-in requires a minor change to the output of the model.
Increasing the resolution of the generator involves first upsampling the output of the end of the last block. This is then connected to the new block and a new output layer for an image that is double the height and width dimensions or quadruple the area. During the phase-in, the upsampling is also connected to the output layer from the old model and the output from both output layers is merged using a weighted average.
After the phase-in is complete, the old output layer is removed.
This can be summarized with the following figure, taken from the paper showing a model before growing (a), during the phase-in of the larger resolution (b), and the model after the phase-in (c).
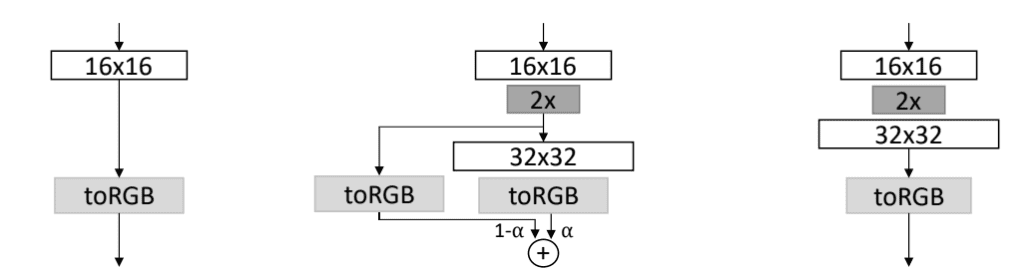
Figure Showing the Growing of the Generator Model, Before (a), During (b), and After (c) the Phase-In of a High Resolution.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
The toRGB layer is a convolutional layer with 3 1×1 filters, sufficient to output a color image.
The model takes a point in the latent space as input, e.g. such as a 100-element or 512-element vector as described in the paper. This is scaled up to provided the basis for 4×4 activation maps, followed by a convolutional layer with 4×4 filters and another with 3×3 filters. Like the discriminator, LeakyReLU activations are used, as is pixel normalization, which we will substitute with batch normalization for brevity.
A block involves an upsample layer followed by two convolutional layers with 3×3 filters. Upsampling is achieved using a nearest neighbor method (e.g. duplicating input rows and columns) via a UpSampling2D layer instead of the more common transpose convolutional layer.
We can define the baseline model that will take a point in latent space as input and output a 4×4 color image as follows:
... # base model latent input in_latent = Input(shape=(100,)) # linear scale up to activation maps g = Dense(128 * 4 * 4, kernel_initializer='he_normal')(in_latent) g = Reshape((4, 4, 128))(g) # conv 4x4, input block g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 1x1, output block out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model = Model(in_latent, out_image)
Next, we need to define a version of the model that uses all of the same input layers, although adds a new block (upsample and 2 convolutional layers) and a new output layer (a 1×1 convolutional layer).
This would be the model after the phase-in to the new output resolution. This can be achieved by using own knowledge about the baseline model and that the end of the last block is the second last layer, e.g. layer at index -2 in the model’s list of layers.
The new model with the addition of a new block and output layer is defined as follows:
... old_model = model # get the end of the last block block_end = old_model.layers[-2].output # upsample, and define new block upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # add new output layer out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model = Model(old_model.input, out_image)
That is pretty straightforward; we have chopped off the old output layer at the end of the last block and grafted on a new block and output layer.
Now we need a version of this new model to use during the fade-in.
This involves connecting the old output layer to the new upsampling layer at the start of the new block and using an instance of our WeightedSum layer defined in the previous section to combine the output of the old and new output layers.
... # get the output layer from old model out_old = old_model.layers[-1] # connect the upsampling to the old output layer out_image2 = out_old(upsampling) # define new output image as the weighted sum of the old and new models merged = WeightedSum()([out_image2, out_image]) # define model model2 = Model(old_model.input, merged)
We can combine the definition of these two operations into a function named add_generator_block(), defined below, that will expand a given model and return both the new generator model with the added block (model1) and a version of the model with the fading in of the new block with the old output layer (model2).
# add a generator block def add_generator_block(old_model): # get the end of the last block block_end = old_model.layers[-2].output # upsample, and define new block upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # add new output layer out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model1 = Model(old_model.input, out_image) # get the output layer from old model out_old = old_model.layers[-1] # connect the upsampling to the old output layer out_image2 = out_old(upsampling) # define new output image as the weighted sum of the old and new models merged = WeightedSum()([out_image2, out_image]) # define model model2 = Model(old_model.input, merged) return [model1, model2]
We can then call this function with our baseline model to create models with one added block and continue to call it with subsequent models to keep adding blocks.
The define_generator() function below implements this, taking the size of the latent space and number of blocks to add (models to create).
The baseline model is defined as outputting a color image with the shape 4×4, controlled by the default argument in_dim.
# define generator models def define_generator(latent_dim, n_blocks, in_dim=4): model_list = list() # base model latent input in_latent = Input(shape=(latent_dim,)) # linear scale up to activation maps g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # conv 4x4, input block g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 1x1, output block out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model = Model(in_latent, out_image) # store model model_list.append([model, model]) # create submodels for i in range(1, n_blocks): # get prior model without the fade-on old_model = model_list[i - 1][0] # create new model for next resolution models = add_generator_block(old_model) # store model model_list.append(models) return model_list
We can tie all of this together and define a baseline generator and the addition of two blocks, so three models in total, where a straight-through and fade-in version of each model is defined.
The complete example is listed below.
# example of defining generator models for the progressive growing gan from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Reshape from keras.layers import Conv2D from keras.layers import UpSampling2D from keras.layers import LeakyReLU from keras.layers import BatchNormalization from keras.layers import Add from keras.utils.vis_utils import plot_model from keras import backend # weighted sum output class WeightedSum(Add): # init with default value def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # output a weighted sum of inputs def _merge_function(self, inputs): # only supports a weighted sum of two inputs assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # add a generator block def add_generator_block(old_model): # get the end of the last block block_end = old_model.layers[-2].output # upsample, and define new block upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # add new output layer out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model1 = Model(old_model.input, out_image) # get the output layer from old model out_old = old_model.layers[-1] # connect the upsampling to the old output layer out_image2 = out_old(upsampling) # define new output image as the weighted sum of the old and new models merged = WeightedSum()([out_image2, out_image]) # define model model2 = Model(old_model.input, merged) return [model1, model2] # define generator models def define_generator(latent_dim, n_blocks, in_dim=4): model_list = list() # base model latent input in_latent = Input(shape=(latent_dim,)) # linear scale up to activation maps g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # conv 4x4, input block g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 1x1, output block out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model = Model(in_latent, out_image) # store model model_list.append([model, model]) # create submodels for i in range(1, n_blocks): # get prior model without the fade-on old_model = model_list[i - 1][0] # create new model for next resolution models = add_generator_block(old_model) # store model model_list.append(models) return model_list # define models generators = define_generator(100, 3) # spot check m = generators[2][1] m.summary() plot_model(m, to_file='generator_plot.png', show_shapes=True, show_layer_names=True)
The example chooses the fade-in model for the last model to summarize.
Running the example first summarizes a linear list of the layers in the model. We can see that the last model takes a point from the latent space and outputs a 16×16 image.
This matches as our expectations as the baseline model outputs a 4×4 image, adding one block increases this to 8×8, and adding one more block increases this to 16×16.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 100) 0
__________________________________________________________________________________________________
dense_1 (Dense) (None, 2048) 206848 input_1[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 4, 4, 128) 0 dense_1[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 4, 4, 128) 147584 reshape_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 4, 4, 128) 512 conv2d_1[0][0]
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 4, 4, 128) 147584 leaky_re_lu_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 4, 4, 128) 512 conv2d_2[0][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
up_sampling2d_1 (UpSampling2D) (None, 8, 8, 128) 0 leaky_re_lu_2[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 64) 73792 up_sampling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_4[0][0]
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928 leaky_re_lu_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_5[0][0]
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
up_sampling2d_2 (UpSampling2D) (None, 16, 16, 64) 0 leaky_re_lu_4[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 64) 36928 up_sampling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 16, 16, 64) 256 conv2d_7[0][0]
__________________________________________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 16, 16, 64) 256 conv2d_8[0][0]
__________________________________________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) multiple 195 up_sampling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 3) 195 leaky_re_lu_6[0][0]
__________________________________________________________________________________________________
weighted_sum_2 (WeightedSum) (None, 16, 16, 3) 0 conv2d_6[1][0]
conv2d_9[0][0]
==================================================================================================
Total params: 689,030
Trainable params: 688,006
Non-trainable params: 1,024
__________________________________________________________________________________________________
A plot of the same fade-in version of the model is created and saved to file.
Note: creating this plot assumes that the pygraphviz and pydot libraries are installed. If this is a problem, comment out the import statement and call to plot_model().
We can see that the output from the last block passes through an UpSampling2D layer before feeding the added block and a new output layer as well as the old output layer before being merged via a weighted sum into the final output layer.
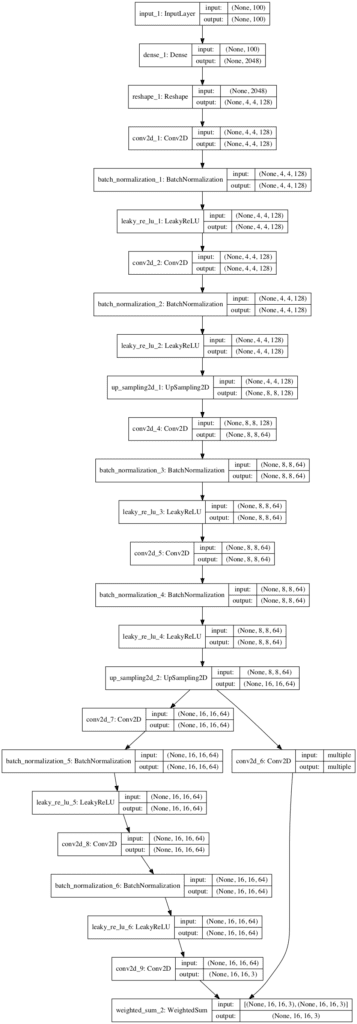
Plot of the Fade-In Generator Model For the Progressive Growing GAN Transitioning From 8×8 to 16×16 Output Images
Now that we have seen how to define the generator models, we can review how the generator models may be updated via the discriminator models.
How to Implement Composite Models for Updating the Generator
The discriminator models are trained directly with real and fake images as input and a target value of 0 for fake and 1 for real.
The generator models are not trained directly; instead, they are trained indirectly via the discriminator models, just like a normal GAN model.
We can create a composite model for each level of growth of the model, e.g. pair 4×4 generators and 4×4 discriminators. We can also pair the straight-through models together, and the fade-in models together.
For example, we can retrieve the generator and discriminator models for a given level of growth.
... g_models, d_models = generators[0], discriminators[0]
Then we can use them to create a composite model for training the straight-through generator, where the output of the generator is fed directly to the discriminator in order to classify.
# straight-through model d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
And do the same for the composite model for the fade-in generator.
# fade-in model d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8))
The function below, named define_composite(), automates this; given a list of defined discriminator and generator models, it will create an appropriate composite model for training each generator model.
# define composite models for training generators via discriminators def define_composite(discriminators, generators): model_list = list() # create composite models for i in range(len(discriminators)): g_models, d_models = generators[i], discriminators[i] # straight-through model d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # fade-in model d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # store model_list.append([model1, model2]) return model_list
Tying this together with the definition of the discriminator and generator models above, the complete example of defining all models at each pre-defined level of growth is listed below.
# example of defining composite models for the progressive growing gan from keras.optimizers import Adam from keras.models import Sequential from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Flatten from keras.layers import Reshape from keras.layers import Conv2D from keras.layers import UpSampling2D from keras.layers import AveragePooling2D from keras.layers import LeakyReLU from keras.layers import BatchNormalization from keras.layers import Add from keras.utils.vis_utils import plot_model from keras import backend # weighted sum output class WeightedSum(Add): # init with default value def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # output a weighted sum of inputs def _merge_function(self, inputs): # only supports a weighted sum of two inputs assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # add a discriminator block def add_discriminator_block(old_model, n_input_layers=3): # get shape of existing model in_shape = list(old_model.input.shape) # define new input shape as double the size input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # define new input processing layer d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # define new block d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # skip the input, 1x1 and activation for the old model for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # define straight-through model model1 = Model(in_image, d) # compile model model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # downsample the new larger image downsample = AveragePooling2D()(in_image) # connect old input processing to downsampled new input block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # fade in output of old model input layer with new input d = WeightedSum()([block_old, block_new]) # skip the input, 1x1 and activation for the old model for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # define straight-through model model2 = Model(in_image, d) # compile model model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] # define the discriminator models for each image resolution def define_discriminator(n_blocks, input_shape=(4,4,3)): model_list = list() # base model input in_image = Input(shape=input_shape) # conv 1x1 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # conv 3x3 (output block) d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # conv 4x4 d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # dense output layer d = Flatten()(d) out_class = Dense(1)(d) # define model model = Model(in_image, out_class) # compile model model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # store model model_list.append([model, model]) # create submodels for i in range(1, n_blocks): # get prior model without the fade-on old_model = model_list[i - 1][0] # create new model for next resolution models = add_discriminator_block(old_model) # store model model_list.append(models) return model_list # add a generator block def add_generator_block(old_model): # get the end of the last block block_end = old_model.layers[-2].output # upsample, and define new block upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # add new output layer out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model1 = Model(old_model.input, out_image) # get the output layer from old model out_old = old_model.layers[-1] # connect the upsampling to the old output layer out_image2 = out_old(upsampling) # define new output image as the weighted sum of the old and new models merged = WeightedSum()([out_image2, out_image]) # define model model2 = Model(old_model.input, merged) return [model1, model2] # define generator models def define_generator(latent_dim, n_blocks, in_dim=4): model_list = list() # base model latent input in_latent = Input(shape=(latent_dim,)) # linear scale up to activation maps g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # conv 4x4, input block g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # conv 1x1, output block out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # define model model = Model(in_latent, out_image) # store model model_list.append([model, model]) # create submodels for i in range(1, n_blocks): # get prior model without the fade-on old_model = model_list[i - 1][0] # create new model for next resolution models = add_generator_block(old_model) # store model model_list.append(models) return model_list # define composite models for training generators via discriminators def define_composite(discriminators, generators): model_list = list() # create composite models for i in range(len(discriminators)): g_models, d_models = generators[i], discriminators[i] # straight-through model d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # fade-in model d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # store model_list.append([model1, model2]) return model_list # define models discriminators = define_discriminator(3) # define models generators = define_generator(100, 3) # define composite models composite = define_composite(discriminators, generators)
Now that we know how to define all of the models, we can review how the models might be updated during training.
How to Train Discriminator and Generator Models
Pre-defining the generator, discriminator, and composite models was the hard part; training the models is straight forward and much like training any other GAN.
Importantly, in each training iteration the alpha variable in each WeightedSum layer must be set to a new value. This must be set for the layer in both the generator and discriminator models and allows for the smooth linear transition from the old model layers to the new model layers, e.g. alpha values set from 0 to 1 over a fixed number of training iterations.
The update_fadein() function below implements this and will loop through a list of models and set the alpha value on each based on the current step in a given number of training steps. You may be able to implement this more elegantly using a callback.
# update the alpha value on each instance of WeightedSum def update_fadein(models, step, n_steps): # calculate current alpha (linear from 0 to 1) alpha = step / float(n_steps - 1) # update the alpha for each model for model in models: for layer in model.layers: if isinstance(layer, WeightedSum): backend.set_value(layer.alpha, alpha)
We can define a generic function for training a given generator, discriminator, and composite model for a given number of training epochs.
The train_epochs() function below implements this where first the discriminator model is updated on real and fake images, then the generator model is updated, and the process is repeated for the required number of training iterations based on the dataset size and the number of epochs.
This function calls helper functions for retrieving a batch of real images via generate_real_samples(), generating a batch of fake samples with the generator generate_fake_samples(), and generating a sample of points in latent space generate_latent_points(). You can define these functions yourself quite trivially.
# train a generator and discriminator
def train_epochs(g_model, d_model, gan_model, dataset, n_epochs, n_batch, fadein=False):
# calculate the number of batches per training epoch
bat_per_epo = int(dataset.shape[0] / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# calculate the size of half a batch of samples
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_steps):
# update alpha for all WeightedSum layers when fading in new blocks
if fadein:
update_fadein([g_model, d_model, gan_model], i, n_steps)
# prepare real and fake samples
X_real, y_real = generate_real_samples(dataset, half_batch)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# update discriminator model
d_loss1 = d_model.train_on_batch(X_real, y_real)
d_loss2 = d_model.train_on_batch(X_fake, y_fake)
# update the generator via the discriminator's error
z_input = generate_latent_points(latent_dim, n_batch)
y_real2 = ones((n_batch, 1))
g_loss = gan_model.train_on_batch(z_input, y_real2)
# summarize loss on this batch
print('>%d, d1=%.3f, d2=%.3f g=%.3f' % (i+1, d_loss1, d_loss2, g_loss))
The images must be scaled to the size of each model. If the images are in-memory, we can define a simple scale_dataset() function to scale the loaded images.
In this case, we are using the skimage.transform.resize function from the scikit-image library to resize the NumPy array of pixels to the required size and use nearest neighbor interpolation.
# scale images to preferred size def scale_dataset(images, new_shape): images_list = list() for image in images: # resize with nearest neighbor interpolation new_image = resize(image, new_shape, 0) # store images_list.append(new_image) return asarray(images_list)
First, the baseline model must be fit for a given number of training epochs, e.g. the model that outputs 4×4 sized images.
This will require that the loaded images be scaled to the required size defined by the shape of the generator models output layer.
# fit the baseline model
g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)
We can then process each level of growth, e.g. the first being 8×8.
This involves first retrieving the models, scaling the data to the appropriate size, then fitting the fade-in model followed by training the straight-through version of the model for fine tuning.
We can repeat this for each level of growth in a loop.
# process each level of growth
for i in range(1, len(g_models)):
# retrieve models for this level of growth
[g_normal, g_fadein] = g_models[i]
[d_normal, d_fadein] = d_models[i]
[gan_normal, gan_fadein] = gan_models[i]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train fade-in models for next level of growth
train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein, n_batch)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)
We can tie this together and define a function called train() to train the progressive growing GAN function.
# train the generator and discriminator
def train(g_models, d_models, gan_models, dataset, latent_dim, e_norm, e_fadein, n_batch):
# fit the baseline model
g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)
# process each level of growth
for i in range(1, len(g_models)):
# retrieve models for this level of growth
[g_normal, g_fadein] = g_models[i]
[d_normal, d_fadein] = d_models[i]
[gan_normal, gan_fadein] = gan_models[i]
# scale dataset to appropriate size
gen_shape = g_normal.output_shape
scaled_data = scale_dataset(dataset, gen_shape[1:])
print('Scaled Data', scaled_data.shape)
# train fade-in models for next level of growth
train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein, n_batch, True)
# train normal or straight-through models
train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch)
The number of epochs for the normal phase is defined by the e_norm argument and the number of epochs during the fade-in phase is defined by the e_fadein argument.
The number of epochs must be specified based on the size of the image dataset and the same number of epochs can be used for each phase, as was used in the paper.
We start with 4×4 resolution and train the networks until we have shown the discriminator 800k real images in total. We then alternate between two phases: fade in the first 3-layer block during the next 800k images, stabilize the networks for 800k images, fade in the next 3-layer block during 800k images, etc.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
We can then define our models as we did in the previous section, then call the training function.
# number of growth phase, e.g. 3 = 16x16 images n_blocks = 3 # size of the latent space latent_dim = 100 # define models d_models = define_discriminator(n_blocks) # define models g_models = define_generator(100, n_blocks) # define composite models gan_models = define_composite(d_models, g_models) # load image data dataset = load_real_samples() # train model train(g_models, d_models, gan_models, dataset, latent_dim, 100, 100, 16)
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Official
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, Official.
- progressive_growing_of_gans Project (official), GitHub.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation. Open Review.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, YouTube.
- Progressive growing of GANs for improved quality, stability and variation, KeyNote, YouTube.
API
- Keras Datasets API.
- Keras Sequential Model API
- Keras Convolutional Layers API
- How can I “freeze” Keras layers?
- Keras Contrib Project
- skimage.transform.resize API
Articles
- Keras-progressive_growing_of_gans Project, GitHub.
- Hands-On-Generative-Adversarial-Networks-with-Keras Project, GitHub.
Summary
In this tutorial, you discovered how to develop progressive growing generative adversarial network models from scratch with Keras.
Specifically, you learned:
- How to develop pre-defined discriminator and generator models at each level of output image growth.
- How to define composite models for training the generator models via the discriminator models.
- How to cycle the training of fade-in version and normal versions of models at each level of output image growth.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Implement Progressive Growing GAN Models in Keras appeared first on Machine Learning Mastery.