
Author: Jason Brownlee
Developing a probabilistic model is challenging in general, although it is made more so when there is skew in the distribution of cases, referred to as an imbalanced dataset.
The Haberman Dataset describes the five year or greater survival of breast cancer patient patients in the 1950s and 1960s and mostly contains patients that survive. This standard machine learning dataset can be used as the basis of developing a probabilistic model that predicts the probability of survival of a patient given a few details of their case.
Given the skewed distribution in cases in the dataset, careful attention must be paid to both the choice of predictive models to ensure that calibrated probabilities are predicted, and to the choice of model evaluation to ensure that the models are selected based on the skill of their predicted probabilities rather than crisp survival vs. non-survival class labels.
In this tutorial, you will discover how to develop a model to predict the probability of patient survival on an imbalanced dataset.
After completing this tutorial, you will know:
- How to load and explore the dataset and generate ideas for data preparation and model selection.
- How to evaluate a suite of probabilistic models and improve their performance with appropriate data preparation.
- How to fit a final model and use it to predict probabilities for specific cases.
Discover SMOTE, one-class classification, cost-sensitive learning, threshold moving, and much more in my new book, with 30 step-by-step tutorials and full Python source code.
Let’s get started.

How to Develop a Probabilistic Model of Breast Cancer Patient Survival
Photo by Tanja-Milfoil, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Haberman Breast Cancer Survival Dataset
- Explore the Dataset
- Model Test and Baseline Result
- Evaluate Probabilistic Models
- Probabilistic Algorithm Evaluation
- Model Evaluation With Scaled Inputs
- Model Evaluation With Power Transforms
- Make Prediction on New Data
Haberman Breast Cancer Survival Dataset
In this project, we will use a small breast cancer survival dataset, referred to generally as the “Haberman Dataset.”
The dataset describes breast cancer patient data and the outcome is patient survival. Specifically whether the patient survived for five years or longer, or whether the patient did not survive.
This is a standard dataset used in the study of imbalanced classification. According to the dataset description, the operations were conducted between 1958 and 1970 at the University of Chicago’s Billings Hospital.
There are 306 examples in the dataset, and there are 3 input variables; they are:
- The age of the patient at the time of the operation.
- The two-digit year of the operation.
- The number of “positive axillary nodes” detected, a measure of a cancer has spread.
As such, we have no control over the selection of cases that make up the dataset or features to use in those cases, other than what is available in the dataset.
Although the dataset describes breast cancer patient survival, given the small dataset size and the fact the data is based on breast cancer diagnosis and operations many decades ago, any models built on this dataset are not expected to generalize.
To be crystal clear, we are not “solving breast cancer.” We are exploring a standard imbalanced classification dataset.
You can learn more about the dataset here:
We will choose to frame this dataset as the prediction of a probability of patient survival.
That is:
Given patient breast cancer surgery details, what is the probability of survival of the patient to five years or more?
This will provide the basis for exploring probabilistic algorithms that can predict a probability instead of a class label and metrics for evaluating models that predict probabilities instead of class labels.
Next, let’s take a closer look at the data.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Explore the Dataset
First, download the dataset and save it in your current working directory with the name “haberman.csv“.
Review the contents of the file.
The first few lines of the file should look as follows:
30,64,1,1 30,62,3,1 30,65,0,1 31,59,2,1 31,65,4,1 33,58,10,1 33,60,0,1 34,59,0,2 34,66,9,2 34,58,30,1 ...
We can see that the patients have an age like 30 or 31 (column 1), that operations occurred in years like 64 and 62 for 1964 and 1962 respectively (column 2), and that “axillary nodes” has values like 1 and 0.
All values are numeric; specifically, they are integer. There are no missing values marked with a “?” character.
We can also see that the class label (column 3) has a value of either 1 for patient survival and 2 for patient non-survival.
Firstly, we can load the CSV dataset and summarize each column using a five-number summary. The dataset can be loaded as a DataFrame using the read_csv() Pandas function, specifying the location and the names of the columns as there is no header line.
... # define the dataset location filename = 'haberman.csv' # define the dataset column names columns = ['age', 'year', 'nodes', 'class'] # load the csv file as a data frame dataframe = read_csv(filename, header=None, names=columns)
We can then call the describe() function to create a report of the five-number summary of each column and print the contents of the report.
A five-number summary for a column includes useful details like the min and max values, the mean and standard deviation of which are useful if the variable has a Gaussian distribution, and the 25th, 50th, and 75th quartiles, which are useful if the variable does not have a Gaussian distribution.
... # summarize each column report = dataframe.describe() print(report)
Tying this together, the complete example of loading and summarizing the dataset columns is listed below.
# load and summarize the dataset from pandas import read_csv # define the dataset location filename = 'haberman.csv' # define the dataset column names columns = ['age', 'year', 'nodes', 'class'] # load the csv file as a data frame dataframe = read_csv(filename, header=None, names=columns) # summarize each column report = dataframe.describe() print(report)
Running the example loads the dataset and reports a five-number summary for each of the three input variables and the output variable.
Looking at the age, we can see that the youngest patient was 30 and the oldest was 83; that is quite a spread. The mean patient age was about 52 years. If the occurrence of cancer is somewhat random, we might expect this distribution to be Gaussian.
We can see that all operations were performed between 1958 and 1969. If the number of breast cancer patients is somewhat fixed over time, we might expect this variable to have a uniform distribution.
We can see nodes have values between 0 and 52. This might be a cancer diagnostic related to lymphatic nodes.
age year nodes class count 306.000000 306.000000 306.000000 306.000000 mean 52.457516 62.852941 4.026144 1.264706 std 10.803452 3.249405 7.189654 0.441899 min 30.000000 58.000000 0.000000 1.000000 25% 44.000000 60.000000 0.000000 1.000000 50% 52.000000 63.000000 1.000000 1.000000 75% 60.750000 65.750000 4.000000 2.000000 max 83.000000 69.000000 52.000000 2.000000
All variables are integers. Therefore, it might be helpful to look at each variable as a histogram to get an idea of the variable distribution.
This might be helpful in case we choose models later that are sensitive to the data distribution or scale of the data, in which case, we might need to transform or rescale the data.
We can create a histogram of each variable in the DataFrame by calling the hist() function.
The complete example is listed below.
# create histograms of each variable from pandas import read_csv from matplotlib import pyplot # define the dataset location filename = 'haberman.csv' # define the dataset column names columns = ['age', 'year', 'nodes', 'class'] # load the csv file as a data frame dataframe = read_csv(filename, header=None, names=columns) # create a histogram plot of each variable dataframe.hist() pyplot.show()
Running the example creates a histogram for each variable.
We can see that age appears to have a Gaussian distribution, as we might have expected. We can also see that year has a uniform distribution, mostly, with an outlier in the first year showing nearly double the number of operations.
We can see nodes has an exponential type distribution with perhaps most examples showing 0 nodes, with a long tail of values after that. A transform to un-bunch this distribution might help some models later on.
Finally, we can see the two-class values with an unequal class distribution, showing perhaps 2- or 3-times more survival than non-survival cases.
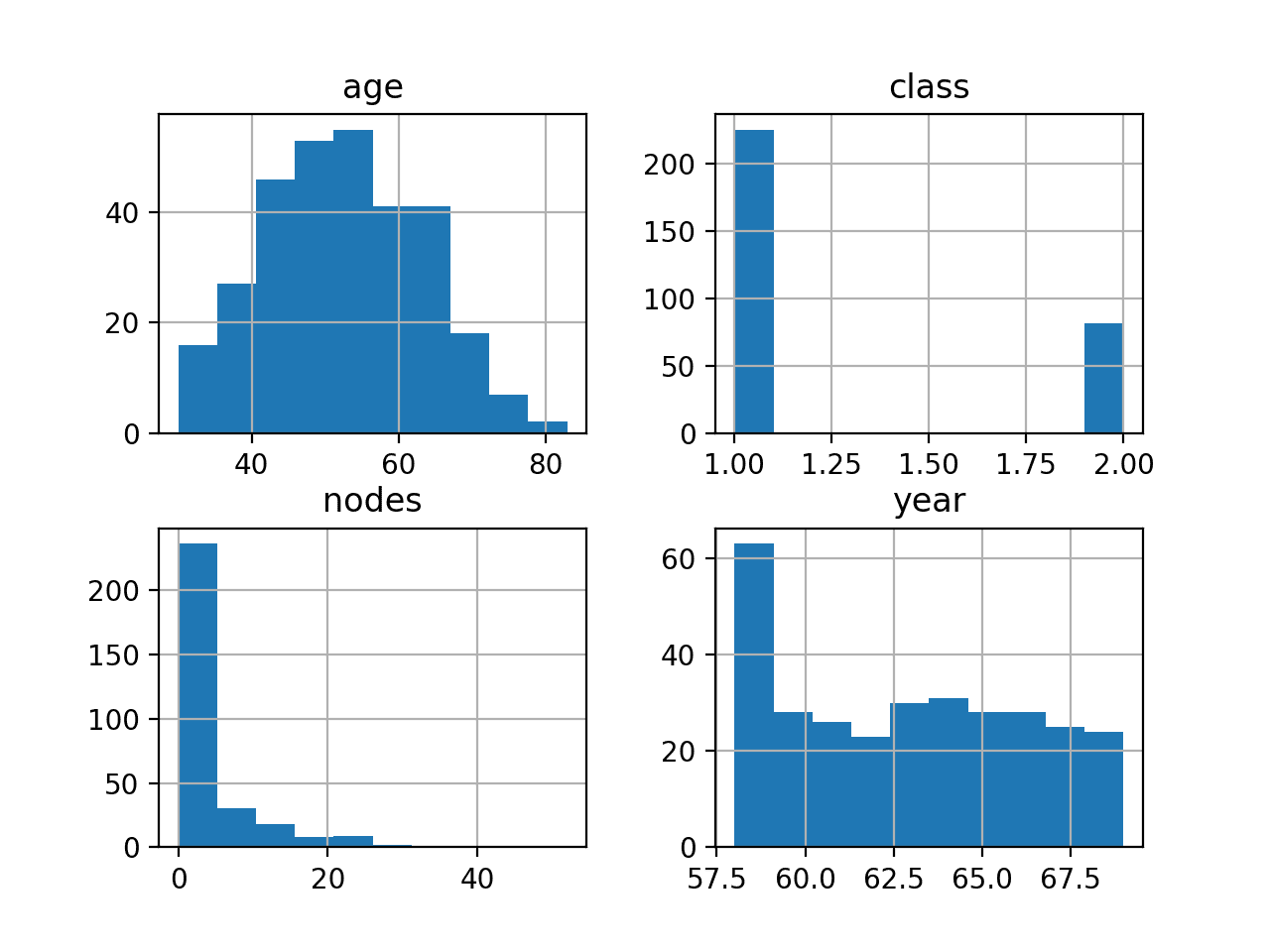
Histogram of Each Variable in the Haberman Breast Cancer Survival Dataset
It may be helpful to know how imbalanced the dataset actually is.
We can use the Counter object to count the number of examples in each class, then use those counts to summarize the distribution.
The complete example is listed below.
# summarize the class ratio
from pandas import read_csv
from collections import Counter
# define the dataset location
filename = 'haberman.csv'
# define the dataset column names
columns = ['age', 'year', 'nodes', 'class']
# load the csv file as a data frame
dataframe = read_csv(filename, header=None, names=columns)
# summarize the class distribution
target = dataframe['class'].values
counter = Counter(target)
for k,v in counter.items():
per = v / len(target) * 100
print('Class=%d, Count=%d, Percentage=%.3f%%' % (k, v, per))
Running the example summarizes the class distribution for the dataset.
We can see that class 1 for survival has the most examples at 225, or about 74 percent of the dataset. We can see class 2 for non-survival has fewer examples at 81, or about 26 percent of the dataset.
The class distribution is skewed, but it is not severely imbalanced.
Class=1, Count=225, Percentage=73.529% Class=2, Count=81, Percentage=26.471%
Now that we have reviewed the dataset, let’s look at developing a test harness for evaluating candidate models.
Model Test and Baseline Result
We will evaluate candidate models using repeated stratified k-fold cross-validation.
The k-fold cross-validation procedure provides a good general estimate of model performance that is not too optimistically biased, at least compared to a single train-test split. We will use k=10, meaning each fold will contain 306/10 or about 30 examples.
Stratified means that each fold will contain the same mixture of examples by class, that is about 74 percent to 26 percent survival and non-survival.
Repeated means that the evaluation process will be performed multiple times to help avoid fluke results and better capture the variance of the chosen model. We will use three repeats.
This means a single model will be fit and evaluated 10 * 3, or 30, times and the mean and standard deviation of these runs will be reported.
This can be achieved using the RepeatedStratifiedKFold scikit-learn class.
Given that we are interested in predicting a probability of survival, we need a performance metric that evaluates the skill of a model based on the predicted probabilities. In this case, we will the Brier score that calculates the mean squared error between the predicted probabilities and the expected probabilities.
This can be calculated using the brier_score_loss() scikit-learn function. This score is minimized, with a perfect score of 0.0. We can invert the score to be maximizing by comparing a predicted score to a reference score, showing how much better the model is compared to the reference between 0.0 for the same, to 1.0 with perfect skill. Any models that achieves a score less than 0.0 represents less skill than the reference model. This is called the Brier Skill Score, or BSS for short.
- BrierSkillScore = 1.0 – (ModelBrierScore / ReferenceBrierScore)
It is customary for an imbalanced dataset to model the minority class as a positive class. In this dataset, the positive class represents non-survival. This means, that we will be predicting the probability of non-survival and will need to calculate the complement of the predicted probability in order to get the probability of survival.
As such, we can map the 1 class values (survival) to the negative case with a 0 class label, and the 2 class values (non-survival) to the positive case with a class label of 1. This can be achieved using the LabelEncoder class.
For example, the load_dataset() function below will load the dataset, split the variable columns into input and outputs, and then encode the target variable to 0 and 1 values.
# load the dataset def load_dataset(full_path): # load the dataset as a numpy array data = read_csv(full_path, header=None) # retrieve numpy array data = data.values # split into input and output elements X, y = data[:, :-1], data[:, -1] # label encode the target variable to have the classes 0 and 1 y = LabelEncoder().fit_transform(y) return X, y
Next, we can calculate the Brier skill score for a model.
First, we need a Brier score for a reference prediction. A reference prediction for a problem in which we are predicting probabilities is the probability of the positive class label in the dataset.
In this case, the positive class label represents non-survival and occurs about 26% in the dataset. Therefore, predicting about 0.26471 represents the worst-case or baseline performance for a predictive model on this dataset. Any model that has a Brier score better than this has some skill, where as any model that as a Brier score lower than this has no skill. The Brier Skill Score captures this important relationship. We can calculate the Brier score for this default prediction strategy automatically for each training set in the k-fold cross-validation process, then use it as a point of comparison for a given model.
... # calculate reference brier score ref_probs = [0.26471 for _ in range(len(y_true))] bs_ref = brier_score_loss(y_true, ref_probs)
The Brier score can then be calculated for the predictions from a model and used in the calculation of the Brier Skill Score.
The brier_skill_score() function below implements this and calculates the Brier Skill Score for a given set of true labels and predictions on the same test set. Any model that achieves a BSS above 0.0 means it shows skill on this dataset.
# calculate brier skill score (BSS) def brier_skill_score(y_true, y_prob): # calculate reference brier score pos_prob = count_nonzero(y_true) / len(y_true) ref_probs = [pos_prob for _ in range(len(y_true))] bs_ref = brier_score_loss(y_true, ref_probs) # calculate model brier score bs_model = brier_score_loss(y_true, y_prob) # calculate skill score return 1.0 - (bs_model / bs_ref)
Next, we can make use of the brier_skill_score() function to evaluate a model using repeated stratified k-fold cross-validation.
To use our custom performance metric, we can use the make_scorer() scikit-learn function that takes the name of our custom function and creates a metric that we can use to evaluate models with the scikit-learn API. We will set the needs_proba argument to True to ensure that models that are evaluated make predictions using the predict_proba() function to ensure they give probabilities instead of class labels.
... # define the model evaluation the metric metric = make_scorer(brier_skill_score, needs_proba=True)
The evaluate_model() function below defines the evaluation procedure with our custom evaluation metric, taking the entire training dataset and model as input, then returns the sample of scores across each fold and each repeat.
# evaluate a model def evaluate_model(X, y, model): # define evaluation procedure cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # define the model evaluation the metric metric = make_scorer(brier_skill_score, needs_proba=True) # evaluate model scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) return scores
Finally, we can use our three functions and evaluate a model.
First, we can load the dataset and summarize the input and output arrays to confirm they were loaded correctly.
... # define the location of the dataset full_path = 'haberman.csv' # load the dataset X, y = load_dataset(full_path) # summarize the loaded dataset print(X.shape, y.shape, Counter(y))
In this case, we will evaluate the baseline strategy of predicting the distribution of positive examples in the training set as the probability of each case in the test set.
This can be implemented automatically using the DummyClassifier class and setting the “strategy” to “prior” that will predict the prior probability of each class in the training dataset, which for the positive class we know is about 0.26471.
... # define the reference model model = DummyClassifier(strategy='prior')
We can then evaluate the model by calling our evaluate_model() function and report the mean and standard deviation of the results.
...
# evaluate the model
scores = evaluate_model(X, y, model)
# summarize performance
print('Mean BSS: %.3f (%.3f)' % (mean(scores), std(scores)))
Tying this all together, the complete example of evaluating the baseline model on the Haberman breast cancer survival dataset using the Brier Skill Score is listed below.
We would expect the baseline model to achieve a BSS of 0.0, e.g. the same as the reference model because it is the reference model.
# baseline model and test harness for the haberman dataset
from collections import Counter
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.metrics import brier_score_loss
from sklearn.metrics import make_scorer
from sklearn.dummy import DummyClassifier
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data = read_csv(full_path, header=None)
# retrieve numpy array
data = data.values
# split into input and output elements
X, y = data[:, :-1], data[:, -1]
# label encode the target variable to have the classes 0 and 1
y = LabelEncoder().fit_transform(y)
return X, y
# calculate brier skill score (BSS)
def brier_skill_score(y_true, y_prob):
# calculate reference brier score
ref_probs = [0.26471 for _ in range(len(y_true))]
bs_ref = brier_score_loss(y_true, ref_probs)
# calculate model brier score
bs_model = brier_score_loss(y_true, y_prob)
# calculate skill score
return 1.0 - (bs_model / bs_ref)
# evaluate a model
def evaluate_model(X, y, model):
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define the model evaluation the metric
metric = make_scorer(brier_skill_score, needs_proba=True)
# evaluate model
scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1)
return scores
# define the location of the dataset
full_path = 'haberman.csv'
# load the dataset
X, y = load_dataset(full_path)
# summarize the loaded dataset
print(X.shape, y.shape, Counter(y))
# define the reference model
model = DummyClassifier(strategy='prior')
# evaluate the model
scores = evaluate_model(X, y, model)
# summarize performance
print('Mean BSS: %.3f (%.3f)' % (mean(scores), std(scores)))
Running the example first loads the dataset and reports the number of cases correctly as 306 and the distribution of class labels for the negative and positive cases as we expect.
The DummyClassifier with our default strategy is then evaluated using repeated stratified k-fold cross-validation and the mean and standard deviation of the Brier Skill Score is reported as 0.0. This is as we expected, as we are using the test harness to evaluate the reference strategy.
(306, 3) (306,) Counter({0: 225, 1: 81})
Mean BSS: -0.000 (0.000)
Now that we have a test harness and a baseline in performance, we can begin to evaluate some models on this dataset.
Evaluate Probabilistic Models
In this section, we will use the test harness developed in the previous section to evaluate a suite of algorithms and then improvements to those algorithms, such as data preparation schemes.
Probabilistic Algorithm Evaluation
We will evaluate a suite of models that are known to be effective at predicting probabilities.
Specifically, these are models that are fit under a probabilistic framework and explicitly predict a calibrated probability for each example. A such, this makes them well-suited to this dataset, even with the class imbalance.
We will evaluate the following six probabilistic models implemented with the scikit-learn library:
- Logistic Regression (LogisticRegression)
- Linear Discriminant Analysis (LinearDiscriminantAnalysis)
- Quadratic Discriminant Analysis (QuadraticDiscriminantAnalysis)
- Gaussian Naive Bayes (GaussianNB)
- Multinomial Naive Bayes (MultinomialNB)
- Gaussian Process Classifier (GaussianProcessClassifier)
We are interested in directly comparing the results from each of these algorithms. We will compare each algorithm based on the mean score, as well as based on their distribution of scores.
We can define a list of the models that we want to evaluate, each with their default configuration or configured as to not produce a warning.
... # define models models = [LogisticRegression(solver='lbfgs'), LinearDiscriminantAnalysis(), QuadraticDiscriminantAnalysis(), GaussianNB(), MultinomialNB(), GaussianProcessClassifier()]
We can then enumerate each model, record a unique name for the model, evaluate it, and report the mean BSS and store the results for the end of the run.
...
names, values = list(), list()
# evaluate each model
for model in models:
# get a name for the model
name = type(model).__name__[:7]
# evaluate the model and store results
scores = evaluate_model(X, y, model)
# summarize and store
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
names.append(name)
values.append(scores)
At the end of the run, we can then create a box and whisker plot that shows the distribution of results from each algorithm, where the box shows the 25th, 50th, and 75th percentiles of the scores and the triangle shows the mean result. The whiskers of each plot give an idea of the extremes of each distribution.
... # plot the results pyplot.boxplot(values, labels=names, showmeans=True) pyplot.show()
Tying this together, the complete example is listed below.
# compare probabilistic model on the haberman dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from matplotlib import pyplot
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.metrics import brier_score_loss
from sklearn.metrics import make_scorer
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.gaussian_process import GaussianProcessClassifier
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data = read_csv(full_path, header=None)
# retrieve numpy array
data = data.values
# split into input and output elements
X, y = data[:, :-1], data[:, -1]
# label encode the target variable to have the classes 0 and 1
y = LabelEncoder().fit_transform(y)
return X, y
# calculate brier skill score (BSS)
def brier_skill_score(y_true, y_prob):
# calculate reference brier score
ref_probs = [0.26471 for _ in range(len(y_true))]
bs_ref = brier_score_loss(y_true, ref_probs)
# calculate model brier score
bs_model = brier_score_loss(y_true, y_prob)
# calculate skill score
return 1.0 - (bs_model / bs_ref)
# evaluate a model
def evaluate_model(X, y, model):
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define the model evaluation the metric
metric = make_scorer(brier_skill_score, needs_proba=True)
# evaluate model
scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1)
return scores
# define the location of the dataset
full_path = 'haberman.csv'
# load the dataset
X, y = load_dataset(full_path)
# define models
models = [LogisticRegression(solver='lbfgs'), LinearDiscriminantAnalysis(),
QuadraticDiscriminantAnalysis(), GaussianNB(), MultinomialNB(),
GaussianProcessClassifier()]
names, values = list(), list()
# evaluate each model
for model in models:
# get a name for the model
name = type(model).__name__[:7]
# evaluate the model and store results
scores = evaluate_model(X, y, model)
# summarize and store
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
names.append(name)
values.append(scores)
# plot the results
pyplot.boxplot(values, labels=names, showmeans=True)
pyplot.show()
Running the example first summarizes the mean and standard deviation of the BSS for each algorithm (larger scores is better).
Your specific results will vary given the stochastic nature of the learning algorithms; consider running the example a few times.
In this case, the results suggest that only two of the algorithms are not skillful, showing negative scores, and that perhaps the LogisticRegression (LR) and LinearDiscriminantAnalysis (LDA) algorithms are the best performing.
>Logisti 0.064 (0.123) >LinearD 0.067 (0.136) >Quadrat 0.027 (0.212) >Gaussia 0.011 (0.209) >Multino -0.213 (0.380) >Gaussia -0.141 (0.047)
A box and whisker plot is created summarizing the distribution of results.
Interestingly, most if not all algorithms show a spread indicating that they may be unskilful on some of the runs. The distribution between the two topperforming models appears roughly equivalent, so choosing a model based on mean performance might be a good start.
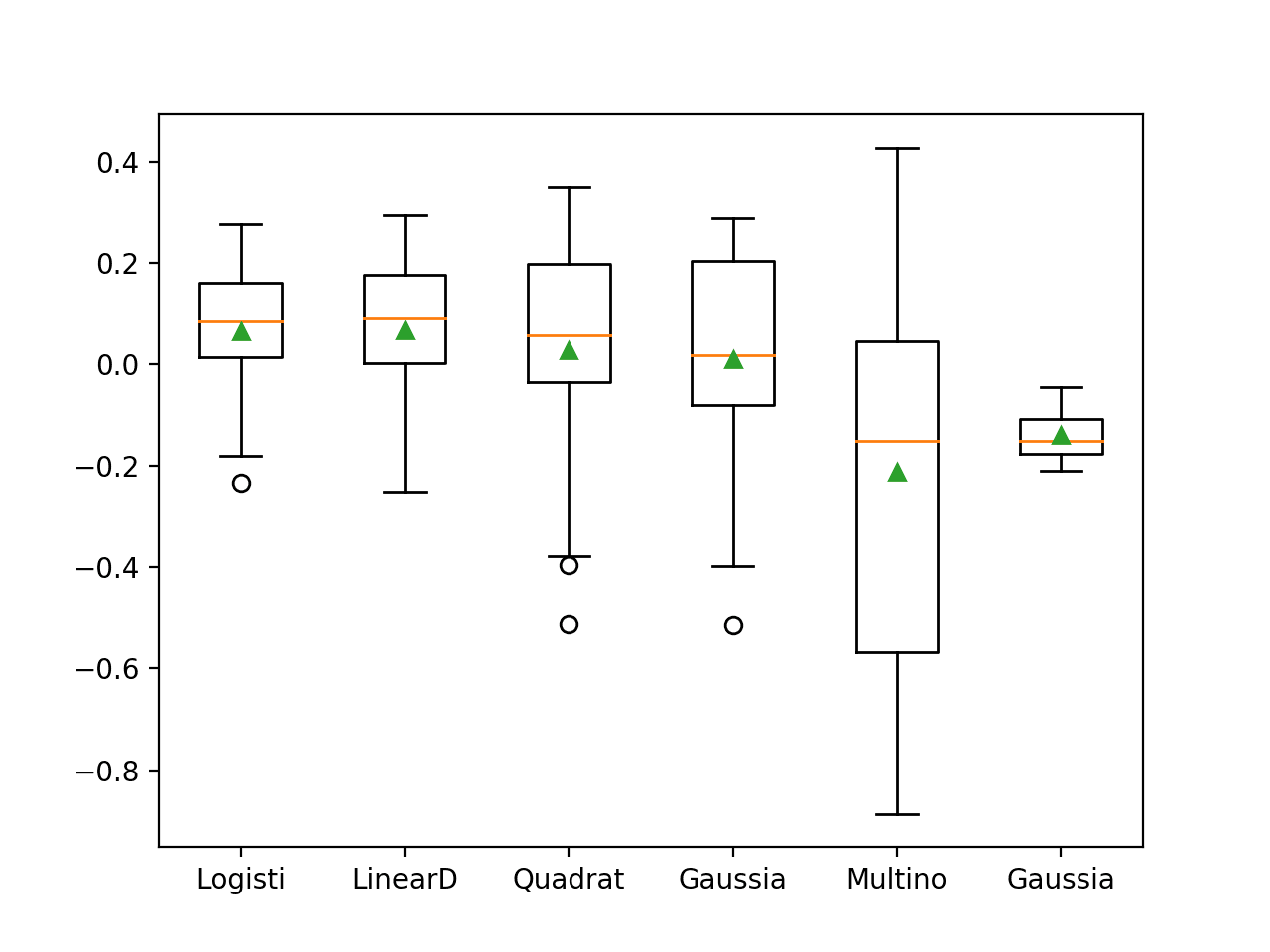
Box and Whisker Plot of Probabilistic Models on the Haberman Breast Cancer Survival Dataset
This is a good start; let’s see if we can improve the results with basic data preparation.
Model Evaluation With Scaled Inputs
It can be a good practice to scale data for some algorithms if the variables have different units of measure, as they do in this case.
Algorithms like the LR and LDA are sensitive to the of the data and assume a Gaussian distribution for the input variables, which we don’t have in all cases.
Nevertheless, we can test the algorithms with standardization, where each variable is shifted to a zero mean and unit standard deviation. We will drop the MultinomialNB algorithm as it does not support negative input values.
We can achieve this by wrapping each model in a Pipeline where the first step is a StandardScaler, which will correctly be fit on the training dataset and applied to the test dataset within each k-fold cross-validation evaluation, preventing any data leakage.
...
# create a pipeline
pip = Pipeline(steps=[('t', StandardScaler()),('m',model)])
# evaluate the model and store results
scores = evaluate_model(X, y, pip)
The complete example of evaluating the five remaining algorithms with standardized input data is listed below.
# compare probabilistic models with standardized input on the haberman dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from matplotlib import pyplot
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.metrics import brier_score_loss
from sklearn.metrics import make_scorer
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data = read_csv(full_path, header=None)
# retrieve numpy array
data = data.values
# split into input and output elements
X, y = data[:, :-1], data[:, -1]
# label encode the target variable to have the classes 0 and 1
y = LabelEncoder().fit_transform(y)
return X, y
# calculate brier skill score (BSS)
def brier_skill_score(y_true, y_prob):
# calculate reference brier score
ref_probs = [0.26471 for _ in range(len(y_true))]
bs_ref = brier_score_loss(y_true, ref_probs)
# calculate model brier score
bs_model = brier_score_loss(y_true, y_prob)
# calculate skill score
return 1.0 - (bs_model / bs_ref)
# evaluate a model
def evaluate_model(X, y, model):
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define the model evaluation the metric
metric = make_scorer(brier_skill_score, needs_proba=True)
# evaluate model
scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1)
return scores
# define the location of the dataset
full_path = 'haberman.csv'
# load the dataset
X, y = load_dataset(full_path)
# define models
models = [LogisticRegression(solver='lbfgs'), LinearDiscriminantAnalysis(),
QuadraticDiscriminantAnalysis(), GaussianNB(), GaussianProcessClassifier()]
names, values = list(), list()
# evaluate each model
for model in models:
# get a name for the model
name = type(model).__name__[:7]
# create a pipeline
pip = Pipeline(steps=[('t', StandardScaler()),('m',model)])
# evaluate the model and store results
scores = evaluate_model(X, y, pip)
# summarize and store
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
names.append(name)
values.append(scores)
# plot the results
pyplot.boxplot(values, labels=names, showmeans=True)
pyplot.show()
Running the example again summarizes the mean and standard deviation of the BSS for each algorithm.
Your specific results will vary given the stochastic nature of the learning algorithms; consider running the example a few times.
In this case, we can see that the standardization has not had much of an impact on the algorithms, except the Gaussian Process Classifier (GPC). The performance of the GPC with standardization has shot up and is now the best-performing technique. This highlights the importance of preparing data to meet the expectations of each model.
>Logisti 0.065 (0.121) >LinearD 0.067 (0.136) >Quadrat 0.027 (0.212) >Gaussia 0.011 (0.209) >Gaussia 0.092 (0.106)
Box and whisker plots for each algorithm’s results are created, showing the difference in mean performance (green triangles) and the similar spread in scores between the three top-performing methods.
This suggests all three probabilistic methods are discovering the same general mapping of inputs to probabilities in the dataset.
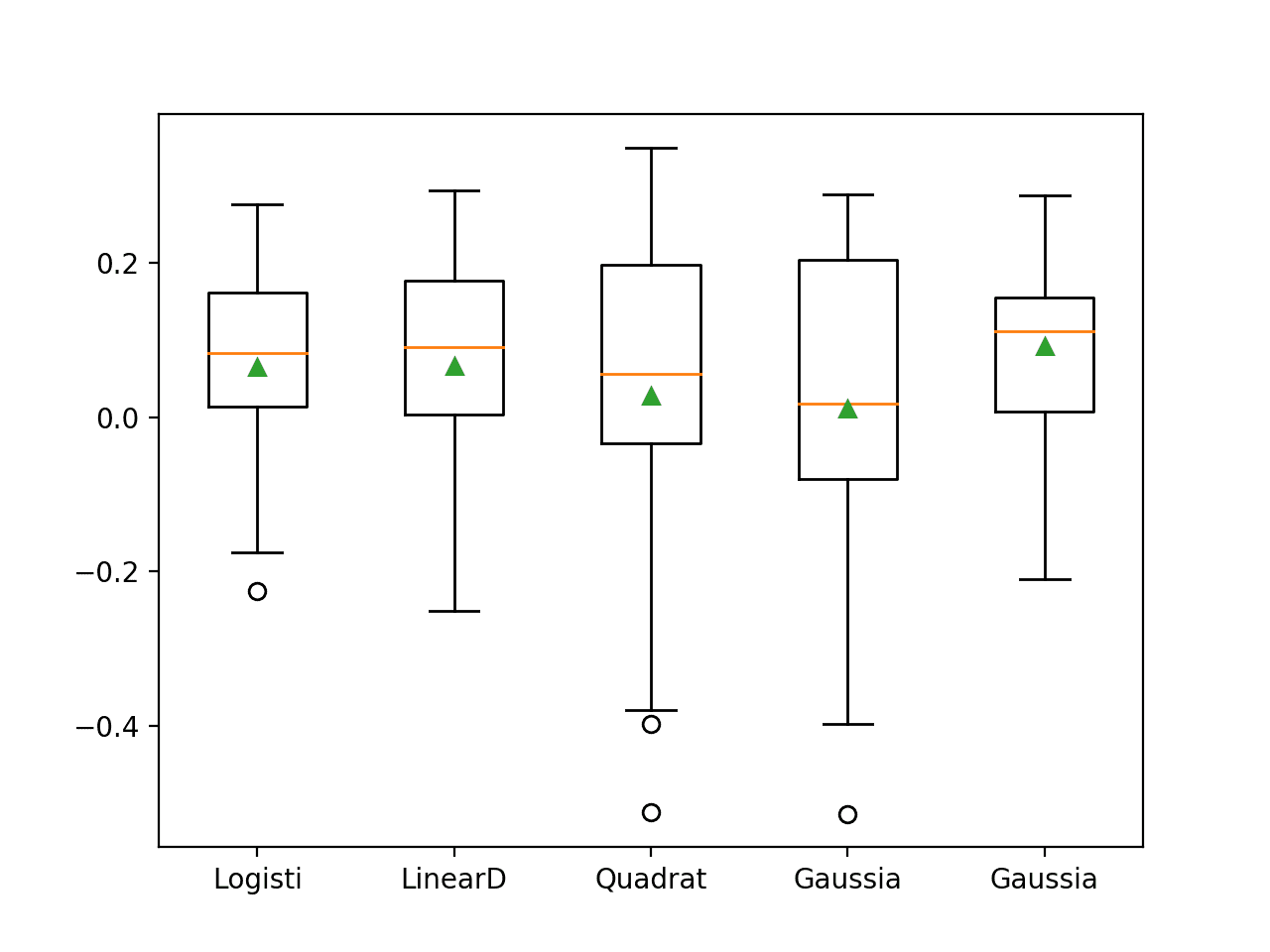
Box and Whisker Plot of Probabilistic Models With Data Standardization on the Haberman Breast Cancer Survival Dataset
There is further data preparation to make the input variables more Gaussian, such as power transforms.
Model Evaluation With Power Transform
Power transforms, such as the Box-Cox and Yeo-Johnson transforms, are designed to change the distribution to be more Gaussian.
This will help with the “age” input variable in our dataset and may help with the “nodes” variable and un-bunch the distribution slightly.
We can use the PowerTransformer scikit-learn class to perform the Yeo-Johnson and automatically determine the best parameters to apply based on the dataset, e.g. how to best make each variable more Gaussian. Importantly, this transformer will also standardize the dataset as part of the transform, ensuring we keep the gains seen in the previous section.
The power transform may make use of a log() function, which does not work on zero values. We have zero values in our dataset, therefore we will scale the dataset prior to the power transform using a MinMaxScaler.
Again, we can use this transform in a Pipeline to ensure it is fit on the training dataset and applied to the train and test datasets correctly, without data leakage.
...
# create a pipeline
pip = Pipeline(steps=[('t1', MinMaxScaler()), ('t2', PowerTransformer()),('m',model)])
# evaluate the model and store results
scores = evaluate_model(X, y, pip)
We will focus on the three top-performing methods, in this case, LR, LDA, and GPC.
The complete example is listed below.
# compare probabilistic models with power transforms on the haberman dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from matplotlib import pyplot
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.metrics import brier_score_loss
from sklearn.metrics import make_scorer
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PowerTransformer
from sklearn.preprocessing import MinMaxScaler
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data = read_csv(full_path, header=None)
# retrieve numpy array
data = data.values
# split into input and output elements
X, y = data[:, :-1], data[:, -1]
# label encode the target variable to have the classes 0 and 1
y = LabelEncoder().fit_transform(y)
return X, y
# calculate brier skill score (BSS)
def brier_skill_score(y_true, y_prob):
# calculate reference brier score
ref_probs = [0.26471 for _ in range(len(y_true))]
bs_ref = brier_score_loss(y_true, ref_probs)
# calculate model brier score
bs_model = brier_score_loss(y_true, y_prob)
# calculate skill score
return 1.0 - (bs_model / bs_ref)
# evaluate a model
def evaluate_model(X, y, model):
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define the model evaluation the metric
metric = make_scorer(brier_skill_score, needs_proba=True)
# evaluate model
scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1)
return scores
# define the location of the dataset
full_path = 'haberman.csv'
# load the dataset
X, y = load_dataset(full_path)
# define models
models = [LogisticRegression(solver='lbfgs'), LinearDiscriminantAnalysis(), GaussianProcessClassifier()]
names, values = list(), list()
# evaluate each model
for model in models:
# get a name for the model
name = type(model).__name__[:7]
# create a pipeline
pip = Pipeline(steps=[('t1', MinMaxScaler()), ('t2', PowerTransformer()),('m',model)])
# evaluate the model and store results
scores = evaluate_model(X, y, pip)
# summarize and store
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
names.append(name)
values.append(scores)
# plot the results
pyplot.boxplot(values, labels=names, showmeans=True)
pyplot.show()
Running the example again summarizes the mean and standard deviation of the BSS for each algorithm.
Your specific results will vary given the stochastic nature of the learning algorithms; consider running the example a few times.
In this case, we can see a further lift in model skill for the three models that were evaluated. We can see that the LR appears to have out-performed the other two methods.
>Logisti 0.111 (0.123) >LinearD 0.106 (0.147) >Gaussia 0.103 (0.096)
Box and whisker plots are created for the results from each algorithm, suggesting perhaps a smaller and more focused spread for LR compared to the LDA, which was the second-best performing method.
All methods still show skill on average, however the distribution of scores show runs that drop below 0.0 (no skill) in some cases.
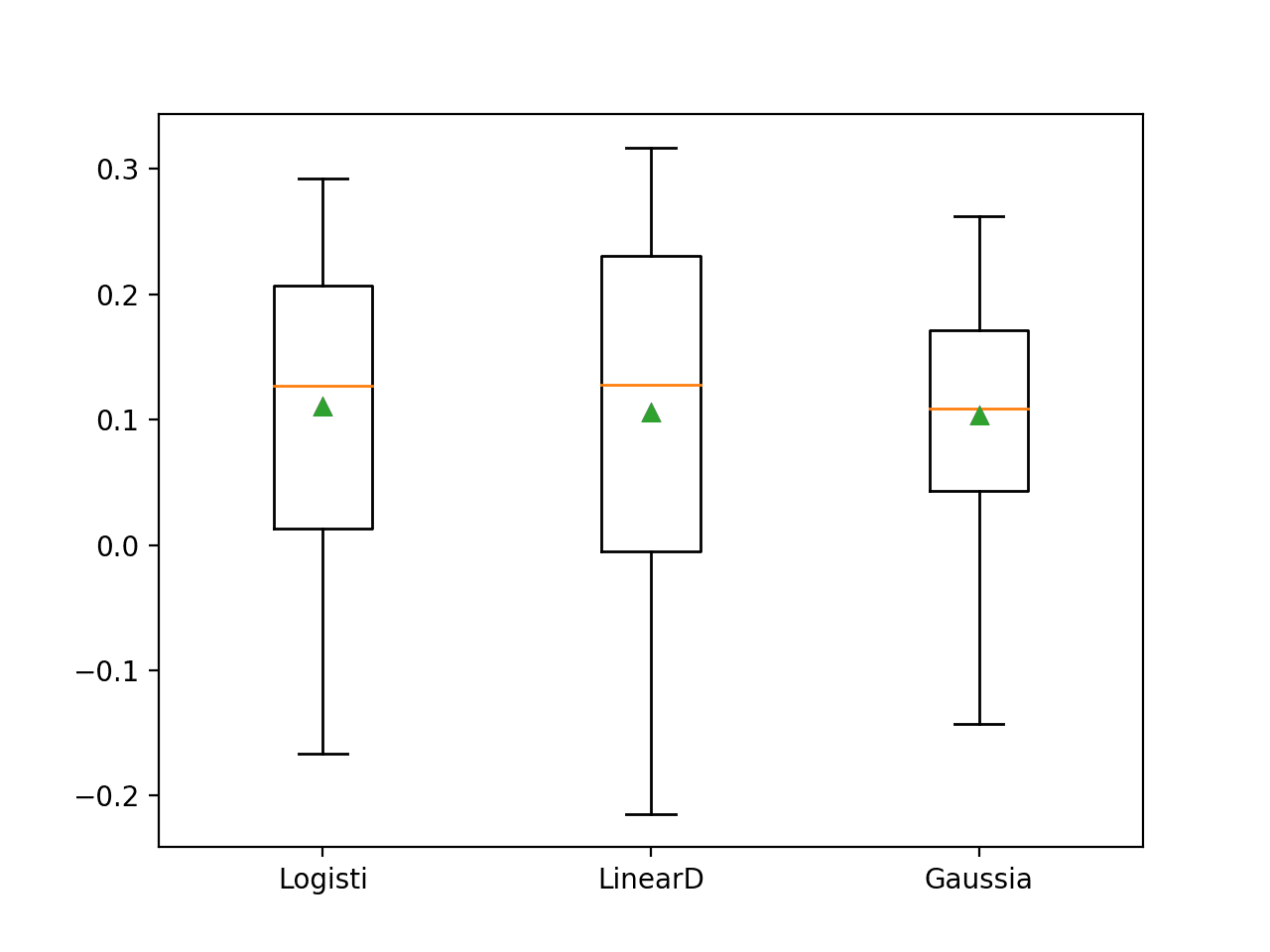
Box and Whisker Plot of Probabilistic Models With Power Transforms on the Haberman Breast Cancer Survival Dataset
Make Prediction on New Data
We will select the Logistic Regression model with a power transform on the input data as our final model.
We can define and fit this model on the entire training dataset.
...
# fit the model
model = Pipeline(steps=[('t1', MinMaxScaler()), ('t2', PowerTransformer()),('m',LogisticRegression(solver='lbfgs'))])
model.fit(X, y)
Once fit, we can use it to make predictions for new data by calling the predict_proba() function. This will return two probabilities for each prediction, the first for survival and the second for non-survival, e.g. its complement.
For example:
... row = [31,59,2] yhat = model.predict_proba([row]) # get percentage of survival p_survive = yhat[0, 0] * 100
To demonstrate this, we can use the fit model to make some predictions of probability for a few cases where we know there is survival and a few where we know there is not.
The complete example is listed below.
# fit a model and make predictions for the on the haberman dataset
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PowerTransformer
from sklearn.preprocessing import MinMaxScaler
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data = read_csv(full_path, header=None)
# retrieve numpy array
data = data.values
# split into input and output elements
X, y = data[:, :-1], data[:, -1]
# label encode the target variable to have the classes 0 and 1
y = LabelEncoder().fit_transform(y)
return X, y
# define the location of the dataset
full_path = 'haberman.csv'
# load the dataset
X, y = load_dataset(full_path)
# fit the model
model = Pipeline(steps=[('t1', MinMaxScaler()), ('t2', PowerTransformer()),('m',LogisticRegression(solver='lbfgs'))])
model.fit(X, y)
# some survival cases
print('Survival Cases:')
data = [[31,59,2], [31,65,4], [34,60,1]]
for row in data:
# make prediction
yhat = model.predict_proba([row])
# get percentage of survival
p_survive = yhat[0, 0] * 100
# summarize
print('>data=%s, Survival=%.3f%%' % (row, p_survive))
# some non-survival cases
print('Non-Survival Cases:')
data = [[44,64,6], [34,66,9], [38,69,21]]
for row in data:
# make prediction
yhat = model.predict_proba([row])
# get percentage of survival
p_survive = yhat[0, 0] * 100
# summarize
print('data=%s, Survival=%.3f%%' % (row, p_survive))
Running the example first fits the model on the entire training dataset.
Then the fit model is used to predict the probability of survival for cases where we know the patient survived, chosen from the dataset file. We can see that for the chosen survival cases, the probability of survival was high, between 77 percent and 86 percent.
Then some cases of non-survival are used as input to the model and the probability of survival is predicted. As we might have hoped, the probability of survival is modest, hovering around 53 percent to 63 percent.
Survival Cases: >data=[31, 59, 2], Survival=83.597% >data=[31, 65, 4], Survival=77.264% >data=[34, 60, 1], Survival=86.776% Non-Survival Cases: data=[44, 64, 6], Survival=63.092% data=[34, 66, 9], Survival=63.452% data=[38, 69, 21], Survival=53.389%
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
APIs
- pandas.read_csv API
- pandas.DataFrame.describe API
- pandas.DataFrame.hist API
- sklearn.model_selection.RepeatedStratifiedKFold API.
- sklearn.preprocessing.LabelEncoder API.
- sklearn.preprocessing.PowerTransformer API
Dataset
- Haberman’s Survival Data Set, UCI Machine Learning Repository.
- Haberman’s Survival Data Set CSV File
- Haberman’s Survival Data Set Names File
Summary
In this tutorial, you discovered how to develop a model to predict the probability of patient survival on an imbalanced dataset.
Specifically, you learned:
- How to load and explore the dataset and generate ideas for data preparation and model selection.
- How to evaluate a suite of probabilistic models and improve their performance with appropriate data preparation.
- How to fit a final model and use it to predict probabilities for specific cases.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Develop a Probabilistic Model of Breast Cancer Patient Survival appeared first on Machine Learning Mastery.