
Author: Jason Brownlee
Many computationally expensive tasks for machine learning can be made parallel by splitting the work across multiple CPU cores, referred to as multi-core processing.
Common machine learning tasks that can be made parallel include training models like ensembles of decision trees, evaluating models using resampling procedures like k-fold cross-validation, and tuning model hyperparameters, such as grid and random search.
Using multiple cores for common machine learning tasks can dramatically decrease the execution time as a factor of the number of cores available on your system. A common laptop and desktop computer may have 2, 4, or 8 cores. Larger server systems may have 32, 64, or more cores available, allowing machine learning tasks that take hours to be completed in minutes.
In this tutorial, you will discover how to configure scikit-learn for multi-core machine learning.
After completing this tutorial, you will know:
- How to train machine learning models using multiple cores.
- How to make the evaluation of machine learning models parallel.
- How to use multiple cores to tune machine learning model hyperparameters.
Let’s get started.

Multi-Core Machine Learning in Python With Scikit-Learn
Photo by ER Bauer, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Multi-Core Scikit-Learn
- Multi-Core Model Training
- Multi-Core Model Evaluation
- Multi-Core Hyperparameter Tuning
- Recommendations
Multi-Core Scikit-Learn
Machine learning can be computationally expensive.
There are three main centers of this computational cost; they are:
- Training machine learning models.
- Evaluating machine learning models.
- Hyperparameter tuning machine learning models.
Worse, these concerns compound.
For example, evaluating machine learning models using a resampling technique like k-fold cross-validation requires that the training process is repeated multiple times.
- Evaluation Requires Repeated Training
Tuning model hyperparameters compounds this further as it requires the evaluation procedure repeated for each combination of hyperparameters tested.
- Tuning Requires Repeated Evaluation
Most, if not all, modern computers have multi-core CPUs. This includes your workstation, your laptop, as well as larger servers.
You can configure your machine learning models to harness multiple cores of your computer, dramatically speeding up computationally expensive operations.
The scikit-learn Python machine learning library provides this capability via the n_jobs argument on key machine learning tasks, such as model training, model evaluation, and hyperparameter tuning.
This configuration argument allows you to specify the number of cores to use for the task. The default is None, which will use a single core. You can also specify a number of cores as an integer, such as 1 or 2. Finally, you can specify -1, in which case the task will use all of the cores available on your system.
- n_jobs: Specify the number of cores to use for key machine learning tasks.
Common values are:
- n_jobs=None: Use a single core or the default configured by your backend library.
- n_jobs=4: Use the specified number of cores, in this case 4.
- n_jobs=-1: Use all available cores.
What is a core?
A CPU may have multiple physical CPU cores, which is essentially like having multiple CPUs. Each core may also have hyper-threading, a technology that under many circumstances allows you to double the number of cores.
For example, my workstation has four physical cores, which are doubled to eight cores due to hyper-threading. Therefore, I can experiment with 1-8 cores or specify -1 to use all cores on my workstation.
Now that we are familiar with the scikit-learn library’s capability to support multi-core parallel processing for machine learning, let’s work through some examples.
You will get different timings for all of the examples in this tutorial; share your results in the comments. You may also need to change the number of cores to match the number of cores on your system.
Note: Yes, I am aware of the timeit API, but chose against it for this tutorial. We are not profiling the code examples per se; instead, I want you to focus on how and when to use the multi-core capabilities of scikit-learn and that they offer real benefits. I wanted the code examples to be clean and simple to read, even for beginners. I set it as an extension to update all examples to use the timeit API and get more accurate timings. Share your results in the comments.
Multi-Core Model Training
Many machine learning algorithms support multi-core training via an n_jobs argument when the model is defined.
This affects not just the training of the model, but also the use of the model when making predictions.
A popular example is the ensemble of decision trees, such as bagged decision trees, random forest, and gradient boosting.
In this section we will explore accelerating the training of a RandomForestClassifier model using multiple cores. We will use a synthetic classification task for our experiments.
In this case, we will define a random forest model with 500 trees and use a single core to train the model.
... # define the model model = RandomForestClassifier(n_estimators=500, n_jobs=1)
We can record the time before and after the call to the train() function using the time() function. We can then subtract the start time from the end time and report the execution time in the number of seconds.
The complete example of evaluating the execution time of training a random forest model with a single core is listed below.
# example of timing the training of a random forest model on one core
from time import time
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=500, n_jobs=1)
# record current time
start = time()
# fit the model
model.fit(X, y)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example reports the time taken to train the model with a single core.
In this case, we can see that it takes about 10 seconds.
How long does it take on your system? Share your results in the comments below.
10.702 seconds
We can now change the example to use all of the physical cores on the system, in this case, four.
... # define the model model = RandomForestClassifier(n_estimators=500, n_jobs=4)
The complete example of multi-core training of the model with four cores is listed below.
# example of timing the training of a random forest model on 4 cores
from time import time
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=500, n_jobs=4)
# record current time
start = time()
# fit the model
model.fit(X, y)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example reports the time taken to train the model with a single core.
In this case, we can see that the speed of execution more than halved to about 3.151 seconds.
How long does it take on your system? Share your results in the comments below.
3.151 seconds
We can now change the number of cores to eight to account for the hyper-threading supported by the four physical cores.
... # define the model model = RandomForestClassifier(n_estimators=500, n_jobs=8)
We can achieve the same effect by setting n_jobs to -1 to automatically use all cores; for example:
... # define the model model = RandomForestClassifier(n_estimators=500, n_jobs=-1)
We will stick to manually specifying the number of cores for now.
The complete example of multi-core training of the model with eight cores is listed below.
# example of timing the training of a random forest model on 8 cores
from time import time
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=500, n_jobs=8)
# record current time
start = time()
# fit the model
model.fit(X, y)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example reports the time taken to train the model with a single core.
In this case, we can see that we got another drop in execution speed from about 3.151 to about 2.521 by using all cores.
How long does it take on your system? Share your results in the comments below.
2.521 seconds
We can make the relationship between the number of cores used during training and execution speed more concrete by comparing all values between one and eight and plotting the result.
The complete example is listed below.
# example of comparing number of cores used during training to execution speed
from time import time
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
results = list()
# compare timing for number of cores
n_cores = [1, 2, 3, 4, 5, 6, 7, 8]
for n in n_cores:
# capture current time
start = time()
# define the model
model = RandomForestClassifier(n_estimators=500, n_jobs=n)
# fit the model
model.fit(X, y)
# capture current time
end = time()
# store execution time
result = end - start
print('>cores=%d: %.3f seconds' % (n, result))
results.append(result)
pyplot.plot(n_cores, results)
pyplot.show()
Running the example first reports the execution speed for each number of cores used during training.
We can see a steady decrease in execution speed from one to eight cores, although the dramatic benefits stop after four physical cores.
How long does it take on your system? Share your results in the comments below.
>cores=1: 10.798 seconds >cores=2: 5.743 seconds >cores=3: 3.964 seconds >cores=4: 3.158 seconds >cores=5: 2.868 seconds >cores=6: 2.631 seconds >cores=7: 2.528 seconds >cores=8: 2.440 seconds
A plot is also created to show the relationship between the number of cores used during training and the execution speed, showing that we continue to see a benefit all the way to eight cores.
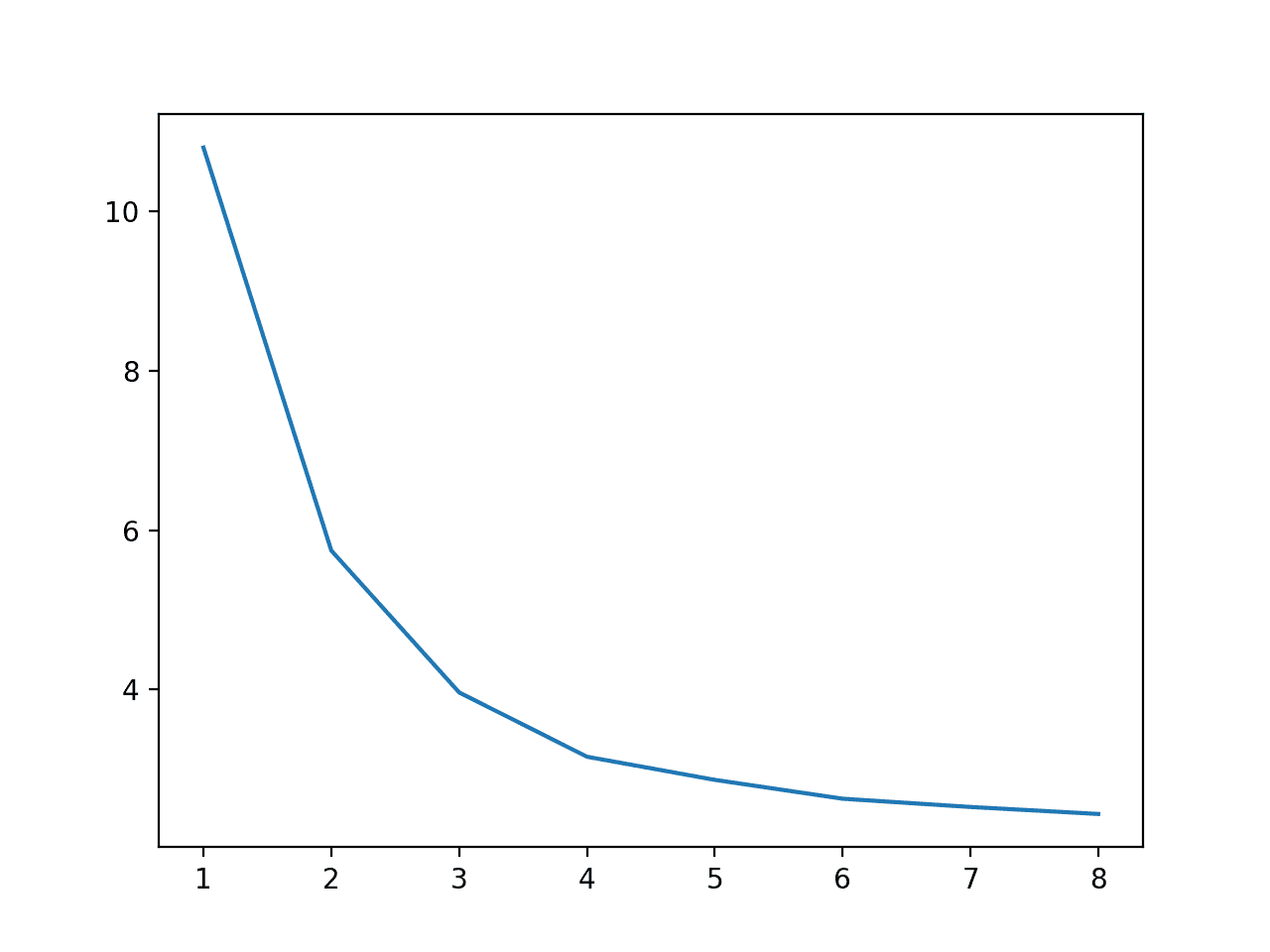
Line Plot of Number of Cores Used During Training vs. Execution Speed
Now that we are familiar with the benefit of multi-core training of machine learning models, let’s look at multi-core model evaluation.
Multi-Core Model Evaluation
The gold standard for model evaluation is k-fold cross-validation.
This is a resampling procedure that requires that the model is trained and evaluated k times on different partitioned subsets of the dataset. The result is an estimate of the performance of a model when making predictions on data not used during training that can be used to compare and select a good or best model for a dataset.
In addition, it is also a good practice to repeat this evaluation process multiple times, referred to as repeated k-fold cross-validation.
The evaluation procedure can be configured to use multiple cores, where each model training and evaluation happens on a separate core. This can be done by setting the n_jobs argument on the call to cross_val_score() function; for example:
We can explore the effect of multiple cores on model evaluation.
First, let’s evaluate the model using a single core.
... # evaluate the model n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1)
We will evaluate the random forest model and use a single core in the training of the model (for now).
... # define the model model = RandomForestClassifier(n_estimators=100, n_jobs=1)
The complete example is listed below.
# example of evaluating a model using a single core
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=1)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# record current time
start = time()
# evaluate the model
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example evaluates the model using 10-fold cross-validation with three repeats.
In this case, we see that the evaluation of the model took about 6.412 seconds.
How long does it take on your system? Share your results in the comments below.
6.412 seconds
We can update the example to use all eight cores of the system and expect a large speedup.
... # evaluate the model n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=8)
The complete example is listed below.
# example of evaluating a model using 8 cores
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=1)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# record current time
start = time()
# evaluate the model
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=8)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example evaluates the model using multiple cores.
In this case, we can see the execution timing dropped from 6.412 seconds to about 2.371 seconds, giving a welcome speedup.
How long does it take on your system? Share your results in the comments below.
2.371 seconds
As we did in the previous section, we can time the execution speed for each number of cores from one to eight to get an idea of the relationship.
The complete example is listed below.
# compare execution speed for model evaluation vs number of cpu cores
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
results = list()
# compare timing for number of cores
n_cores = [1, 2, 3, 4, 5, 6, 7, 8]
for n in n_cores:
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=1)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# record the current time
start = time()
# evaluate the model
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=n)
# record the current time
end = time()
# store execution time
result = end - start
print('>cores=%d: %.3f seconds' % (n, result))
results.append(result)
pyplot.plot(n_cores, results)
pyplot.show()
Running the example first reports the execution time in seconds for each number of cores for evaluating the model.
We can see that there is not a dramatic improvement above four physical cores.
We can also see a difference here when training with eight cores from the previous experiment. In this case, evaluating performance took 1.492 seconds whereas the standalone case took about 2.371 seconds.
This highlights the limitation of the evaluation methodology we are using where we are reporting the performance of a single run rather than repeated runs. There is some spin-up time required to load classes into memory and perform any JIT optimization.
Regardless of the accuracy of our flimsy profiling, we do see the familiar speedup of model evaluation with the increase of cores used during the process.
How long does it take on your system? Share your results in the comments below.
>cores=1: 6.339 seconds >cores=2: 3.765 seconds >cores=3: 2.404 seconds >cores=4: 1.826 seconds >cores=5: 1.806 seconds >cores=6: 1.686 seconds >cores=7: 1.587 seconds >cores=8: 1.492 seconds
A plot of the relationship between the number of cores and the execution speed is also created.
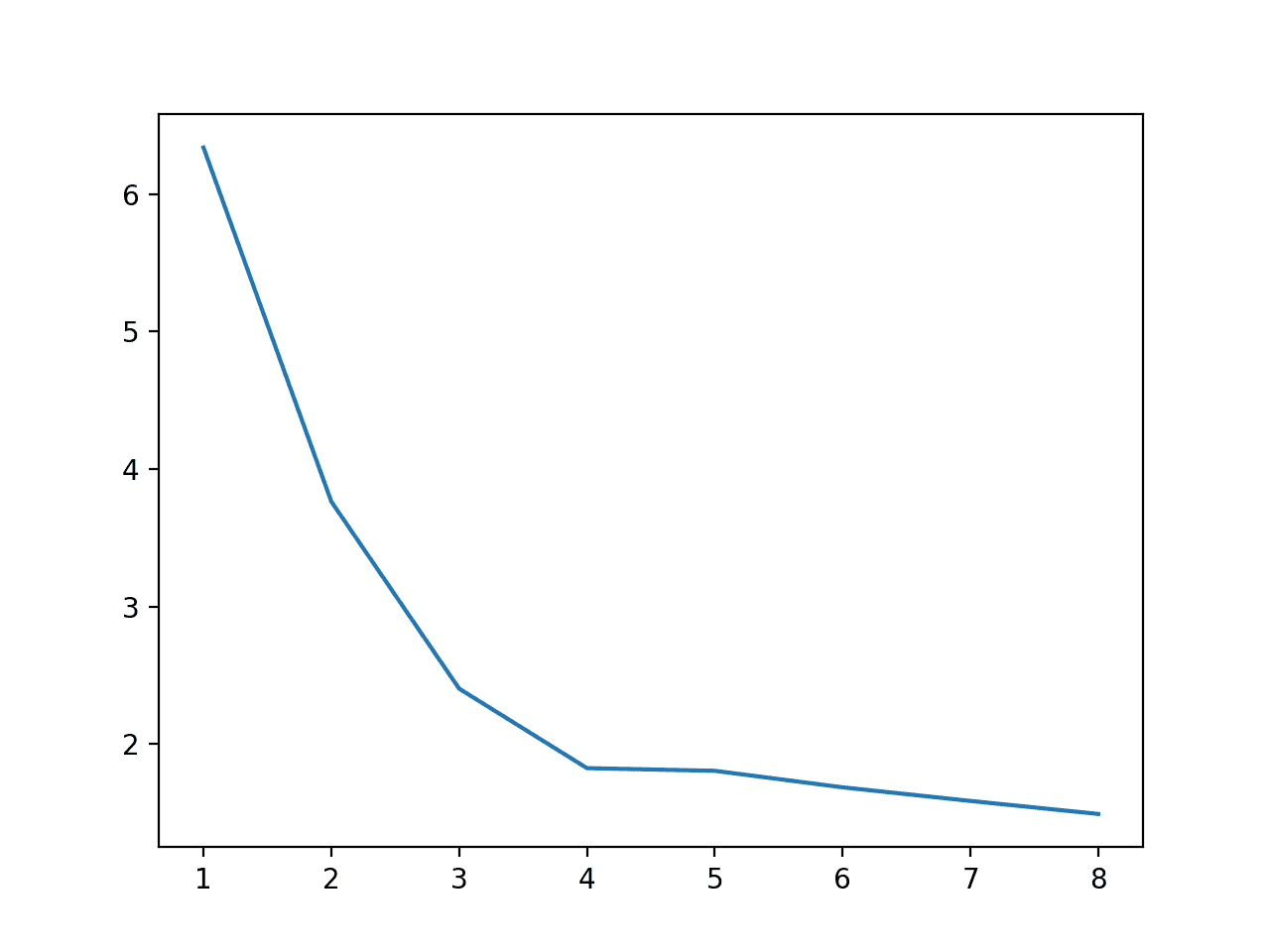
Line Plot of Number of Cores Used During Evaluation vs. Execution Speed
We can also make the model training process parallel during the model evaluation procedure.
Although this is possible, should we?
To explore this question, let’s first consider the case where model training uses all cores and model evaluation uses a single core.
... # define the model model = RandomForestClassifier(n_estimators=100, n_jobs=8) ... # evaluate the model n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1)
The complete example is listed below.
# example of using multiple cores for model training but not model evaluation
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=8)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# record current time
start = time()
# evaluate the model
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example evaluates the model using a single core, but each trained model uses a single core.
In this case, we can see that the model evaluation takes more than 10 seconds, much longer than the 1 or 2 seconds when we use a single core for training and all cores for parallel model evaluation.
How long does it take on your system? Share your results in the comments below.
10.461 seconds
What if we split the number of cores between the training and evaluation procedures?
... # define the model model = RandomForestClassifier(n_estimators=100, n_jobs=4) ... # evaluate the model n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=4)
The complete example is listed below.
# example of using multiple cores for model training and evaluation
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=8)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=4)
# record current time
start = time()
# evaluate the model
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=4)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example evaluates the model using four cores, and each model is trained using four different cores.
We can see an improvement over training with all cores and evaluating with one core, but at least for this model on this dataset, it is more efficient to use all cores for model evaluation and a single core for model training.
How long does it take on your system? Share your results in the comments below.
3.434 seconds
Multi-Core Hyperparameter Tuning
It is common to tune the hyperparameters of a machine learning model using a grid search or a random search.
The scikit-learn library provides these capabilities via the GridSearchCV and RandomizedSearchCV classes respectively.
Both of these search procedures can be made parallel by setting the n_jobs argument, assigning each hyperparameter configuration to a core for evaluation.
The model evaluation itself could also be multi-core, as we saw in the previous section, and the model training for a given evaluation can also be training as we saw in the second before that. Therefore, the stack of potentially multi-core processes is starting to get challenging to configure.
In this specific implementation, we can make the model training parallel, but we don’t have control over how each model hyperparameter and how each model evaluation is made multi-core. The documentation is not clear at the time of writing, but I would guess that each model evaluation using a single core hyperparameter configuration is split into jobs.
Let’s explore the benefits of performing model hyperparameter tuning using multiple cores.
First, let’s evaluate a grid of different configurations of the random forest algorithm using a single core.
... # define grid search search = GridSearchCV(model, grid, n_jobs=1, cv=cv)
The complete example is listed below.
# example of tuning model hyperparameters with a single core
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=1)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define grid
grid = dict()
grid['max_features'] = [1, 2, 3, 4, 5]
# define grid search
search = GridSearchCV(model, grid, n_jobs=1, cv=cv)
# record current time
start = time()
# perform search
search.fit(X, y)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example tests different values of the max_features configuration for random forest, where each configuration is evaluated using repeated k-fold cross-validation.
In this case, the grid search on a single core takes about 28.838 seconds.
How long does it take on your system? Share your results in the comments below.
28.838 seconds
We can now configure the grid search to use all available cores on the system, in this case, eight cores.
... # define grid search search = GridSearchCV(model, grid, n_jobs=8, cv=cv)
We can then evaluate how long this multi-core grids search takes to execute. The complete example is listed below.
# example of tuning model hyperparameters with 8 cores
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=1)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define grid
grid = dict()
grid['max_features'] = [1, 2, 3, 4, 5]
# define grid search
search = GridSearchCV(model, grid, n_jobs=8, cv=cv)
# record current time
start = time()
# perform search
search.fit(X, y)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
Running the example reports execution time for the grid search.
In this case, we see a factor of about four speed up from roughly 28.838 seconds to around 7.418 seconds.
How long does it take on your system? Share your results in the comments below.
7.418 seconds
Intuitively, we would expect that making the grid search multi-core should be the focus and not model training.
Nevertheless, we can divide the number of cores between model training and the grid search to see if it offers a benefit for this model on this dataset.
... # define the model model = RandomForestClassifier(n_estimators=100, n_jobs=4) ... # define grid search search = GridSearchCV(model, grid, n_jobs=4, cv=cv)
The complete example of multi-core model training and multi-core hyperparameter tuning is listed below.
# example of multi-core model training and hyperparameter tuning
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3)
# define the model
model = RandomForestClassifier(n_estimators=100, n_jobs=4)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define grid
grid = dict()
grid['max_features'] = [1, 2, 3, 4, 5]
# define grid search
search = GridSearchCV(model, grid, n_jobs=4, cv=cv)
# record current time
start = time()
# perform search
search.fit(X, y)
# record current time
end = time()
# report execution time
result = end - start
print('%.3f seconds' % result)
In this case, we do see a decrease in execution speed compared to a single core case, but not as much benefit as assigning all cores to the grid search process.
How long does it take on your system? Share your results in the comments below.
14.148 seconds
Recommendations
This section lists some general recommendations when using multiple cores for machine learning.
- Confirm the number of cores available on your system.
- Consider using an AWS EC2 instance with many cores to get an immediate speed up.
- Check the API documentation to see if the model/s you are using support multi-core training.
- Confirm multi-core training offers a measurable benefit on your system.
- When using k-fold cross-validation, it is probably better to assign cores to the resampling procedure and leave model training single core.
- When using hyperparamter tuning, it is probably better to make the search multi-core and leave the model training and evaluation single core.
Do you have any recommendations of your own?
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Related Tutorials
APIs
- How to optimize for speed, scikit-learn Documentation.
- Joblib: running Python functions as pipeline jobs
- timeit API.
- sklearn.ensemble.RandomForestClassifier API.
- sklearn.model_selection.cross_val_score API.
- sklearn.model_selection.GridSearchCV API.
- sklearn.model_selection.RandomizedSearchCV API.
- n_jobs scikit-learn argument.
Articles
Summary
In this tutorial, you discovered how to configure scikit-learn for multi-core machine learning.
Specifically, you learned:
- How to train machine learning models using multiple cores.
- How to make the evaluation of machine learning models parallel.
- How to use multiple cores to tune machine learning model hyperparameters.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Multi-Core Machine Learning in Python With Scikit-Learn appeared first on Machine Learning Mastery.