
Author: Jason Brownlee
Some prediction problems require predicting both numeric values and a class label for the same input.
A simple approach is to develop both regression and classification predictive models on the same data and use the models sequentially.
An alternative and often more effective approach is to develop a single neural network model that can predict both a numeric and class label value from the same input. This is called a multi-output model and can be relatively easy to develop and evaluate using modern deep learning libraries such as Keras and TensorFlow.
In this tutorial, you will discover how to develop a neural network for combined regression and classification predictions.
After completing this tutorial, you will know:
- Some prediction problems require predicting both numeric and class label values for each input example.
- How to develop separate regression and classification models for problems that require multiple outputs.
- How to develop and evaluate a neural network model capable of making simultaneous regression and classification predictions.
Let’s get started.

Develop Neural Network for Combined Classification and Regression
Photo by Sang Trinh, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Single Model for Regression and Classification
- Separate Regression and Classification Models
- Abalone Dataset
- Regression Model
- Classification Model
- Combined Regression and Classification Models
Single Model for Regression and Classification
It is common to develop a deep learning neural network model for a regression or classification problem, but on some predictive modeling tasks, we may want to develop a single model that can make both regression and classification predictions.
Regression refers to predictive modeling problems that involve predicting a numeric value given an input.
Classification refers to predictive modeling problems that involve predicting a class label or probability of class labels for a given input.
For more on the difference between classification and regression, see the tutorial:
There may be some problems where we want to predict both a numerical value and a classification value.
One approach to solving this problem is to develop a separate model for each prediction that is required.
The problem with this approach is that the predictions made by the separate models may diverge.
An alternate approach that can be used when using neural network models is to develop a single model capable of making separate predictions for a numeric and class output for the same input.
This is called a multi-output neural network model.
The benefit of this type of model is that we have a single model to develop and maintain instead of two models and that training and updating the model on both output types at the same time may offer more consistency in the predictions between the two output types.
We will develop a multi-output neural network model capable of making regression and classification predictions at the same time.
First, let’s select a dataset where this requirement makes sense and start by developing separate models for both regression and classification predictions.
Separate Regression and Classification Models
In this section, we will start by selecting a real dataset where we may want regression and classification predictions at the same time, then develop separate models for each type of prediction.
Abalone Dataset
We will use the “abalone” dataset.
Determining the age of an abalone is a time-consuming task and it is desirable to determine the age from physical details alone.
This is a dataset that describes the physical details of abalone and requires predicting the number of rings of the abalone, which is a proxy for the age of the creature.
You can learn more about the dataset from here:
The “age” can be predicted as both a numerical value (in years) or a class label (ordinal year as a class).
No need to download the dataset as we will download it automatically as part of the worked examples.
The dataset provides an example of a dataset where we may want both a numerical and classification of an input.
First, let’s develop an example to download and summarize the dataset.
# load and summarize the abalone dataset from pandas import read_csv from matplotlib import pyplot # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv' dataframe = read_csv(url, header=None) # summarize shape print(dataframe.shape) # summarize first few lines print(dataframe.head())
Running the example first downloads and summarizes the shape of the dataset.
We can see that there are 4,177 examples (rows) that we can use to train and evaluate a model and 9 features (columns) including the target variable.
We can see that all input variables are numeric except the first, which is a string value.
To keep data preparation simple, we will drop the first column from our models and focus on modeling the numeric input values.
(4177, 9) 0 1 2 3 4 5 6 7 8 0 M 0.455 0.365 0.095 0.5140 0.2245 0.1010 0.150 15 1 M 0.350 0.265 0.090 0.2255 0.0995 0.0485 0.070 7 2 F 0.530 0.420 0.135 0.6770 0.2565 0.1415 0.210 9 3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10 4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
We can use the data as the basis for developing separate regression and classification Multilayer Perceptron (MLP) neural network models.
Note: we are not trying to develop an optimal model for this dataset; instead we are demonstrating a specific technique: developing a model that can make both regression and classification predictions.
Regression Model
In this section, we will develop a regression MLP model for the abalone dataset.
First, we must separate the columns into input and output elements and drop the first column that contains string values.
We will also force all loaded columns to have a float type (expected by neural network models) and record the number of input features, which will need to be known by the model later.
...
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
Next, we can split the dataset into a train and test dataset.
We will use a 67% random sample to train the model and the remaining 33% to evaluate the model.
... # split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
We can then define an MLP neural network model.
The model will have two hidden layers, the first with 20 nodes and the second with 10 nodes, both using ReLU activation and “he normal” weight initialization (a good practice). The number of layers and nodes were chosen arbitrarily.
The output layer will have a single node for predicting a numeric value and a linear activation function.
... # define the keras model model = Sequential() model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal')) model.add(Dense(10, activation='relu', kernel_initializer='he_normal')) model.add(Dense(1, activation='linear'))
The model will be trained to minimize the mean squared error (MSE) loss function using the effective Adam version of stochastic gradient descent.
... # compile the keras model model.compile(loss='mse', optimizer='adam')
We will train the model for 150 epochs with a mini-batch size of 32 samples, again chosen arbitrarily.
... # fit the keras model on the dataset model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
Finally, after the model is trained, we will evaluate it on the holdout test dataset and report the mean absolute error (MAE).
...
# evaluate on test set
yhat = model.predict(X_test)
error = mean_absolute_error(y_test, yhat)
print('MAE: %.3f' % error)
Tying this all together, the complete example of an MLP neural network for the abalone dataset framed as a regression problem is listed below.
# regression mlp model for the abalone dataset
from pandas import read_csv
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
dataset = dataframe.values
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define the keras model
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='linear'))
# compile the keras model
model.compile(loss='mse', optimizer='adam')
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
# evaluate on test set
yhat = model.predict(X_test)
error = mean_absolute_error(y_test, yhat)
print('MAE: %.3f' % error)
Running the example will prepare the dataset, fit the model, and report an estimate of model error.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an error of about 1.5 (rings).
... Epoch 145/150 88/88 - 0s - loss: 4.6130 Epoch 146/150 88/88 - 0s - loss: 4.6182 Epoch 147/150 88/88 - 0s - loss: 4.6277 Epoch 148/150 88/88 - 0s - loss: 4.6437 Epoch 149/150 88/88 - 0s - loss: 4.6166 Epoch 150/150 88/88 - 0s - loss: 4.6132 MAE: 1.554
So far so good.
Next, let’s look at developing a similar model for classification.
Classification Model
The abalone dataset can be framed as a classification problem where each “ring” integer is taken as a separate class label.
The example and model are much the same as the above example for regression, with a few important changes.
This requires first assigning a separate integer for each “ring” value, starting at 0 and ending at the total number of “classes” minus one.
This can be achieved using the LabelEncoder.
We can also record the total number of classes as the total number of unique encoded class values, which will be needed by the model later.
... # encode strings to integer y = LabelEncoder().fit_transform(y) n_class = len(unique(y))
After splitting the data into train and test sets as before, we can define the model and change the number of outputs from the model to equal the number of classes and use the softmax activation function, common for multi-class classification.
... # define the keras model model = Sequential() model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal')) model.add(Dense(10, activation='relu', kernel_initializer='he_normal')) model.add(Dense(n_class, activation='softmax'))
Given we have encoded class labels as integer values, we can fit the model by minimizing the sparse categorical cross-entropy loss function, appropriate for multi-class classification tasks with integer encoded class labels.
... # compile the keras model model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
After the model is fit on the training dataset as before, we can evaluate the performance of the model by calculating the classification accuracy on the hold-out test set.
...
# evaluate on test set
yhat = model.predict(X_test)
yhat = argmax(yhat, axis=-1).astype('int')
acc = accuracy_score(y_test, yhat)
print('Accuracy: %.3f' % acc)
Tying this all together, the complete example of an MLP neural network for the abalone dataset framed as a classification problem is listed below.
# classification mlp model for the abalone dataset
from numpy import unique
from numpy import argmax
from pandas import read_csv
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
dataset = dataframe.values
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# encode strings to integer
y = LabelEncoder().fit_transform(y)
n_class = len(unique(y))
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define the keras model
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(n_class, activation='softmax'))
# compile the keras model
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
# evaluate on test set
yhat = model.predict(X_test)
yhat = argmax(yhat, axis=-1).astype('int')
acc = accuracy_score(y_test, yhat)
print('Accuracy: %.3f' % acc)
Running the example will prepare the dataset, fit the model, and report an estimate of model error.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an accuracy of about 27%.
... Epoch 145/150 88/88 - 0s - loss: 1.9271 Epoch 146/150 88/88 - 0s - loss: 1.9265 Epoch 147/150 88/88 - 0s - loss: 1.9265 Epoch 148/150 88/88 - 0s - loss: 1.9271 Epoch 149/150 88/88 - 0s - loss: 1.9262 Epoch 150/150 88/88 - 0s - loss: 1.9260 Accuracy: 0.274
So far so good.
Next, let’s look at developing a combined model capable of both regression and classification predictions.
Combined Regression and Classification Models
In this section, we can develop a single MLP neural network model that can make both regression and classification predictions for a single input.
This is called a multi-output model and can be developed using the functional Keras API.
For more on this functional API, which can be tricky for beginners, see the tutorials:
- TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras
- How to Use the Keras Functional API for Deep Learning
First, the dataset must be prepared.
We can prepare the dataset as we did before for classification, although we should save the encoded target variable with a separate name to differentiate it from the raw target variable values.
... # encode strings to integer y_class = LabelEncoder().fit_transform(y) n_class = len(unique(y_class))
We can then split the input, raw output, and encoded output variables into train and test sets.
... # split data into train and test sets X_train, X_test, y_train, y_test, y_train_class, y_test_class = train_test_split(X, y, y_class, test_size=0.33, random_state=1)
Next, we can define the model using the functional API.
The model takes the same number of inputs as before with the standalone models and uses two hidden layers configured in the same way.
... # input visible = Input(shape=(n_features,)) hidden1 = Dense(20, activation='relu', kernel_initializer='he_normal')(visible) hidden2 = Dense(10, activation='relu', kernel_initializer='he_normal')(hidden1)
We can then define two separate output layers that connect to the second hidden layer of the model.
The first is a regression output layer that has a single node and a linear activation function.
... # regression output out_reg = Dense(1, activation='linear')(hidden2)
The second is a classification output layer that has one node for each class being predicted and uses a softmax activation function.
... # classification output out_clas = Dense(n_class, activation='softmax')(hidden2)
We can then define the model with a single input layer and two output layers.
... # define model model = Model(inputs=visible, outputs=[out_reg, out_clas])
Given the two output layers, we can compile the model with two loss functions, mean squared error loss for the first (regression) output layer and sparse categorical cross-entropy for the second (classification) output layer.
... # compile the keras model model.compile(loss=['mse','sparse_categorical_crossentropy'], optimizer='adam')
We can also create a plot of the model for reference.
This requires that pydot and pygraphviz are installed. If this is a problem, you can comment out this line and the import statement for the plot_model() function.
... # plot graph of model plot_model(model, to_file='model.png', show_shapes=True)
Each time the model makes a prediction, it will predict two values.
Similarly, when training the model, it will need one target variable per sample for each output.
As such, we can train the model, carefully providing both the regression target and classification target data to each output of the model.
... # fit the keras model on the dataset model.fit(X_train, [y_train,y_train_class], epochs=150, batch_size=32, verbose=2)
The fit model can then make a regression and classification prediction for each example in the hold-out test set.
... # make predictions on test set yhat1, yhat2 = model.predict(X_test)
The first array can be used to evaluate the regression predictions via mean absolute error.
...
# calculate error for regression model
error = mean_absolute_error(y_test, yhat1)
print('MAE: %.3f' % error)
The second array can be used to evaluate the classification predictions via classification accuracy.
...
# evaluate accuracy for classification model
yhat2 = argmax(yhat2, axis=-1).astype('int')
acc = accuracy_score(y_test_class, yhat2)
print('Accuracy: %.3f' % acc)
And that’s it.
Tying this together, the complete example of training and evaluating a multi-output model for combiner regression and classification predictions on the abalone dataset is listed below.
# mlp for combined regression and classification predictions on the abalone dataset
from numpy import unique
from numpy import argmax
from pandas import read_csv
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import plot_model
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
dataset = dataframe.values
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# encode strings to integer
y_class = LabelEncoder().fit_transform(y)
n_class = len(unique(y_class))
# split data into train and test sets
X_train, X_test, y_train, y_test, y_train_class, y_test_class = train_test_split(X, y, y_class, test_size=0.33, random_state=1)
# input
visible = Input(shape=(n_features,))
hidden1 = Dense(20, activation='relu', kernel_initializer='he_normal')(visible)
hidden2 = Dense(10, activation='relu', kernel_initializer='he_normal')(hidden1)
# regression output
out_reg = Dense(1, activation='linear')(hidden2)
# classification output
out_clas = Dense(n_class, activation='softmax')(hidden2)
# define model
model = Model(inputs=visible, outputs=[out_reg, out_clas])
# compile the keras model
model.compile(loss=['mse','sparse_categorical_crossentropy'], optimizer='adam')
# plot graph of model
plot_model(model, to_file='model.png', show_shapes=True)
# fit the keras model on the dataset
model.fit(X_train, [y_train,y_train_class], epochs=150, batch_size=32, verbose=2)
# make predictions on test set
yhat1, yhat2 = model.predict(X_test)
# calculate error for regression model
error = mean_absolute_error(y_test, yhat1)
print('MAE: %.3f' % error)
# evaluate accuracy for classification model
yhat2 = argmax(yhat2, axis=-1).astype('int')
acc = accuracy_score(y_test_class, yhat2)
print('Accuracy: %.3f' % acc)
Running the example will prepare the dataset, fit the model, and report an estimate of model error.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
A plot of the multi-output model is created, clearly showing the regression (left) and classification (right) output layers connected to the second hidden layer of the model.
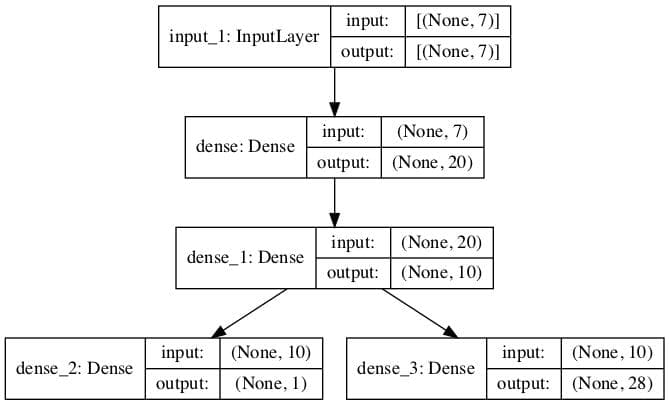
Plot of the Multi-Output Model for Combine Regression and Classification Predictions
In this case, we can see that the model achieved both a reasonable error of about 1.495 (rings) and a similar accuracy as before of about 25.6%.
... Epoch 145/150 88/88 - 0s - loss: 6.5707 - dense_2_loss: 4.5396 - dense_3_loss: 2.0311 Epoch 146/150 88/88 - 0s - loss: 6.5753 - dense_2_loss: 4.5466 - dense_3_loss: 2.0287 Epoch 147/150 88/88 - 0s - loss: 6.5970 - dense_2_loss: 4.5723 - dense_3_loss: 2.0247 Epoch 148/150 88/88 - 0s - loss: 6.5640 - dense_2_loss: 4.5389 - dense_3_loss: 2.0251 Epoch 149/150 88/88 - 0s - loss: 6.6053 - dense_2_loss: 4.5827 - dense_3_loss: 2.0226 Epoch 150/150 88/88 - 0s - loss: 6.5754 - dense_2_loss: 4.5524 - dense_3_loss: 2.0230 MAE: 1.495 Accuracy: 0.256
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- Difference Between Classification and Regression in Machine Learning
- TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras
- Best Results for Standard Machine Learning Datasets
- How to Use the Keras Functional API for Deep Learning
Summary
In this tutorial, you discovered how to develop a neural network for combined regression and classification predictions.
Specifically, you learned:
- Some prediction problems require predicting both numeric and class label values for each input example.
- How to develop separate regression and classification models for problems that require multiple outputs.
- How to develop and evaluate a neural network model capable of making simultaneous regression and classification predictions.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Neural Network Models for Combined Classification and Regression appeared first on Machine Learning Mastery.