
Author: Jason Brownlee
Predictive modeling machine learning projects, such as classification and regression, always involve some form of data preparation.
The specific data preparation required for a dataset depends on the specifics of the data, such as the variable types, as well as the algorithms that will be used to model them that may impose expectations or requirements on the data.
Nevertheless, there is a collection of standard data preparation algorithms that can be applied to structured data (e.g. data that forms a large table like in a spreadsheet). These data preparation algorithms can be organized or grouped by type into a framework that can be helpful when comparing and selecting techniques for a specific project.
In this tutorial, you will discover the common data preparation tasks performed in a predictive modeling machine learning task.
After completing this tutorial, you will know:
- Techniques such as data cleaning can identify and fix errors in data like missing values.
- Data transforms can change the scale, type, and probability distribution of variables in the dataset.
- Techniques such as feature selection and dimensionality reduction can reduce the number of input variables.
Let’s get started.

Tour of Data Preparation Techniques for Machine Learning
Photo by Nicolas Raymond, some rights reserved.
Tutorial Overview
This tutorial is divided into six parts; they are:
- Common Data Preparation Tasks
- Data Cleaning
- Feature Selection
- Data Transforms
- Feature Engineering
- Dimensionality Reduction
Common Data Preparation Tasks
We can define data preparation as the transformation of raw data into a form that is more suitable for modeling.
Nevertheless, there are steps in a predictive modeling project before and after the data preparation step that are important and inform the data preparation that is to be performed.
The process of applied machine learning consists of a sequence of steps.
We may jump back and forth between the steps for any given project, but all projects have the same general steps; they are:
- Step 1: Define Problem.
- Step 2: Prepare Data.
- Step 3: Evaluate Models.
- Step 4: Finalize Model.
We are concerned with the data preparation step (step 2), and there are common or standard tasks that you may use or explore during the data preparation step in a machine learning project.
The types of data preparation performed depend on your data, as you might expect.
Nevertheless, as you work through multiple predictive modeling projects, you see and require the same types of data preparation tasks again and again.
These tasks include:
- Data Cleaning: Identifying and correcting mistakes or errors in the data.
- Feature Selection: Identifying those input variables that are most relevant to the task.
- Data Transforms: Changing the scale or distribution of variables.
- Feature Engineering: Deriving new variables from available data.
- Dimensionality Reduction: Creating compact projections of the data.
This provides a rough framework that we can use to think about and navigate different data preparation algorithms we may consider on a given project with structured or tabular data.
Let’s take a closer look at each in turn.
Data Cleaning
Data cleaning involves fixing systematic problems or errors in “messy” data.
The most useful data cleaning involves deep domain expertise and could involve identifying and addressing specific observations that may be incorrect.
There are many reasons data may have incorrect values, such as being mistyped, corrupted, duplicated, and so on. Domain expertise may allow obviously erroneous observations to be identified as they are different from what is expected, such as a person’s height of 200 feet.
Once messy, noisy, corrupt, or erroneous observations are identified, they can be addressed. This might involve removing a row or a column. Alternately, it might involve replacing observations with new values.
Nevertheless, there are general data cleaning operations that can be performed, such as:
- Using statistics to define normal data and identify outliers.
- Identifying columns that have the same value or no variance and removing them.
- Identifying duplicate rows of data and removing them.
- Marking empty values as missing.
- Imputing missing values using statistics or a learned model.
Data cleaning is an operation that is typically performed first, prior to other data preparation operations.
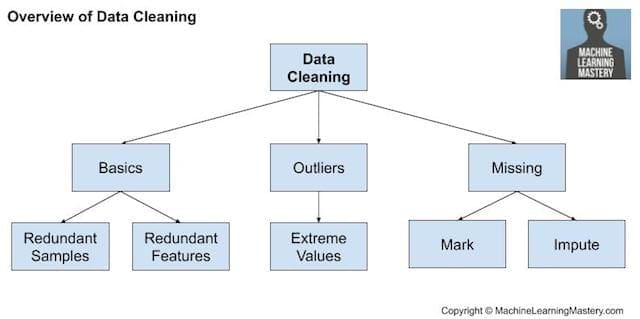
Overview of Data Cleaning
For more on data cleaning see the tutorial:
Feature Selection
Feature selection refers to techniques for selecting a subset of input features that are most relevant to the target variable that is being predicted.
This is important as irrelevant and redundant input variables can distract or mislead learning algorithms possibly resulting in lower predictive performance. Additionally, it is desirable to develop models only using the data that is required to make a prediction, e.g. to favor the simplest possible well performing model.
Feature selection techniques are generally grouped into those that use the target variable (supervised) and those that do not (unsupervised). Additionally, the supervised techniques can be further divided into models that automatically select features as part of fitting the model (intrinsic), those that explicitly choose features that result in the best performing model (wrapper) and those that score each input feature and allow a subset to be selected (filter).
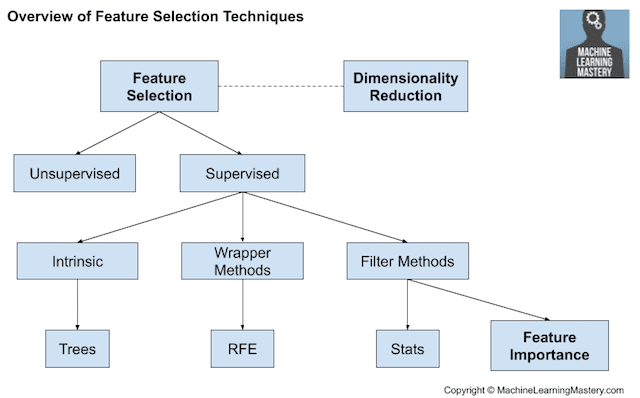
Overview of Feature Selection Techniques
Statistical methods are popular for scoring input features, such as correlation. The features can then be ranked by their scores and a subset with the largest scores used as input to a model. The choice of statistical measure depends on the data types of the input variables and a review of different statistical measures that can be used.
For an overview of how to select statistical feature selection methods based on data type, see the tutorial:
Additionally, there are different common feature selection use cases we may encounter in a predictive modeling project, such as:
- Categorical inputs for a classification target variable.
- Numerical inputs for a classification target variable.
- Numerical inputs for a regression target variable.
When a mixture of input variable data types a present, different filter methods can be used. Alternately, a wrapper method such as the popular RFE method can be used that is agnostic to the input variable type.
The broader field of scoring the relative importance of input features is referred to as feature importance and many model-based techniques exist whose outputs can be used to aide in interpreting the model, interpreting the dataset, or in selecting features for modeling.
For more on feature importance, see the tutorial:
Data Transforms
Data transforms are used to change the type or distribution of data variables.
This is a large umbrella of different techniques and they may be just as easily applied to input and output variables.
Recall that data may have one of a few types, such as numeric or categorical, with subtypes for each, such as integer and real-valued for numeric, and nominal, ordinal, and boolean for categorical.
- Numeric Data Type: Number values.
- Integer: Integers with no fractional part.
- Real: Floating point values.
- Categorical Data Type: Label values.
- Ordinal: Labels with a rank ordering.
- Nominal: Labels with no rank ordering.
- Boolean: Values True and False.
The figure below provides an overview of this same breakdown of high-level data types.
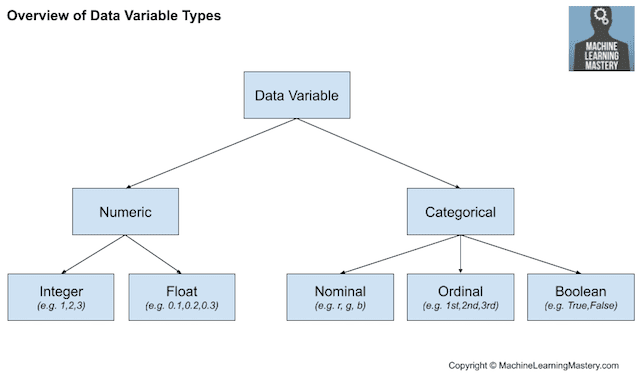
Overview of Data Variable Types
We may wish to convert a numeric variable to an ordinal variable in a process called discretization. Alternatively, we may encode a categorical variable as integers or boolean variables, required on most classification tasks.
- Discretization Transform: Encode a numeric variable as an ordinal variable.
- Ordinal Transform: Encode a categorical variable into an integer variable.
- One-Hot Transform: Encode a categorical variable into binary variables.
For real-valued numeric variables, the way they are represented in a computer means there is dramatically more resolution in the range 0-1 than in the broader range of the data type. As such, it may be desirable to scale variables to this range, called normalization. If the data has a Gaussian probability distribution, it may be more useful to shift the data to a standard Gaussian with a mean of zero and a standard deviation of one.
- Normalization Transform: Scale a variable to the range 0 and 1.
- Standardization Transform: Scale a variable to a standard Gaussian.
The probability distribution for numerical variables can be changed.
For example, if the distribution is nearly Gaussian, but is skewed or shifted, it can be made more Gaussian using a power transform. Alternatively, quantile transforms can be used to force a probability distribution, such as a uniform or Gaussian on a variable with an unusual natural distribution.
- Power Transform: Change the distribution of a variable to be more Gaussian.
- Quantile Transform: Impose a probability distribution such as uniform or Gaussian.
An important consideration with data transforms is that the operations are generally performed separately for each variable. As such, we may want to perform different operations on different variable types.
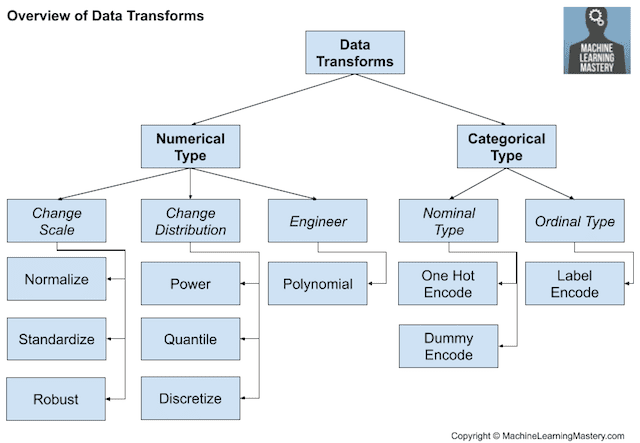
Overview of Data Transform Techniques
We may also want to use the transform on new data in the future. This can be achieved by saving the transform objects to file along with the final model trained on all available data.
Feature Engineering
Feature engineering refers to the process of creating new input variables from the available data.
Engineering new features is highly specific to your data and data types. As such, it often requires the collaboration of a subject matter expert to help identify new features that could be constructed from the data.
This specialization makes it a challenging topic to generalize to general methods.
Nevertheless, there are some techniques that can be reused, such as:
- Adding a boolean flag variable for some state.
- Adding a group or global summary statistic, such as a mean.
- Adding new variables for each component of a compound variable, such as a date-time.
A popular approach drawn from statistics is to create copies of numerical input variables that have been changed with a simple mathematical operation, such as raising them to a power or multiplied with other input variables, referred to as polynomial features.
- Polynomial Transform: Create copies of numerical input variables that are raised to a power.
The theme of feature engineering is to add broader context to a single observation or decompose a complex variable, both in an effort to provide a more straightforward perspective on the input data.
I like to think of feature engineering as a type of data transform, although it would be just as reasonable to think of data transforms as a type of feature engineering.
Dimensionality Reduction
The number of input features for a dataset may be considered the dimensionality of the data.
For example, two input variables together can define a two-dimensional area where each row of data defines a point in that space. This idea can then be scaled to any number of input variables to create large multi-dimensional hyper-volumes.
The problem is, the more dimensions this space has (e.g. the more input variables), the more likely it is that the dataset represents a very sparse and likely unrepresentative sampling of that space. This is referred to as the curse of dimensionality.
This motivates feature selection, although an alternative to feature selection is to create a projection of the data into a lower-dimensional space that still preserves the most important properties of the original data.
This is referred to generally as dimensionality reduction and provides an alternative to feature selection. Unlike feature selection, the variables in the projected data are not directly related to the original input variables, making the projection difficult to interpret.
The most common approach to dimensionality reduction is to use a matrix factorization technique:
- Principal Component Analysis (PCA)
- Singular Value Decomposition (SVD)
The main impact of these techniques is that they remove linear dependencies between input variables, e.g. correlated variables.
Other approaches exist that discover a lower dimensionality reduction. We might refer to these as based methods such as LDA and perhaps autoencoders.
- Linear Discriminant Analysis (LDA)
Sometimes manifold learning algorithms can also be used, such as Kohonen self-organizing maps and t-SNE.
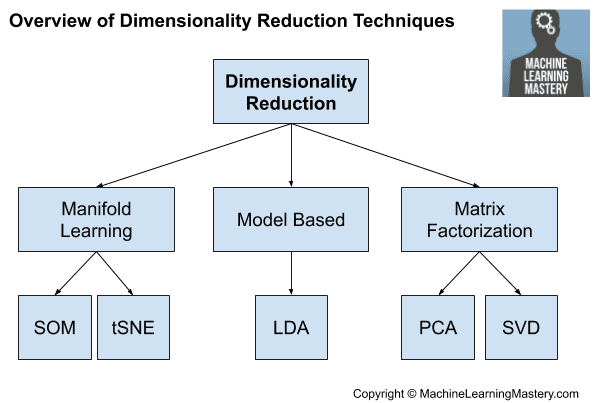
Overview of Dimensionality Reduction Techniques
For on dimensionality reduction, see the tutorial:
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- How to Prepare Data For Machine Learning
- Applied Machine Learning Process
- How to Perform Data Cleaning for Machine Learning with Python
- How to Choose a Feature Selection Method For Machine Learning
- Introduction to Dimensionality Reduction for Machine Learning
Books
- Feature Engineering and Selection: A Practical Approach for Predictive Models, 2019.
- Applied Predictive Modeling, 2013.
- Data Mining: Practical Machine Learning Tools and Techniques, 4th edition, 2016.
Articles
Summary
In this tutorial, you discovered the common data preparation tasks performed in a predictive modeling machine learning task.
Specifically, you learned:
- Techniques, such data cleaning, can identify and fix errors in data like missing values.
- Data transforms can change the scale, type, and probability distribution of variables in the dataset.
- Techniques such as feature selection and dimensionality reduction can reduce the number of input variables.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Tour of Data Preparation Techniques for Machine Learning appeared first on Machine Learning Mastery.