
Author: Jason Brownlee
Practical deep learning is a challenging subject in which to get started.
It is often taught in a bottom-up manner, requiring that you first get familiar with linear algebra, calculus, and mathematical optimization before eventually learning the neural network techniques. This can take years, and most of the background theory will not help you to get good results, fast.
Instead, a top-down approach can be used where first you learn how to get results with deep learning models on real-world problems and later learn more about how the methods work.
This is the exact approach used in the popular cause taught at fast.ai titled “Practical Deep Learning for Coders.”
In this post, you will discover the fast.ai course for developers looking to get started and get good at deep learning, including an overview of the course itself, the best practices introduced in the course, and a discussion and review of the whole course.
Let’s get started.

Practical Deep Learning for Coders Review
Photo by Fraser Mummery, some rights reserved.
Overview
This tutorial is divided into four parts; they are:
- Course Overview
- Course Breakdown
- Best Practices
- Discussion and Review
Course Overview
fast.ai is a small organization that provides free training on practical machine learning and deep learning.
Their mission is to make deep learning accessible to all, really to developers.
At the time of writing, fast.ai offers four courses; they are:
- Practical Deep Learning for Coders, Part 1
- Cutting-Edge Deep Learning for Coders, Part 2
- Introduction to Machine Learning for Coders
- Computational Linear Algebra for Coders
The organization was founded by Jeremy Howard (Enlitic, Kaggle, and more) and Rachel Thomas (University of San Francisco, Uber, and more).
Jeremy is a world-class practitioner, who first achieved top performance on Kaggle and later joined the company. Anything he has to say on the practice of machine learning or deep learning should be considered. Rachel has the academic (Ph.D.) and math chops required in the partnership and has gone on to provide a sister course on some relevant mathematical underpinnings of deep learning.
Most courses are first delivered at the University of San Francisco by either Jeremy or Rachel, then the videos and course material are made available for free.
Of note is their first and most important course:
- Practical Deep Learning for Coders (part 1).
This course was first delivered and made available at the end of 2016. It was recently updated or recreated (end of 2017), which is the current version of the course that is available at the time of writing. This may change with future updates.
Importantly, the main change from v1 to v2 of the course was the shift away from the Keras deep learning framework (wrapper for Google’s TensorFlow) to their own open source fast.ai library that provides a wrapper for Facebook’s PyTorch deep learning framework.
This move away from Keras towards PyTorch was made in the interest of flexibility. Their own wrapper captures many state-of-the-art methods and best practices but also hides a lot of the detail. It may be best suited to practitioners and less so to academics than the more general Keras.
Course Breakdown
The most recent version of the course available online was delivered and recorded at the end of 2017 (e.g. the 2018 version).
The full list of lectures for the course is listed below (links to each embedded video).
- 1. Recognizing cats and dogs.
- 2. Improving your image classifier.
- 3. Understanding convolutions.
- 4. Structured, time series & and language models.
- 5. Collaborative filtering. Inside the training loop.
- 6. Interpreting embeddings. RNNs from scratch.
- 7. Resnets from scratch.
I prefer to watch the videos at double speed and take notes. All videos are available as a YouTube playlist.
You can also watch the videos embedded on the course homepage with links to subsequent lectures as well as materials used on each lecture, such as wiki, forum discussion, and notebooks. This is the recommended way of working through the material on your own.

Example of Embedding Lecture with Course Materials
The course teaches via a top-down, rather than a bottom-up, approach. Specifically, this means first showing how to do something, then later repeating the process but showing all of the detail. This does not mean math and theory in the follow-up necessarily; instead, it refers to the practical concerns of how to achieve a result.
It is an excellent way of approaching the material. A slide in lecture 3 (which shows up many times throughout the course) provides an overview of this approach to deep learning; specifically, the first few tutorials demonstrate how to achieve results with computer vision, structured data (tabular data), natural language processing, and collaborative filtering, then these topics are covered in reverse order again but models are developed from scratch to show how they work (i.e. not why they work).
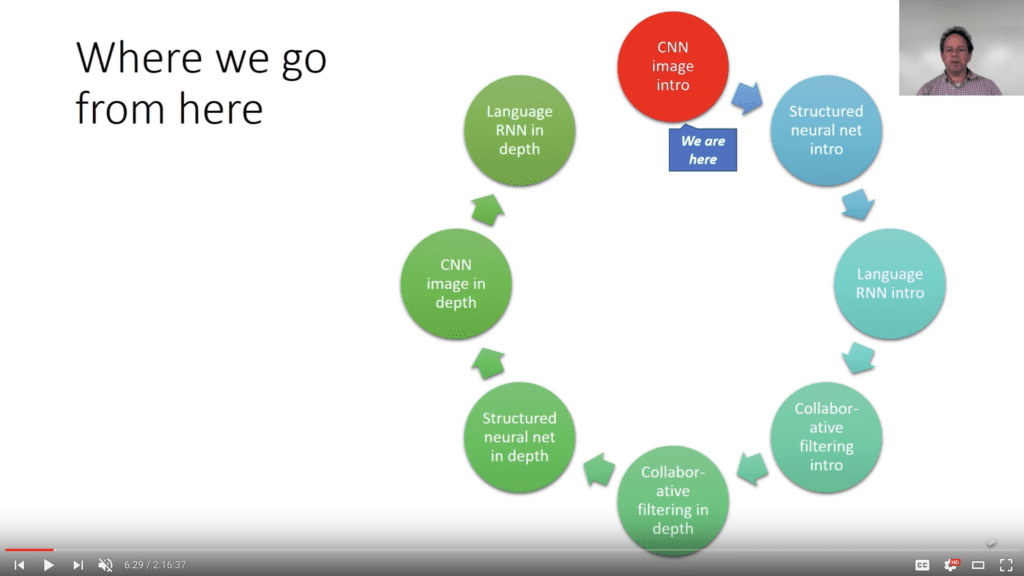
Overview of Course Structure
Best Practices
A focus of the course is on teaching best practices.
These are the recommended ways of approaching and working through specific predictive modeling problems using deep learning methods.
Best practices are presented both in terms of process (e.g. a consistent way of working through a new predictive modeling problem) and techniques. They are also baked into the PyTorch wrapper called fast.ai used in all lectures.
Many best practices are covered, and some are subtle in that it is the way the subject is introduced rather than the practice being pointed out as an alternative to a conventional approach.
There has been some attempt to catalog the best practices; for example:
- 30+ Best Practices, Forum Post.
- Deep Learning Best Practices, GitHub.
- fastai v1 for PyTorch: Fast and accurate neural nets using modern best practices.
- Ten Techniques Learned From fast.ai
Looking at my notes, some best practices that I took away were the following:
- Always use transfer learning (e.g. ImageNet model) as a starting point in computer vision, but carefully choose the point in the model to add new layers.
- Try different learning rates for different layers in transfer learning for computer vision (e.g. differential learning).
- Use test time augmentation to give a model multiple chances of making a good prediction (wow!).
- First train a model with very small images, then later re-train with larger images (e.g. progress resizing of images).
- Use cyclical learning rates to quickly find a good learning rate for SGD (e.g. the learning rate finder).
- Use cosine annealing learning rate schedule with restarts during training.
- Use transfer learning for language models.
- Use of embedding layers more broadly, such as for all categorical input variables, not just words.
- Use of embedding layers for movies and users in collaborative filtering.
I was across each of these methods, I just had not considered that they should be the starting point (e.g. best practice). Instead, I considered them tools to bring to a project to lift performance when needed.
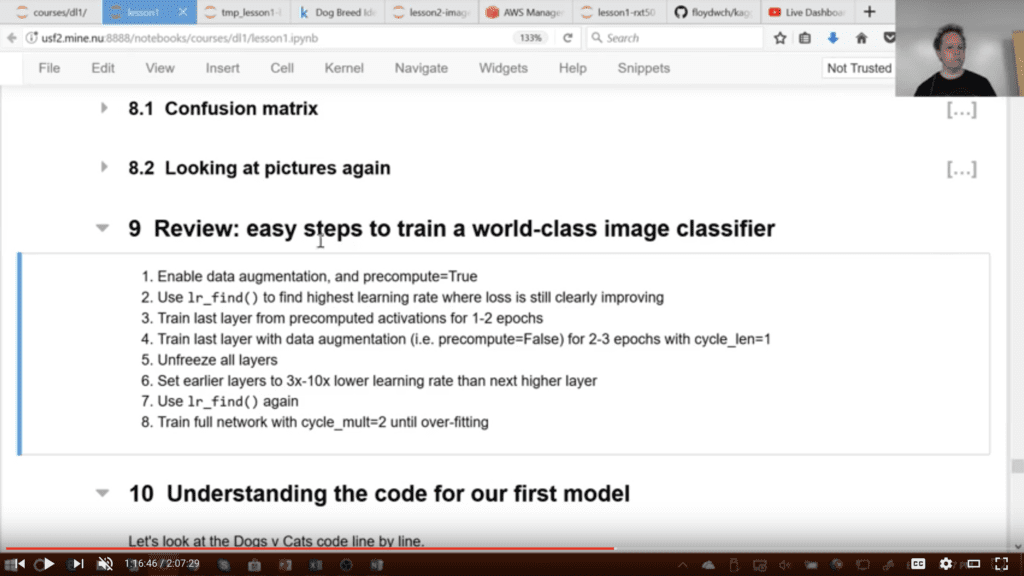
Easy Steps to Train a World-Class Image Classifier
Discussion and Review
The course is excellent.
- Jeremy is a master practitioner and an excellent communicator.
- The level of detail is right: high-level first, then lower-level, but all how-to, not why.
- Application focused rather than technique focused.
If you’re a deep learning practitioner or you want to be, then the course is required viewing.
The videos are too long for me. I used the YouTube playlist and watched videos on double time while I took notes in a text editor.
I am not interested in using the fast.ai library or pytorch at this stage, so I skimmed or skipped over the code specific parts. In general, I prefer not to learn code from video, so I would skip these sections anyway.
The value of these lectures is in seeing the steps and thought processes behind the specific way that Jeremy works through predictive modeling problems using deep learning methods. Because he is focused on good and fast results, you get exactly what you need to know, without the detail and background that everyone else forces you to wade through before getting to the point.
A little like Andrew Ng, he explains everything so simply that you feel confident enough to pick up the tools and start using them.
His competence with Kaggle competitions makes you want to dive into past competition datasets to test the methods immediately.
Finally, the sense of community he cultivates on the forum and in calling out blog posts that summarize his teachings makes you want to join and contribute.
Again, if you at all care about being a deep learning practitioner, it is required viewing.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Practical Deep Learning For Coders, Part 1, Homepage.
- Deep Learning Certificate Part I, Homepage.
- Practical Deep Learning For Coders 1, YouTube Playlist.
- Practical Deep Learning For Coders, Python Notebooks.
- fastai PyTorch Wrapper.
- The Fastai v1 Deep Learning Framework with Jeremy Howard, Podcast Interview.
Summary
In this post, you discovered the fast.ai course for developers looking to get started and get good at deep learning
Have you taken this course or worked through any of the material?
Let me know your thoughts on it in the comments below.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Practical Deep Learning for Coders (Review) appeared first on Machine Learning Mastery.