
Author: Jason Brownlee
Discover a Gentle Introduction to Bayesian Optimization.
Global optimization is a challenging problem of finding an input that results in the minimum or maximum cost of a given objective function.
Typically, the form of the objective function is complex and intractable to analyze and is often non-convex, nonlinear, high dimension, noisy, and computationally expensive to evaluate.
Bayesian Optimization provides a principled technique based on Bayes Theorem to direct a search of a global optimization problem that is efficient and effective. It works by building a probabilistic model of the objective function, called the surrogate function, that is then searched efficiently with an acquisition function before candidate samples are chosen for evaluation on the real objective function.
Bayesian Optimization is often used in applied machine learning to tune the hyperparameters of a given well-performing model on a validation dataset.
In this tutorial, you will discover Bayesian Optimization for directed search of complex optimization problems.
After completing this tutorial, you will know:
- Global optimization is a challenging problem that involves black box and often non-convex, non-linear, noisy, and computationally expensive objective functions.
- Bayesian Optimization provides a probabilistically principled method for global optimization.
- How to implement Bayesian Optimization from scratch and how to use open-source implementations.
Discover bayes opimization, naive bayes, maximum likelihood, distributions, cross entropy, and much more in my new book, with 28 step-by-step tutorials and full Python source code.
Let’s get started.

A Gentle Introduction to Bayesian Optimization
Photo by Beni Arnold, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
- Challenge of Function Optimization
- What Is Bayesian Optimization
- How to Perform Bayesian Optimization
- Hyperparameter Tuning With Bayesian Optimization
Challenge of Function Optimization
Global function optimization, or function optimization for short, involves finding the minimum or maximum of an objective function.
Samples are drawn from the domain and evaluated by the objective function to give a score or cost.
Let’s define some common terms:
- Samples. One example from the domain, represented as a vector.
- Search Space: Extent of the domain from which samples can be drawn.
- Objective Function. Function that takes a sample and returns a cost.
- Cost. Numeric score for a sample calculated via the objective function.
Samples are comprised of one or more variables generally easy to devise or create. One sample is often defined as a vector of variables with a predefined range in an n-dimensional space. This space must be sampled and explored in order to find the specific combination of variable values that result in the best cost.
The cost often has units that are specific to a given domain. Optimization is often described in terms of minimizing cost, as a maximization problem can easily be transformed into a minimization problem by inverting the calculated cost. Together, the minimum and maximum of a function are referred to as the extreme of the function (or the plural extrema).
The objective function is often easy to specify but can be computationally challenging to calculate or result in a noisy calculation of cost over time. The form of the objective function is unknown and is often highly nonlinear, and highly multi-dimensional defined by the number of input variables. The function is also probably non-convex. This means that local extrema may or may not be the global extrema (e.g. could be misleading and result in premature convergence), hence the name of the task as global rather than local optimization.
Although little is known about the objective function, (it is known whether the minimum or the maximum cost from the function is sought), and as such, it is often referred to as a black box function and the search process as black box optimization. Further, the objective function is sometimes called an oracle given the ability to only give answers.
Function optimization is a fundamental part of machine learning. Most machine learning algorithms involve the optimization of parameters (weights, coefficients, etc.) in response to training data. Optimization also refers to the process of finding the best set of hyperparameters that configure the training of a machine learning algorithm. Taking one step higher again, the selection of training data, data preparation, and machine learning algorithms themselves is also a problem of function optimization.
Summary of optimization in machine learning:
- Algorithm Training. Optimization of model parameters.
- Algorithm Tuning. Optimization of model hyperparameters.
- Predictive Modeling. Optimization of data, data preparation, and algorithm selection.
Many methods exist for function optimization, such as randomly sampling the variable search space, called random search, or systematically evaluating samples in a grid across the search space, called grid search.
More principled methods are able to learn from sampling the space so that future samples are directed toward the parts of the search space that are most likely to contain the extrema.
A directed approach to global optimization that uses probability is called Bayesian Optimization.
Want to Learn Probability for Machine Learning
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
What Is Bayesian Optimization
Bayesian Optimization is an approach that uses Bayes Theorem to direct the search in order to find the minimum or maximum of an objective function.
It is an approach that is most useful for objective functions that are complex, noisy, and/or expensive to evaluate.
Bayesian optimization is a powerful strategy for finding the extrema of objective functions that are expensive to evaluate. […] It is particularly useful when these evaluations are costly, when one does not have access to derivatives, or when the problem at hand is non-convex.
Recall that Bayes Theorem is an approach for calculating the conditional probability of an event:
- P(A|B) = P(B|A) * P(A) / P(B)
We can simplify this calculation by removing the normalizing value of P(B) and describe the conditional probability as a proportional quantity. This is useful as we are not interested in calculating a specific conditional probability, but instead in optimizing a quantity.
- P(A|B) = P(B|A) * P(A)
The conditional probability that we are calculating is referred to generally as the posterior probability; the reverse conditional probability is sometimes referred to as the likelihood, and the marginal probability is referred to as the prior probability; for example:
- posterior = likelihood * prior
This provides a framework that can be used to quantify the beliefs about an unknown objective function given samples from the domain and their evaluation via the objective function.
We can devise specific samples (x1, x2, …, xn) and evaluate them using the objective function f(xi) that returns the cost or outcome for the sample xi. Samples and their outcome are collected sequentially and define our data D, e.g. D = {xi, f(xi), … xn, f(xn)} and is used to define the prior. The likelihood function is defined as the probability of observing the data given the function P(D | f). This likelihood function will change as more observations are collected.
- P(f|D) = P(D|f) * P(f)
The posterior represents everything we know about the objective function. It is an approximation of the objective function and can be used to estimate the cost of different candidate samples that we may want to evaluate.
In this way, the posterior probability is a surrogate objective function.
The posterior captures the updated beliefs about the unknown objective function. One may also interpret this step of Bayesian optimization as estimating the objective function with a surrogate function (also called a response surface).
- Surrogate Function: Bayesian approximation of the objective function that can be sampled efficiently.
The surrogate function gives us an estimate of the objective function, which can be used to direct future sampling. Sampling involves careful use of the posterior in a function known as the “acquisition” function, e.g. for acquiring more samples. We want to use our belief about the objective function to sample the area of the search space that is most likely to pay off, therefore the acquisition will optimize the conditional probability of locations in the search to generate the next sample.
- Acquisition Function: Technique by which the posterior is used to select the next sample from the search space.
Once additional samples and their evaluation via the objective function f() have been collected, they are added to data D and the posterior is then updated.
This process is repeated until the extrema of the objective function is located, a good enough result is located, or resources are exhausted.
The Bayesian Optimization algorithm can be summarized as follows:
- 1. Select a Sample by Optimizing the Acquisition Function.
- 2. Evaluate the Sample With the Objective Function.
- 3. Update the Data and, in turn, the Surrogate Function.
- 4. Go To 1.
How to Perform Bayesian Optimization
In this section, we will explore how Bayesian Optimization works by developing an implementation from scratch for a simple one-dimensional test function.
First, we will define the test problem, then how to model the mapping of inputs to outputs with a surrogate function. Next, we will see how the surrogate function can be searched efficiently with an acquisition function before tying all of these elements together into the Bayesian Optimization procedure.
Test Problem
The first step is to define a test problem.
We will use a multimodal problem with five peaks, calculated as:
- y = x^2 * sin(5 * PI * x)^6
Where x is a real value in the range [0,1] and PI is the value of pi.
We will augment this function by adding Gaussian noise with a mean of zero and a standard deviation of 0.1. This will mean that the real evaluation will have a positive or negative random value added to it, making the function challenging to optimize.
The objective() function below implements this.
# objective function def objective(x, noise=0.1): noise = normal(loc=0, scale=noise) return (x**2 * sin(5 * pi * x)**6.0) + noise
We can test this function by first defining a grid-based sample of inputs from 0 to 1 with a step size of 0.01 across the domain.
... # grid-based sample of the domain [0,1] X = arange(0, 1, 0.01)
We can then evaluate these samples using the target function without any noise to see what the real objective function looks like.
... # sample the domain without noise y = [objective(x, 0) for x in X]
We can then evaluate these same points with noise to see what the objective function will look like when we are optimizing it.
... # sample the domain with noise ynoise = [objective(x) for x in X]
We can look at all of the non-noisy objective function values to find the input that resulted in the best score and report it. This will be the optima, in this case, maxima, as we are maximizing the output of the objective function.
We would not know this in practice, but for out test problem, it is good to know the real best input and output of the function to see if the Bayesian Optimization algorithm can locate it.
...
# find best result
ix = argmax(y)
print('Optima: x=%.3f, y=%.3f' % (X[ix], y[ix]))
Finally, we can create a plot, first showing the noisy evaluation as a scatter plot with input on the x-axis and score on the y-axis, then a line plot of the scores without any noise.
... # plot the points with noise pyplot.scatter(X, ynoise) # plot the points without noise pyplot.plot(X, y) # show the plot pyplot.show()
The complete example of reviewing the test function that we wish to optimize is listed below.
# example of the test problem
from math import sin
from math import pi
from numpy import arange
from numpy import argmax
from numpy.random import normal
from matplotlib import pyplot
# objective function
def objective(x, noise=0.1):
noise = normal(loc=0, scale=noise)
return (x**2 * sin(5 * pi * x)**6.0) + noise
# grid-based sample of the domain [0,1]
X = arange(0, 1, 0.01)
# sample the domain without noise
y = [objective(x, 0) for x in X]
# sample the domain with noise
ynoise = [objective(x) for x in X]
# find best result
ix = argmax(y)
print('Optima: x=%.3f, y=%.3f' % (X[ix], y[ix]))
# plot the points with noise
pyplot.scatter(X, ynoise)
# plot the points without noise
pyplot.plot(X, y)
# show the plot
pyplot.show()
Running the example first reports the global optima as an input with the value 0.9 that gives the score 0.81.
Optima: x=0.900, y=0.810
A plot is then created showing the noisy evaluation of the samples (dots) and the non-noisy and true shape of the objective function (line).
Your specific dots will differ given the stochastic nature of the noisy objective function.
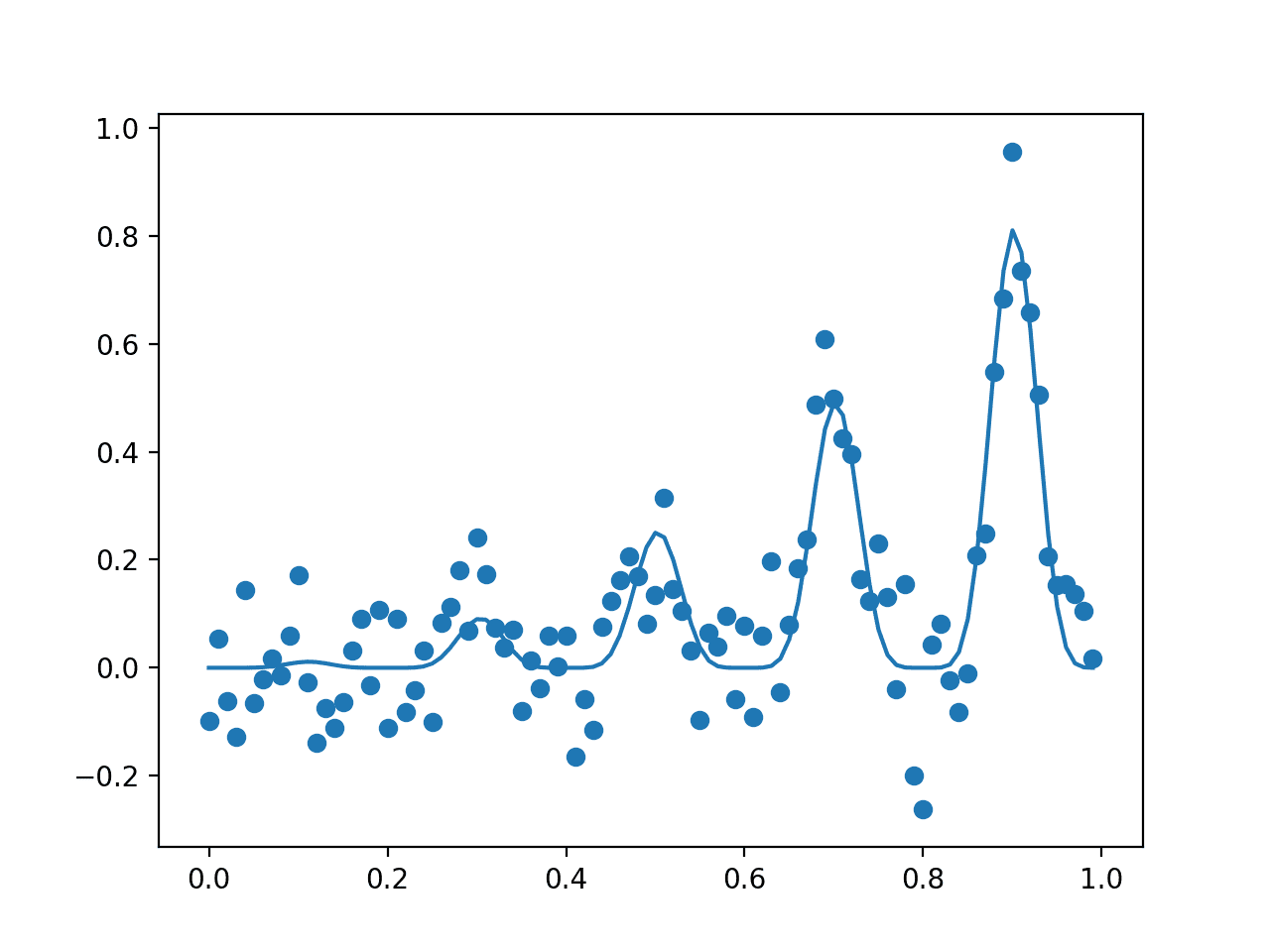
Plot of The Input Samples Evaluated with a Noisy (dots) and Non-Noisy (Line) Objective Function
Now that we have a test problem, let’s review how to train a surrogate function.
Surrogate Function
The surrogate function is a technique used to best approximate the mapping of input examples to an output score.
Probabilistically, it summarizes the conditional probability of an objective function (f), given the available data (D) or P(f|D).
A number of techniques can be used for this, although the most popular is to treat the problem as a regression predictive modeling problem with the data representing the input and the score representing the output to the model. This is often best modeled using a random forest or a Gaussian Process.
A Gaussian Process, or GP, is a model that constructs a joint probability distribution over the variables, assuming a multivariate Gaussian distribution. As such, it is capable of efficient and effective summarization of a large number of functions and smooth transition as more observations are made available to the model.
This smooth structure and smooth transition to new functions based on data are desirable properties as we sample the domain, and the multivariate Gaussian basis to the model means that an estimate from the model will be a mean of a distribution with a standard deviation; that will be helpful later in the acquisition function.
As such, using a GP regression model is often preferred.
We can fit a GP regression model using the GaussianProcessRegressor scikit-learn implementation from a sample of inputs (X) and noisy evaluations from the objective function (y).
First, the model must be defined. An important aspect in defining the GP model is the kernel. This controls the shape of the function at specific points based on distance measures between actual data observations. Many different kernel functions can be used, and some may offer better performance for specific datasets.
By default, a Radial Basis Function, or RBF, is used that can work well.
... # define the model model = GaussianProcessRegressor()
Once defined, the model can be fit on the training dataset directly by calling the fit() function.
The defined model can be fit again at any time with updated data concatenated to the existing data by another call to fit().
... # fit the model model.fit(X, y)
The model will estimate the cost for one or more samples provided to it.
The model is used by calling the predict() function. The result for a given sample will be a mean of the distribution at that point. We can also get the standard deviation of the distribution at that point in the function by specifying the argument return_std=True; for example:
... yhat = model.predict(X, return_std=True)
This function can result in warnings if the distribution is thin at a given point we are interested in sampling.
Therefore, we can silence all of the warnings when making a prediction. The surrogate() function below takes the fit model and one or more samples and returns the mean and standard deviation estimated costs whilst not printing any warnings.
# surrogate or approximation for the objective function
def surrogate(model, X):
# catch any warning generated when making a prediction
with catch_warnings():
# ignore generated warnings
simplefilter("ignore")
return model.predict(X, return_std=True)
We can call this function any time to estimate the cost of one or more samples, such as when we want to optimize the acquisition function in the next section.
For now, it is interesting to see what the surrogate function looks like across the domain after it is trained on a random sample.
We can achieve this by first fitting the GP model on a random sample of 100 data points and their real objective function values with noise. We can then plot a scatter plot of these points. Next, we can perform a grid-based sample across the input domain and estimate the cost at each point using the surrogate function and plot the result as a line.
We would expect the surrogate function to have a crude approximation of the true non-noisy objective function.
The plot() function below creates this plot, given the random data sample of the real noisy objective function and the fit model.
# plot real observations vs surrogate function def plot(X, y, model): # scatter plot of inputs and real objective function pyplot.scatter(X, y) # line plot of surrogate function across domain Xsamples = asarray(arange(0, 1, 0.001)) Xsamples = Xsamples.reshape(len(Xsamples), 1) ysamples, _ = surrogate(model, Xsamples) pyplot.plot(Xsamples, ysamples) # show the plot pyplot.show()
Tying this together, the complete example of fitting a Gaussian Process regression model on noisy samples and plotting the sample vs. the surrogate function is listed below.
# example of a gaussian process surrogate function
from math import sin
from math import pi
from numpy import arange
from numpy import asarray
from numpy.random import normal
from numpy.random import random
from matplotlib import pyplot
from warnings import catch_warnings
from warnings import simplefilter
from sklearn.gaussian_process import GaussianProcessRegressor
# objective function
def objective(x, noise=0.1):
noise = normal(loc=0, scale=noise)
return (x**2 * sin(5 * pi * x)**6.0) + noise
# surrogate or approximation for the objective function
def surrogate(model, X):
# catch any warning generated when making a prediction
with catch_warnings():
# ignore generated warnings
simplefilter("ignore")
return model.predict(X, return_std=True)
# plot real observations vs surrogate function
def plot(X, y, model):
# scatter plot of inputs and real objective function
pyplot.scatter(X, y)
# line plot of surrogate function across domain
Xsamples = asarray(arange(0, 1, 0.001))
Xsamples = Xsamples.reshape(len(Xsamples), 1)
ysamples, _ = surrogate(model, Xsamples)
pyplot.plot(Xsamples, ysamples)
# show the plot
pyplot.show()
# sample the domain sparsely with noise
X = random(100)
y = asarray([objective(x) for x in X])
# reshape into rows and cols
X = X.reshape(len(X), 1)
y = y.reshape(len(y), 1)
# define the model
model = GaussianProcessRegressor()
# fit the model
model.fit(X, y)
# plot the surrogate function
plot(X, y, model)
Running the example first draws the random sample, evaluates it with the noisy objective function, then fits the GP model.
The data sample and a grid of points across the domain evaluated via the surrogate function are then plotted as dots and a line respectively.
Your specific results will vary given the stochastic nature of the data sample. Consider running the example a few times.
In this case, as we expected, the plot resembles a crude version of the underlying non-noisy objective function, importantly with a peak around 0.9 where we know the true maxima is located.
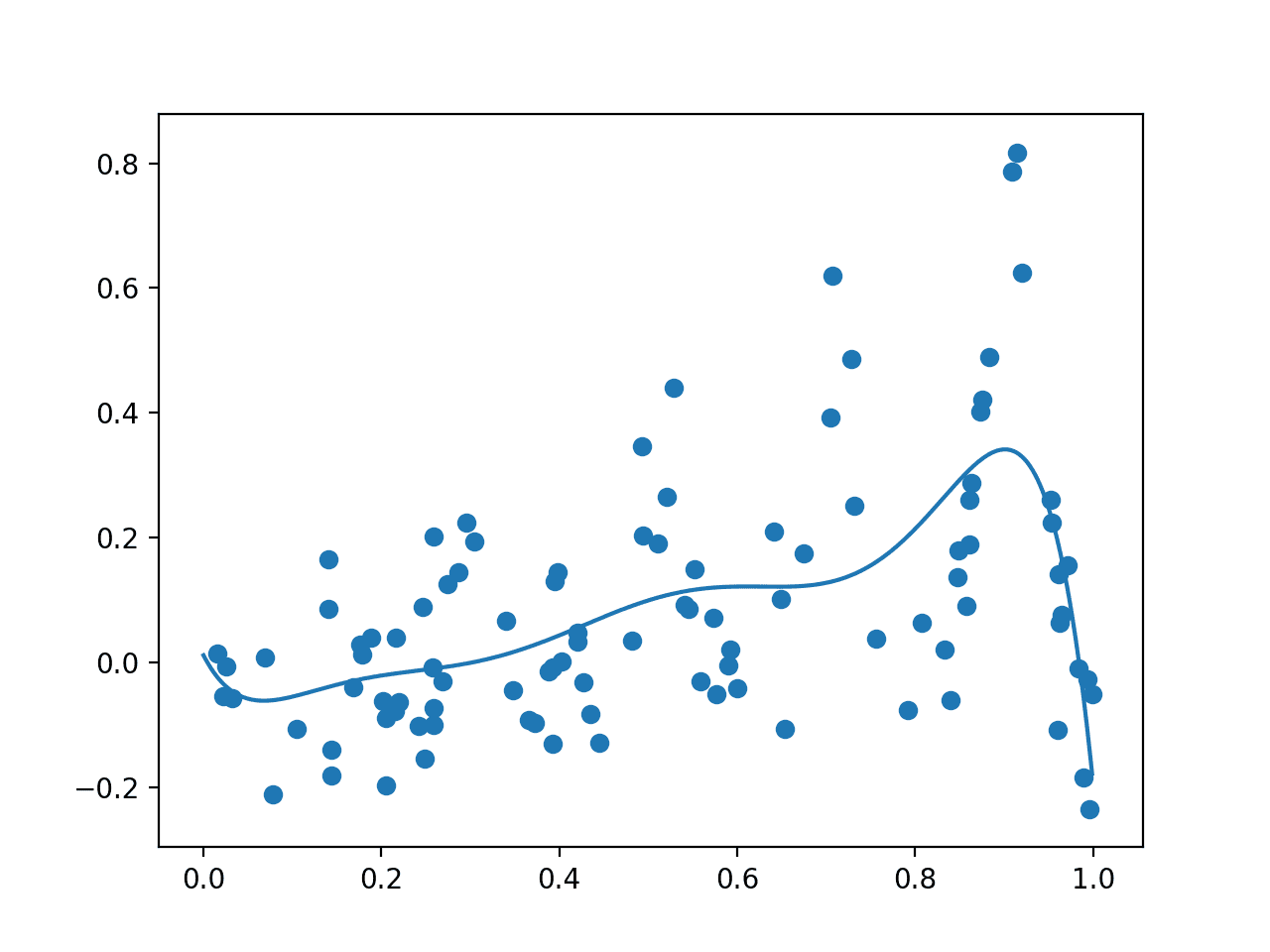
Plot Showing Random Sample With Noisy Evaluation (dots) and Surrogate Function Across the Domain (line).
Next, we must define a strategy for sampling the surrogate function.
Acquisition Function
The surrogate function is used to test a range of candidate samples in the domain.
From these results, one or more candidates can be selected and evaluated with the real, and in normal practice, computationally expensive cost function.
This involves two pieces: the search strategy used to navigate the domain in response to the surrogate function and the acquisition function that is used to interpret and score the response from the surrogate function.
A simple search strategy, such as a random sample or grid-based sample, can be used, although it is more common to use a local search strategy, such as the popular BFGS algorithm. In this case, we will use a random search or random sample of the domain in order to keep the example simple.
This involves first drawing a random sample of candidate samples from the domain, evaluating them with the acquisition function, then maximizing the acquisition function or choosing the candidate sample that gives the best score. The opt_acquisition() function below implements this.
# optimize the acquisition function def opt_acquisition(X, y, model): # random search, generate random samples Xsamples = random(100) Xsamples = Xsamples.reshape(len(Xsamples), 1) # calculate the acquisition function for each sample scores = acquisition(X, Xsamples, model) # locate the index of the largest scores ix = argmax(scores) return Xsamples[ix, 0]
The acquisition function is responsible for scoring or estimating the likelihood that a given candidate sample (input) is worth evaluating with the real objective function.
We could just use the surrogate score directly. Alternately, given that we have chosen a Gaussian Process model as the surrogate function, we can use the probabilistic information from this model in the acquisition function to calculate the probability that a given sample is worth evaluating.
There are many different types of probabilistic acquisition functions that can be used, each providing a different trade-off for how exploitative (greedy) and explorative they are.
Three common examples include:
- Probability of Improvement (PI).
- Expected Improvement (EI).
- Lower Confidence Bound (LCB).
The Probability of Improvement method is the simplest, whereas the Expected Improvement method is the most commonly used.
In this case, we will use the simpler Probability of Improvement method, which is calculated as the normal cumulative probability of the normalized expected improvement, calculated as follows:
- PI = cdf((mu – best_mu) / stdev)
Where PI is the probability of improvement, cdf() is the normal cumulative distribution function, mu is the mean of the surrogate function for a given sample x, stdev is the standard deviation of the surrogate function for a given sample x, and best_mu is the mean of the surrogate function for the best sample found so far.
We can add a very small number to the standard deviation to avoid a divide by zero error.
The acquisition() function below implements this given the current training dataset of input samples, an array of new candidate samples, and the fit GP model.
# probability of improvement acquisition function def acquisition(X, Xsamples, model): # calculate the best surrogate score found so far yhat, _ = surrogate(model, X) best = max(yhat) # calculate mean and stdev via surrogate function mu, std = surrogate(model, Xsamples) mu = mu[:, 0] # calculate the probability of improvement probs = norm.cdf((mu - best) / (std+1E-9)) return probs
Complete Bayesian Optimization Algorithm
We can tie all of this together into the Bayesian Optimization algorithm.
The main algorithm involves cycles of selecting candidate samples, evaluating them with the objective function, then updating the GP model.
...
# perform the optimization process
for i in range(100):
# select the next point to sample
x = opt_acquisition(X, y, model)
# sample the point
actual = objective(x)
# summarize the finding for our own reporting
est, _ = surrogate(model, [[x]])
print('>x=%.3f, f()=%3f, actual=%.3f' % (x, est, actual))
# add the data to the dataset
X = vstack((X, [[x]]))
y = vstack((y, [[actual]]))
# update the model
model.fit(X, y)
The complete example is listed below.
# example of bayesian optimization for a 1d function from scratch
from math import sin
from math import pi
from numpy import arange
from numpy import vstack
from numpy import argmax
from numpy import asarray
from numpy.random import normal
from numpy.random import random
from scipy.stats import norm
from sklearn.gaussian_process import GaussianProcessRegressor
from warnings import catch_warnings
from warnings import simplefilter
from matplotlib import pyplot
# objective function
def objective(x, noise=0.1):
noise = normal(loc=0, scale=noise)
return (x**2 * sin(5 * pi * x)**6.0) + noise
# surrogate or approximation for the objective function
def surrogate(model, X):
# catch any warning generated when making a prediction
with catch_warnings():
# ignore generated warnings
simplefilter("ignore")
return model.predict(X, return_std=True)
# probability of improvement acquisition function
def acquisition(X, Xsamples, model):
# calculate the best surrogate score found so far
yhat, _ = surrogate(model, X)
best = max(yhat)
# calculate mean and stdev via surrogate function
mu, std = surrogate(model, Xsamples)
mu = mu[:, 0]
# calculate the probability of improvement
probs = norm.cdf((mu - best) / (std+1E-9))
return probs
# optimize the acquisition function
def opt_acquisition(X, y, model):
# random search, generate random samples
Xsamples = random(100)
Xsamples = Xsamples.reshape(len(Xsamples), 1)
# calculate the acquisition function for each sample
scores = acquisition(X, Xsamples, model)
# locate the index of the largest scores
ix = argmax(scores)
return Xsamples[ix, 0]
# plot real observations vs surrogate function
def plot(X, y, model):
# scatter plot of inputs and real objective function
pyplot.scatter(X, y)
# line plot of surrogate function across domain
Xsamples = asarray(arange(0, 1, 0.001))
Xsamples = Xsamples.reshape(len(Xsamples), 1)
ysamples, _ = surrogate(model, Xsamples)
pyplot.plot(Xsamples, ysamples)
# show the plot
pyplot.show()
# sample the domain sparsely with noise
X = random(100)
y = asarray([objective(x) for x in X])
# reshape into rows and cols
X = X.reshape(len(X), 1)
y = y.reshape(len(y), 1)
# define the model
model = GaussianProcessRegressor()
# fit the model
model.fit(X, y)
# plot before hand
plot(X, y, model)
# perform the optimization process
for i in range(100):
# select the next point to sample
x = opt_acquisition(X, y, model)
# sample the point
actual = objective(x)
# summarize the finding
est, _ = surrogate(model, [[x]])
print('>x=%.3f, f()=%3f, actual=%.3f' % (x, est, actual))
# add the data to the dataset
X = vstack((X, [[x]]))
y = vstack((y, [[actual]]))
# update the model
model.fit(X, y)
# plot all samples and the final surrogate function
plot(X, y, model)
# best result
ix = argmax(y)
print('Best Result: x=%.3f, y=%.3f' % (X[ix], y[ix]))
Running the example first creates an initial random sample of the search space and evaluation of the results. Then a GP model is fit on this data.
Your specific results will vary given the stochastic nature of the sampling of the domain. Try running the example a few times.
A plot is created showing the raw observations as dots and the surrogate function across the entire domain. In this case, the initial sample has a good spread across the domain and the surrogate function has a bias towards the part of the domain where we know the optima is located.
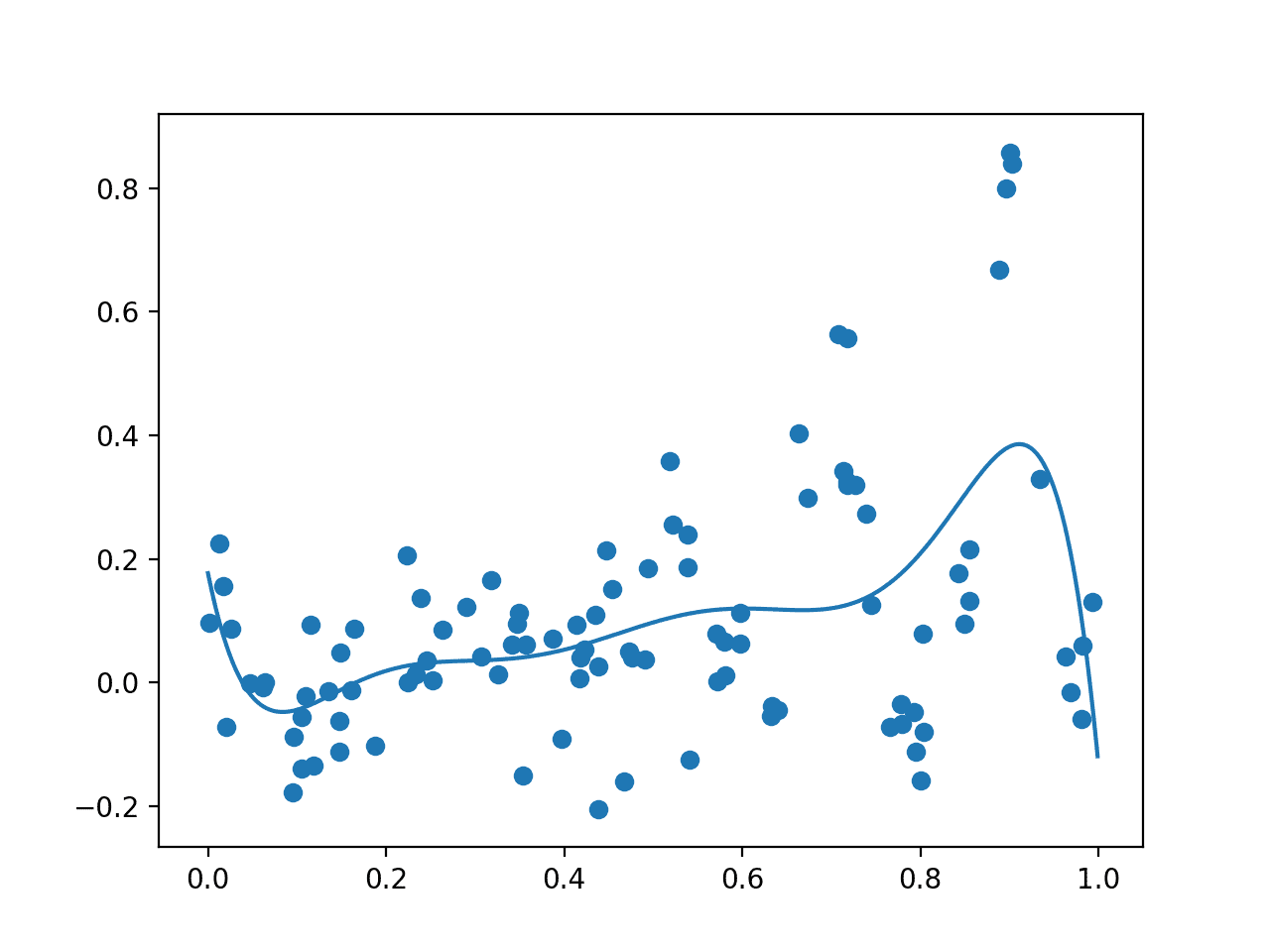
Plot of Initial Sample (dots) and Surrogate Function Across the Domain (line).
The algorithm then iterates for 100 cycles, selecting samples, evaluating them, and adding them to the dataset to update the surrogate function, and over again.
Each cycle reports the selected input value, the estimated score from the surrogate function, and the actual score. Ideally, these scores would get closer and closer as the algorithm converges on one area of the search space.
... >x=0.922, f()=0.661501, actual=0.682 >x=0.895, f()=0.661668, actual=0.905 >x=0.928, f()=0.648008, actual=0.403 >x=0.908, f()=0.674864, actual=0.750 >x=0.436, f()=0.071377, actual=-0.115
Next, a final plot is created with the same form as the prior plot.
This time, all 200 samples evaluated during the optimization task are plotted. We would expect an overabundance of sampling around the known optima, and this is what we see, with may dots around 0.9. We also see that the surrogate function has a stronger representation of the underlying target domain.
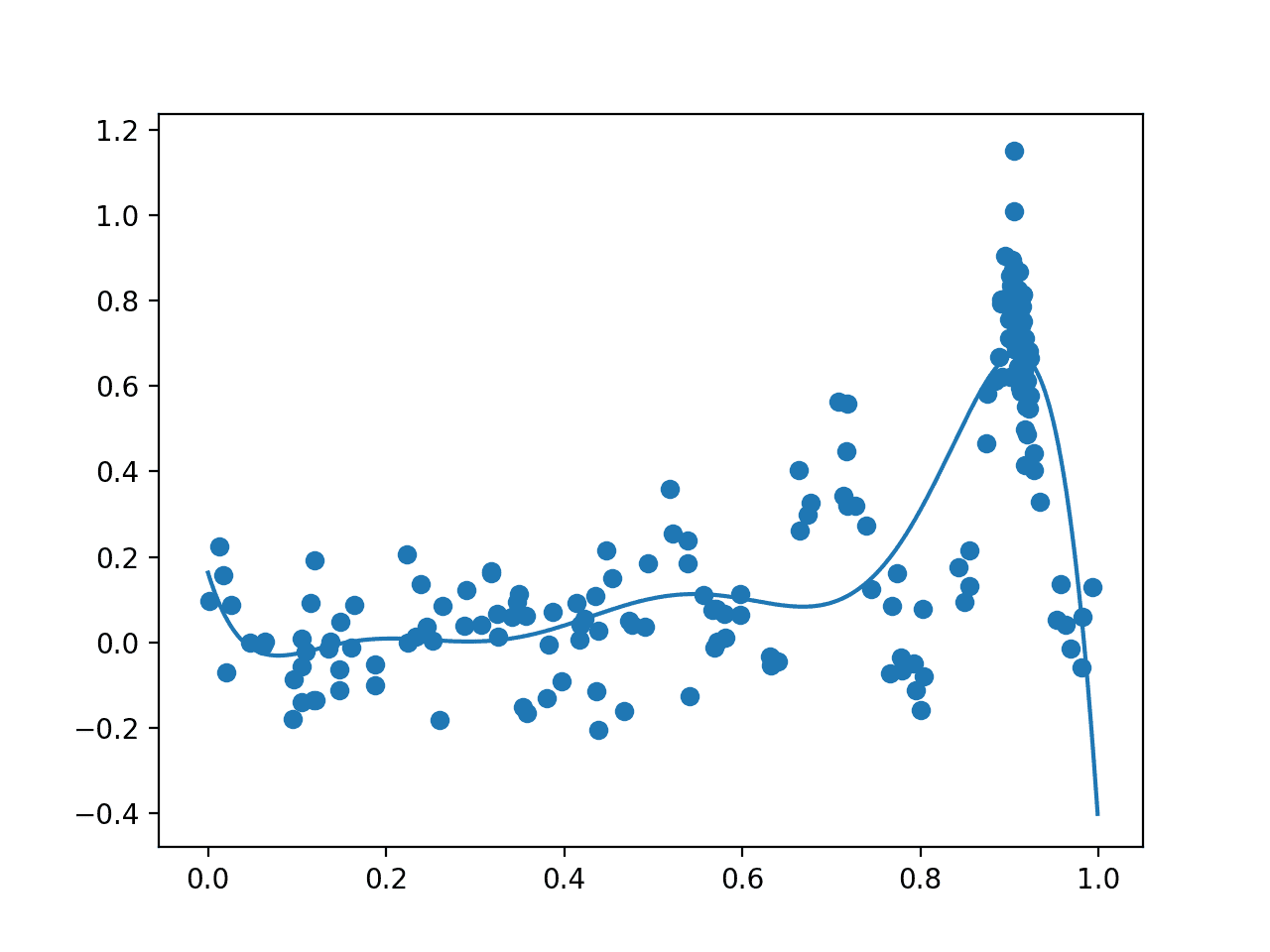
Plot of All Samples (dots) and Surrogate Function Across the Domain (line) after Bayesian Optimization.
Finally, the best input and its objective function score are reported.
We know the optima has an input of 0.9 and an output of 0.810 if there was no sampling noise.
Given the sampling noise, the optimization algorithm gets close in this case, suggesting an input of 0.905.
Best Result: x=0.905, y=1.150
Hyperparameter Tuning With Bayesian Optimization
It can be a useful exercise to implement Bayesian Optimization to learn how it works.
In practice, when using Bayesian Optimization on a project, it is a good idea to use a standard implementation provided in an open-source library. This is to both avoid bugs and to leverage a wider range of configuration options and speed improvements.
Two popular libraries for Bayesian Optimization include Scikit-Optimize and HyperOpt. In machine learning, these libraries are often used to tune the hyperparameters of algorithms.
Hyperparameter tuning is a good fit for Bayesian Optimization because the evaluation function is computationally expensive (e.g. training models for each set of hyperparameters) and noisy (e.g. noise in training data and stochastic learning algorithms).
In this section, we will take a brief look at how to use the Scikit-Optimize library to optimize the hyperparameters of a k-nearest neighbor classifier for a simple test classification problem. This will provide a useful template that you can use on your own projects.
The Scikit-Optimize project is designed to provide access to Bayesian Optimization for applications that use SciPy and NumPy, or applications that use scikit-learn machine learning algorithms.
First, the library must be installed, which can be achieved easily using pip; for example:
sudo pip install scikit-optimize
It is also assumed that you have scikit-learn installed for this example.
Once installed, there are two ways that scikit-optimize can be used to optimize the hyperparameters of a scikit-learn algorithm. The first is to perform the optimization directly on a search space, and the second is to use the BayesSearchCV class, a sibling of the scikit-learn native classes for random and grid searching.
In this example, will use the simpler approach of optimizing the hyperparameters directly.
The first step is to prepare the data and define the model. We will use a simple test classification problem via the make_blobs() function with 500 examples, each with two features and three class labels. We will then use a KNeighborsClassifier algorithm.
... # generate 2d classification dataset X, y = make_blobs(n_samples=500, centers=3, n_features=2) # define the model model = KNeighborsClassifier()
Next, we must define the search space.
In this case, we will tune the number of neighbors (n_neighbors) and the shape of the neighborhood function (p). This requires ranges be defined for a given data type. In this case, they are Integers, defined with the min, max, and the name of the parameter to the scikit-learn model. For your algorithm, you can just as easily optimize Real() and Categorical() data types.
... # define the space of hyperparameters to search search_space = [Integer(1, 5, name='n_neighbors'), Integer(1, 2, name='p')]
Next, we need to define a function that will be used to evaluate a given set of hyperparameters. We want to minimize this function, therefore smaller values returned must indicate a better performing model.
We can use the use_named_args() decorator from the scikit-optimize project on the function definition that allows the function to be called directly with a specific set of parameters from the search space.
As such, our custom function will take the hyperparameter values as arguments, which can be provided to the model directly in order to configure it. We can define these arguments generically in python using the **params argument to the function, then pass them to the model via the set_params(**) function.
Now that the model is configured, we can evaluate it. In this case, we will use 5-fold cross-validation on our dataset and evaluate the accuracy for each fold. We can then report the performance of the model as one minus the mean accuracy across these folds. This means that a perfect model with an accuracy of 1.0 will return a value of 0.0 (1.0 – mean accuracy).
This function is defined after we have loaded the dataset and defined the model so that both the dataset and model are in scope and can be used directly.
# define the function used to evaluate a given configuration @use_named_args(search_space) def evaluate_model(**params): # something model.set_params(**params) # calculate 5-fold cross validation result = cross_val_score(model, X, y, cv=5, n_jobs=-1, scoring='accuracy') # calculate the mean of the scores estimate = mean(result) return 1.0 - estimate
Next, we can perform the optimization.
This is achieved by calling the gp_minimize() function with the name of the objective function and the defined search space.
By default, this function will use a ‘gp_hedge‘ acquisition function that tries to figure out the best strategy, but this can be configured via the acq_func argument. The optimization will also run for 100 iterations by default, but this can be controlled via the n_calls argument.
... # perform optimization result = gp_minimize(evaluate_model, search_space)
Once run, we can access the best score via the “fun” property and the best set of hyperparameters via the “x” array property.
...
# summarizing finding:
print('Best Accuracy: %.3f' % (1.0 - result.fun))
print('Best Parameters: n_neighbors=%d, p=%d' % (result.x[0], result.x[1]))
Tying this all together, the complete example is listed below.
# example of bayesian optimization with scikit-optimize
from numpy import mean
from sklearn.datasets.samples_generator import make_blobs
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from skopt.space import Integer
from skopt.utils import use_named_args
from skopt import gp_minimize
# generate 2d classification dataset
X, y = make_blobs(n_samples=500, centers=3, n_features=2)
# define the model
model = KNeighborsClassifier()
# define the space of hyperparameters to search
search_space = [Integer(1, 5, name='n_neighbors'), Integer(1, 2, name='p')]
# define the function used to evaluate a given configuration
@use_named_args(search_space)
def evaluate_model(**params):
# something
model.set_params(**params)
# calculate 5-fold cross validation
result = cross_val_score(model, X, y, cv=5, n_jobs=-1, scoring='accuracy')
# calculate the mean of the scores
estimate = mean(result)
return 1.0 - estimate
# perform optimization
result = gp_minimize(evaluate_model, search_space)
# summarizing finding:
print('Best Accuracy: %.3f' % (1.0 - result.fun))
print('Best Parameters: n_neighbors=%d, p=%d' % (result.x[0], result.x[1]))
Running the example executes the hyperparameter tuning using Bayesian Optimization.
The code may report many warning messages, such as:
UserWarning: The objective has been evaluated at this point before.
This is to be expected and is caused by the same hyperparameter configuration being evaluated more than once.
Your specific results will vary given the stochastic nature of the test problem. Try running the example a few times.
In this case, the model achieved about 97% accuracy via mean 5-fold cross-validation with 3 neighbors and a p-value of 2.
Best Accuracy: 0.976 Best Parameters: n_neighbors=3, p=2
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning, 2010.
- Practical Bayesian Optimization of Machine Learning Algorithms, 2012.
- A Tutorial on Bayesian Optimization, 2018.
API
- Gaussian Processes, Scikit-Learn API.
- Hyperopt: Distributed Asynchronous Hyper-parameter Optimization
- Scikit-Optimize Project.
- Tuning a scikit-learn estimator with skopt
Articles
- Global optimization, Wikipedia.
- Bayesian optimization, Wikipedia.
- Bayesian optimization, 2018.
- How does Bayesian optimization work?, Quora.
Summary
In this tutorial, you discovered Bayesian Optimization for directed search of complex optimization problems.
Specifically, you learned:
- Global optimization is a challenging problem that involves black box and often non-convex, non-linear, noisy, and computationally expensive objective functions.
- Bayesian Optimization provides a probabilistically principled method for global optimization.
- How to implement Bayesian Optimization from scratch and how to use open-source implementations.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Implement Bayesian Optimization from Scratch in Python appeared first on Machine Learning Mastery.