
Author: Jason Brownlee
Feature selection is the process of reducing the number of input variables when developing a predictive model.
It is desirable to reduce the number of input variables to both reduce the computational cost of modeling and, in some cases, to improve the performance of the model.
Feature-based feature selection methods involve evaluating the relationship between each input variable and the target variable using statistics and selecting those input variables that have the strongest relationship with the target variable. These methods can be fast and effective, although the choice of statistical measures depends on the data type of both the input and output variables.
As such, it can be challenging for a machine learning practitioner to select an appropriate statistical measure for a dataset when performing filter-based feature selection.
In this post, you will discover how to choose statistical measures for filter-based feature selection with numerical and categorical data.
After reading this post, you will know:
- There are two main types of feature selection techniques: wrapper and filter methods.
- Filter-based feature selection methods use statistical measures to score the correlation or dependence between input variables that can be filtered to choose the most relevant features.
- Statistical measures for feature selection must be carefully chosen based on the data type of the input variable and the output or response variable.
Let’s get started.

How to Develop a Probabilistic Model of Breast Cancer Patient Survival
Photo by Tanja-Milfoil, some rights reserved.
Overview
This tutorial is divided into three parts; they are:
- Feature Selection Methods
- Statistics for Filter Feature Selection Methods
- Tips and Tricks for Feature Selection
Feature Selection Methods
Feature selection methods are intended to reduce the number of input variables to those that are believed to be most useful to a model in order to predict the target variable.
Some predictive modeling problems have a large number of variables that can slow the development and training of models and require a large amount of system memory. Additionally, the performance of some models can degrade when including input variables that are not relevant to the target variable.
There are two main types of feature selection algorithms: wrapper methods and filter methods.
- Wrapper Feature Selection Methods.
- Filter Feature Selection Methods.
Wrapper feature selection methods create many models with different subsets of input features and select those features that result in the best performing model according to a performance metric. These methods are unconcerned with the variable types, although they can be computationally expensive. RFE is a good example of a wrapper feature selection method.
Wrapper methods evaluate multiple models using procedures that add and/or remove predictors to find the optimal combination that maximizes model performance.
— Page 490, Applied Predictive Modeling, 2013.
Filter feature selection methods use statistical techniques to evaluate the relationship between each input variable and the target variable, and these scores are used as the basis to choose (filter) those input variables that will be used in the model.
Filter methods evaluate the relevance of the predictors outside of the predictive models and subsequently model only the predictors that pass some criterion.
— Page 490, Applied Predictive Modeling, 2013.
It is common to use correlation type statistical measures between input and output variables as the basis for filter feature selection. As such, the choice of statistical measures is highly dependent upon the variable data types.
Common data types include numerical (such as height) and categorical (such as a label), although each may be further subdivided such as integer and floating point for numerical variables, and boolean, ordinal, or nominal for categorical variables.
Common input variable data types:
- Numerical Variables
- Integer Variables.
- Floating Point Variables.
- Categorical Variables.
- Boolean Variables (dichotomous).
- Ordinal Variables.
- Nominal Variables.
The more that is known about the data type of a variable, the easier it is to choose an appropriate statistical measure for a filter-based feature selection method.
In the next section, we will review some of the statistical measures that may be used for filter-based feature selection with different input and output variable data types.
Statistics for Filter-Based Feature Selection Methods
In this section, we will consider two broad categories of variable types: numerical and categorical; also, the two main groups of variables to consider: input and output.
Input variables are those that are provided as input to a model. In feature selection, it is this group of variables that we wish to reduce in size. Output variables are those for which a model is intended to predict, often called the response variable.
The type of response variable typically indicates the type of predictive modeling problem being performed. For example, a numerical output variable indicates a regression predictive modeling problem, and a categorical output variable indicates a classification predictive modeling problem.
- Numerical Output: Regression predictive modeling problem.
- Categorical Output: Classification predictive modeling problem.
The statistical measures used in filter-based feature selection are generally calculated one input variable at a time with the target variable. As such, they are referred to as univariate statistical measures. This may mean that any interaction between input variables is not considered in the filtering process.
Most of these techniques are univariate, meaning that they evaluate each predictor in isolation. In this case, the existence of correlated predictors makes it possible to select important, but redundant, predictors. The obvious consequences of this issue are that too many predictors are chosen and, as a result, collinearity problems arise.
— Page 499, Applied Predictive Modeling, 2013.
With this framework, let’s review some univariate statistical measures that can be used for filter-based feature selection.
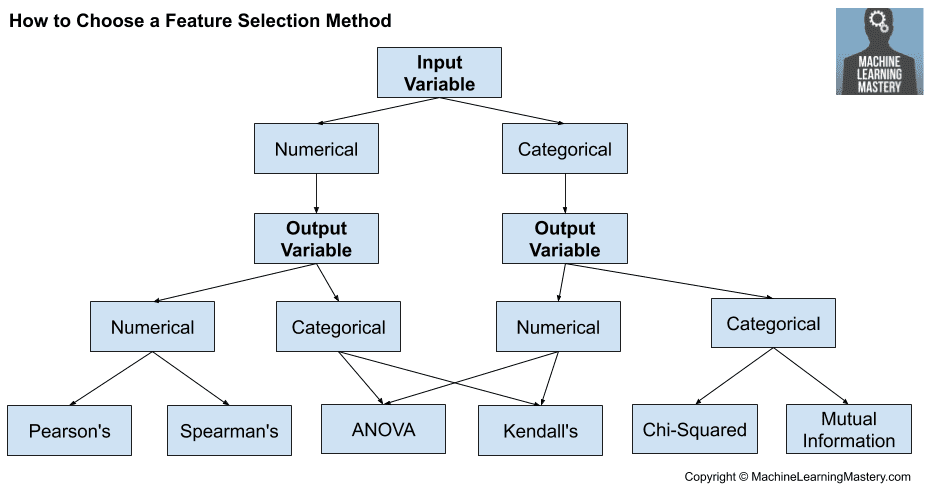
How to Choose Feature Selection Methods For Machine Learning
Numerical Input, Numerical Output
This is a regression predictive modeling problem with numerical input variables.
The most common techniques are to use a correlation coefficient, such as Pearson’s for a linear correlation, or rank-based methods for a nonlinear correlation.
- Pearson’s correlation coefficient (linear).
- Spearman’s rank coefficient (nonlinear)
Numerical Input, Categorical Output
This is a classification predictive modeling problem with numerical input variables.
This might be the most common example of a classification problem,
Again, the most common techniques are correlation based, although in this case, they must take the categorical target into account.
- ANOVA correlation coefficient (linear).
- Kendall’s rank coefficient (nonlinear).
Kendall does assume that the categorical variable is ordinal.
Categorical Input, Numerical Output
This is a regression predictive modeling problem with categorical input variables.
This is a strange example of a regression problem (e.g. you would not encounter it often).
Nevertheless, you can use the same “Numerical Input, Categorical Output” methods (described above), but in reverse.
Categorical Input, Categorical Output
This is a classification predictive modeling problem with categorical input variables.
The most common correlation measure for categorical data is the chi-squared test. You can also use mutual information (information gain) from the field of information theory.
- Chi-Squared test (contingency tables).
- Mutual Information.
In fact, mutual information is a powerful method that may prove useful for both categorical and numerical data, e.g. it is agnostic to the data types.
Tips and Tricks for Feature Selection
This section provides some additional considerations when using filter-based feature selection.
Correlation Statistics
The scikit-learn library provides an implementation of most of the useful statistical measures.
For example:
- Pearson’s Correlation Coefficient: f_regression()
- ANOVA: f_classif()
- Chi-Squared: chi2()
- Mutual Information: mutual_info_classif() and mutual_info_regression()
Also, the SciPy library provides an implementation of many more statistics, such as Kendall’s tau (kendalltau) and Spearman’s rank correlation (spearmanr).
Selection Method
The scikit-learn library also provides many different filtering methods once statistics have been calculated for each input variable with the target.
Two of the more popular methods include:
- Select the top k variables: SelectKBest
- Select the top percentile variables: SelectPercentile
I often use SelectKBest myself.
Transform Variables
Consider transforming the variables in order to access different statistical methods.
For example, you can transform a categorical variable to ordinal, even if it is not, and see if any interesting results come out.
You can also make a numerical variable discrete (e.g. bins); try categorical-based measures.
Some statistical measures assume properties of the variables, such as Pearson’s that assumes a Gaussian probability distribution to the observations and a linear relationship. You can transform the data to meet the expectations of the test and try the test regardless of the expectations and compare results.
What Is the Best Method?
There is no best feature selection method.
Just like there is no best set of input variables or best machine learning algorithm. At least not universally.
Instead, you must discover what works best for your specific problem using careful systematic experimentation.
Try a range of different models fit on different subsets of features chosen via different statistical measures and discover what works best for your specific problem.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Posts
- How to Calculate Nonparametric Rank Correlation in Python
- How to Calculate Correlation Between Variables in Python
- Feature Selection For Machine Learning in Python
- An Introduction to Feature Selection
Articles
- Feature selection, scikit-learn API.
- What are the feature selection options for categorical data? Quora.
Summary
In this post, you discovered how to choose statistical measures for filter-based feature selection with numerical and categorical data.
Specifically, you learned:
- There are two main types of feature selection techniques: wrapper and filter methods.
- Filter-based feature selection methods use statistical measures to score the correlation or dependence between input variables that can be filtered to choose the most relevant features.
- Statistical measures for feature selection must be carefully chosen based on the data type of the input variable and the output or response variable.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Choose a Feature Selection Method For Machine Learning appeared first on Machine Learning Mastery.