Author: Aafrin Dabhoiwala
Hadoop – MapReduce in an easy way
In the previous blog, we discussed about HDFS, one of the main components of Hadoop. I highly recommend going through that blog before moving onto MapReduce. This blog will introduce you to MapReduce, which is the main building blocks of processing in Hadoop framework. MapReduce is considered as the heart of Hadoop. Now, let see what makes MapReduce so popular in Hadoop framework.
What is MapReduce?
MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets in a distributed environment.

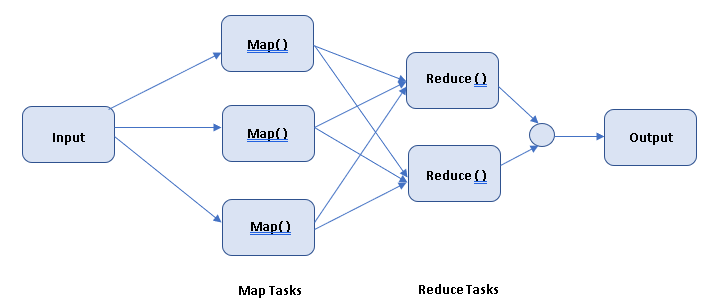
As shown in the above figure, input data is divided into partitions that are Mapped (transformed) and Reduced (aggregated) by mapper and reduced functions respectively that you define, and finally gives the output.
First – Map takes a set of data (Input) and converts it into another set of data, where individual elements are broken down into Key/Value pairs.
Second – Reduce takes the output from a map as an input and combines those Key/Value pairs into smaller set of Key/Value pairs.
As the sequence of the MapReduce implies, the reduce tasks are always performed after the map tasks.
How MapReduce works?

As shown in the above figure, the input data goes through the following phases:
Map Tasks
- Splitting
Input to MapReduce job is divided into fixed-size chunks called input splits. It produces the output in (Key, Value) pair.
- Mapping
In this phase each input split is passed to a mapping function which divides the split into List (Key, Value).
Reduce Tasks
- Shuffling and Sorting
Reduce tasks are the combination of shuffle/sort and reduce. This phase consumes output of the Mapping phase. Its main task is to club together the relevant record in sorting manner from the output of mapping phase. The output is in the form of Key, List (Value).
- Reducing
In this phase, output from shuffling and sorting are aggregated and returns single (Key, Value) output value. This final output value is then written in the output file of HDFS.
How MapReduce works with an Example
- Task – How many movies did each user rate in the Movie data set?
- Sample Dataset (Input File)–
|
UserId |
MovieId |
Rating |
Timestamp |
|
100 |
319 |
4 |
343003432 |
|
120 |
387 |
2 |
439439839 |
|
100 |
435 |
4 |
545847584 |
|
121 |
34 |
3 |
121212121 |
|
120 |
212 |
3 |
548598459 |
|
218 |
78 |
1 |
454545454 |
|
100 |
343 |
2 |
323323232 |
- Map Tasks (Splitting and Mapping)
As we need to find the number of movies each user rated, we are interested in just two field from the data set – UserId and MovieId. We will extract and organize only the data what we care about.
The output from the Map Tasks is the (Key, Value) pair –
(100,319), (120,387), (100,435), (121,34), (120,212), (218,78), (100,343)
- Shuffling and sorting
This process sorts and groups/clubs the Mapped data from the above step
The output from shuffling and sorting is the Key, List (Values)–
100, (319, 435, 343) 120, (387,212) 121, (34) 218, (78)
- Reducing
This processes each key’s value from the above step. Reducer function would be to find the number of movies. It computes the aggregation of the MovieIds for each user. Reducer writes the final output to the HDFS.
The output of this step is (key, value) pair –
(100,3) (120,2) (121,1) (218,1)
- Conclusion
From the above MapReduce steps, user id-
100 rated 3 movies,
120 rated 2 movies,
121 and 218 rated 1 movie
Putting it all together in a Diagram

How MapReduce distributes processing (In Detail)?
Now let’s understand the complete end to end workflow of MapReduce in Hadoop, how input is given to the mapper, how mapper process the data, where mapper writes the data, how data is shuffled and sorted from mapper to reducer nodes, where reducers run and what type of processing is done in the reducers? All these questions will be answered in the following:

Step 1 – MapReduce workflow starts with the client program submitting job to the JobTracker*
- *JobTracker– a job configuration which specifies the map and reduce functions, as well as input and output path of the data. It also schedules jobs and tracks the assign jobs to the TaskTracker*
- *TastTracker – It tracks the tasks and reports status to JobTracker.
Step 2 – JobTracker will determine the number of splits from the input path of the data and it will select some TaskTrackers based on their network proximity to the data source. Then, the JobTracker send the task requests to those selected TaskTrackers.
Step 3 – Each Tasktracker will start the Map Phase processing by extracting input data from the splits. For each record parsed by the InputFormatter, it invokes the user provided ‘Map’ function, which stores several key-value pair in the circular memory buffer* (100MB default size)
- *Memory buffer – it is found mainly in RAM and acts as an area where the CPU can store data temporarily.
If the memory buffer fills up or if it reaches its maximum threshold (100 MB by default), mapper will block filling of data and spilling/transferring of data takes place from memory buffer to the local disk until the buffer has space for incoming data.
Step 4 – Before spilling the data into the disk, the thread will divide the data into partition corresponding to the reducers which it will ultimately send to. For each partition, the background thread will perform in-memory sort by Key. Each time memory buffer reaches the threshold of filling data, a new spill file is created. There could be several spill files after the map task has written its last output record.
Step 5 – Before a map task is finished, all spill files are merged into a single partition and stored into the output files in the disk.
Step 6 – When the map task completes (all splits are done), the TaskTracker will notify the JobTracker. When all the TaskTrackers are done, the JobTracker will notify the selected TaskTrackers for the Reduce Phase. Hence, each TaskTracker will read the output files remoted from the above step and sort the Key-Value pairs. For each key, it invokes the “reduce” function, which collects the key- aggregatedValue and writes it into the output file (one per reducer node).
The JobTracker keep tracks of the progress of each phase and periodically ping the TaskTracker for their health status. When any of the map phase TaskTracker crashes, the JobTracker will reassign the map task to a different TaskTracker node, which will rerun all the assigned splits. If the reduce phase TaskTracker crashes, the JobTracker will rerun the reduce at a different TaskTracker.
Step 7 – After both phases are complete, the JobTracker will unblock the client program.
What are the advantages of MapReduce?
Resilient to Failure – an application master watch mapper and reducer tasks on each partition.
Data processing is easy to scale over multiple computing nodes.
Parallel processing – In MapReduce, jobs are divided among multiple nodes and each node works with a part of the job simultaneously and hence helps to process the data using different machines. As the data is processed by different machines in parallel, the time taken to process the data gets reduced by a tremendous amount.
Cost-effective solution – Hadoop’s highly scalable structure also implies that it comes across as a very cost-effective solution for businesses that need to store ever growing data dictated by today’s requirements. Hadoop’s scale-out architecture with MapReduce, allows the storage and processing of data in a very affordable manner.
Fast – The tools of data processing; here MapReduce are often on the same servers where the data is located, resulting in faster data processing.
In the next blog, we shall discuss about YARN which is another key feature of Hadoop. Stay tuned.