
Author: Jason Brownlee
The Empirical Heuristics, Tips, and Tricks That You Need to Know to Train Stable Generative Adversarial Networks (GANs).
Generative Adversarial Networks, or GANs for short, are an approach to generative modeling using deep learning methods such as deep convolutional neural networks.
Although the results generated by GANs can be remarkable, it can be challenging to train a stable model. The reason is that the training process is inherently unstable, resulting in the simultaneous dynamic training of two competing models.
Nevertheless, given a large amount of empirical trial and error but many practitioners and researchers, a small number of model architectures and training configurations have been found and reported that result in the reliable training of a stable GAN model.
In this post, you will discover empirical heuristics for the configuration and training of stable general adversarial network models.
After reading this post, you will know:
- The simultaneous training of generator and discriminator models in GANs is inherently unstable.
- Hard-earned empirically discovered configurations for the DCGAN provide a robust starting point for most GAN applications.
- Stable training of GANs remains an open problem and many other empirically discovered tips and tricks have been proposed and can be immediately adopted.
Let’s get started.

How to Train Stable Generative Adversarial Networks
Taken by Chris Sternal-Johnson, some rights reserved.
Overview
This tutorial is divided into three parts; they are:
- Challenge of Training GANs
- Deep Convolutional GAN
- Additional Tips and Tricks
Challenge of Training Generative Adversarial Networks
GANs are difficult to train.
The reason they are difficult to train is that both the generator model and the discriminator model are trained simultaneously in a game. This means that improvements to one model come at the expense of the other model.
The goal of training two models involves finding a point of equilibrium between the two competing concerns.
Training GANs consists in finding a Nash equilibrium to a two-player non-cooperative game. […] Unfortunately, finding Nash equilibria is a very difficult problem. Algorithms exist for specialized cases, but we are not aware of any that are feasible to apply to the GAN game, where the cost functions are non-convex, the parameters are continuous, and the parameter space is extremely high-dimensional
— Improved Techniques for Training GANs, 2016.
It also means that every time the parameters of one of the models are updated, the nature of the optimization problem that is being solved is changed.
This has the effect of creating a dynamic system.
But with a GAN, every step taken down the hill changes the entire landscape a little. It’s a dynamic system where the optimization process is seeking not a minimum, but an equilibrium between two forces.
— Page 306, Deep Learning with Python, 2017.
In neural network terms, the technical challenge of training two competing neural networks at the same time is that they can fail to converge.
The largest problem facing GANs that researchers should try to resolve is the issue of non-convergence.
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
Instead of converging, GANs may suffer from one of a small number of failure modes.
A common failure mode is that instead of finding a point of equilibrium, the generator oscillates between generating specific examples in the domain.
In practice, GANs often seem to oscillate, […] meaning that they progress from generating one kind of sample to generating another kind of sample without eventually reaching an equilibrium.
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
Perhaps the most challenging model failure is the case where multiple inputs to the generator result in the generation of the same output.
This is referred to as “mode collapse,” and may represent one of the most challenging issues when training GANs.
Mode collapse, also known as the scenario, is a problem that occurs when the generator learns to map several different input z values to the same output point.
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
Finally, there are no good objective metrics for evaluating whether a GAN is performing well during training. E.g. reviewing loss is not sufficient.
Instead, the best approach is to visually inspect generated examples and use subjective evaluation.
Generative adversarial networks lack an objective function, which makes it difficult to compare performance of different models. One intuitive metric of performance can be obtained by having human annotators judge the visual quality of samples.
— Improved Techniques for Training GANs, 2016.
At the time of writing, there is no good theoretical foundation as to how to design and train GAN models, but there is an established literature of heuristics, or “hacks,” that have been empirically demonstrated to work well in practice.
Deep Convolutional Generative Adversarial Networks
Perhaps one of the most important steps forward in the design and training of stable GAN models was the 2015 paper by Alec Radford, et al. titled “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.”
In the paper, they describe the Deep Convolutional GAN, or DCGAN, approach to GAN development that has become the de facto standard.
Stabilization of GAN learning remains an open problem. Fortunately, GAN learning performs well when the model architecture and hyperparameters are carefully selected. Radford et al. (2015) crafted a deep convolutional GAN (DCGAN) that performs very well for image synthesis tasks …
— Page 701, Deep Learning, 2016.
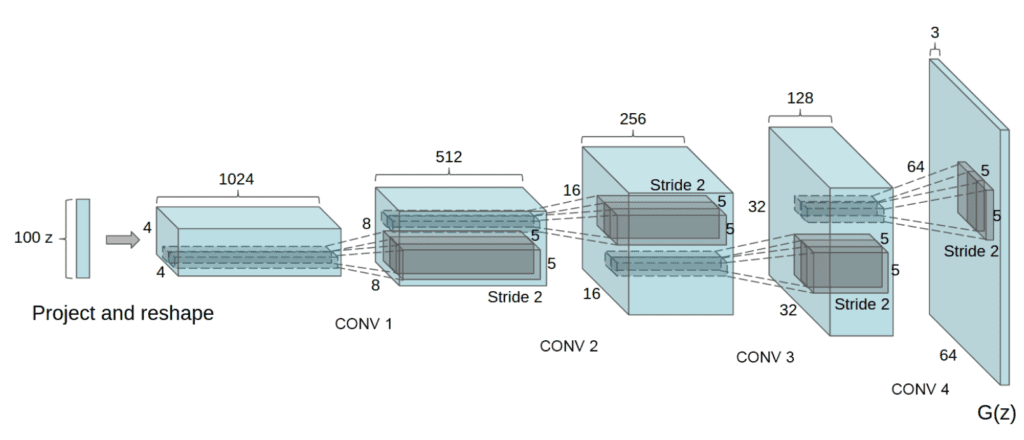
Example of the Generator Model Architecture for the DCGAN.
Taken from Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
The findings in this paper were hard earned, developed after extensive empirical trial and error with different model architectures, configurations, and training schemes. Their approach remains highly recommended as a starting point when developing new GANs, at least for image-synthesis-based tasks.
… after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
Below provides a summary of the GAN architecture recommendations from the paper.

Summary of Architectural Guidelines for Training Stable Deep Convolutional Generative Adversarial Networks.
Taken From Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Let’s take a closer look.
1. Use Strided Convolutions
It is common to use pooling layers such as max-pooling layers for downsampling in convolutional neural networks.
In GANs, the recommendation is to not use pooling layers, and instead use the stride in convolutional layers to perform downsampling in the discriminator model.
Similarly, fractional stride (deconvolutional layers) can be used in the generator for upsampling.
[replace] deterministic spatial pooling functions (such as max pooling) with strided convolutions, allowing the network to learn its own spatial downsampling. We use this approach in our generator, allowing it to learn its own spatial upsampling, and discriminator.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
2. Remove Fully-Connected Layers
It is common to use fully-connected layers after feature extraction layers in convolutional layers as an interpretation of the extracted features prior to the output layers of the model.
Instead, in GANs, fully-connected layers are not used, in the discriminator and the convolutional layers are flattened and passed directly to the output layer.
Additionally, the random Gaussian input vector passed to the generator model is reshaped directly into a multi-dimensional tensor that can be passed to the first convolutional layer ready for upscaling.
The first layer of the GAN, which takes a uniform noise distribution Z as input, could be called fully connected as it is just a matrix multiplication, but the result is reshaped into a 4-dimensional tensor and used as the start of the convolution stack. For the discriminator, the last convolution layer is flattened and then fed into a single sigmoid output.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
3. Use Batch Normalization
Batch normalization standardizes the activations from a prior layer to have a zero mean and unit variance. This has the effect of stabilizing the training process.
Batch normalization has become a staple when training deep convolutional neural networks, and GANs are no different. Batch norm layers are recommended in both the discriminator and generator models, except the output of the generator and input to the discriminator.
Directly applying batchnorm to all layers however, resulted in sample oscillation and model instability. This was avoided by not applying batchnorm to the generator output layer and the discriminator input layer.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
4. Use ReLU, Leaky ReLU, and Tanh
Activation functions such as ReLU are used to address the vanishing gradient problem in deep convolutional neural networks and promote sparse activations (e.g. lots of zero values).
ReLU is recommended for the generator, but not for the discriminator model. Instead, a variation of ReLU that allows values less than zero, called Leaky ReLU, is preferred in the discriminator.
The ReLU activation is used in the generator with the exception of the output layer which uses the Tanh function. […] Within the discriminator we found the leaky rectified activation to work well …
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Additionally, the generator uses the hyperbolic tangent (tanh) activation function in the output layer and inputs to the generator and discriminator are scaled to the range [-1, 1].
No pre-processing was applied to training images besides scaling to the range of the tanh activation function [-1, 1].
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
Model weights were initialized to small Gaussian random values and the slope of the Leaky ReLU in the discriminator was initialized to a value of 0.2.
All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02. In the LeakyReLU, the slope of the leak was set to 0.2 in all models.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
5. Use Adam Optimization
Both the generator and discriminator are trained with stochastic gradient descent with a modest batch size of 128 images.
All models were trained with mini-batch stochastic gradient descent (SGD) with a mini-batch size of 128
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Specifically, the Adam version of stochastic gradient descent was used to train the models with a learning rate of 0.0002 and a momentum (beta1) of 0.5.
We used the Adam optimizer with tuned hyperparameters. We found the suggested learning rate of 0.001, to be too high, using 0.0002 instead. Additionally, we found leaving the momentum term β1 at the suggested value of 0.9 resulted in training oscillation and instability while reducing it to 0.5 helped stabilize training.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Additional Tips and Tricks
The DCGAN paper provides an excellent starting point for configuring and training the generator and discriminator models.
Additionally, a number of review presentations and papers have been written to summarize these and additional heuristics for configuring and training GANs.
In this section, we will look at a few of these and highlight some additional tips and tricks to consider.
The 2016 paper by Tim Salimans, et al. from OpenAI titled “Improved Techniques for Training GANs” lists five techniques to consider that are claimed to improve convergence when training GANs.
They are:
- Feature matching. Develop a GAN using semi-supervised learning.
- Minibatch discrimination. Develop features across multiple samples in a minibatch.
- Historical averaging. Update the loss function to incorporate history.
- One-sided label smoothing. Scaling target values for the discriminator away from 1.0.
- Virtual batch normalization. Calculation of batch norm statistics using a reference batch of real images.
In his 2016 tutorial on GANs at the NIPS conference, Ian Goodfellow elaborates on some of the more successful of these suggestions, written up in the accompanying paper titled “Tutorial: Generative Adversarial Networks.” Specifically, Section 4 titled “Tips and Tricks” in which four techniques are described.
They are:
1. Train with labels. Making use of labels in the GANs improves image quality.
Using labels in any way, shape or form almost always results in a dramatic improvement in the subjective quality of the samples generated by the model.
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
2. One-sided label smoothing. Using targets for real examples in the discriminator with a value of 0.9 or targets with a stochastic range delivers better results.
The idea of one-sided label smoothing is to replace the target for the real examples with a value slightly less than one, such as .9 […] This prevents extreme extrapolation behavior in the discriminator …
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
3. Virtual batch normalization. Calculating batch statistics on real images or real images with one generated image is better.
… one can instead use virtual batch normalization, in which the normalization statistics for each example are computed using the union of that example and the reference batch
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
4. Can one balance G and D? Scheduling more or less training in the generator or discriminator based on relative changes in loss is intuitive but unreliable.
In practice, the discriminator is usually deeper and sometimes has more filters per layer than the generator.
— NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
Soumith Chintala, one of the co-authors of the DCGAN paper, made a presentation at NIPS 2016 titled “How to Train a GAN?” summarizing many tips and tricks.
The video is available on YouTube and is highly recommended. A summary of the tips is also available as a GitHub repository titled “How to Train a GAN? Tips and tricks to make GANs work.”
The tips draw upon the suggestions from the DCGAN paper as well as elsewhere.
A summary of some of the more actionable tips is provided below.
- Normalize inputs to the range [-1, 1] and use tanh in the generator output.
- Flip the labels when training and loss function when training the generator.
- Sample Gaussian random numbers as input to the generator.
- Use mini batches of all real or all fake for calculating batch norm statistics.
- Use Leaky ReLU in the generator and discriminator.
- Use Average pooling and stride for downsampling; use ConvTranspose2D and stride for upsampling.
- Use label smoothing in the discriminator, with small random noise.
- Add random noise to the labels in the discriminator.
- Use DCGAN architecture, unless you have a good reason not to.
- A loss of 0.0 in the discriminator is a failure mode.
- If loss of the generator steadily decreases, it is likely fooling the discriminator with garbage images.
- Use labels if you have them.
- Add noise to inputs to the discriminator and decay the noise over time.
- Use dropout of 50 percent during train and generation.
Finally, the Deep Learning with Python book on Keras provides a number of practical tips to consider when training GANs, based mostly on the suggestions from the DCAN paper.
One additional tip suggests using the kernel size that is divisible by the stride size in the generator model to avoid the so-called “checkerboard” artifact (error).
… it’s common to see checkerboard artifacts caused by unequal coverage of the pixel space in the generator. To fix this, we use a kernel size that’s divisible by the stride size whenever we use a strided Conv2DTranpose or Conv2D in both the generator and the discriminator.
— Page 308, Deep Learning with Python, 2017.
This is the same suggestion provided in the 2016 piece on Distill titled “Deconvolution and Checkerboard Artifacts.”
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Chapter 20. Deep Generative Models, Deep Learning, 2016.
- Chapter 8. Generative Deep Learning, Deep Learning with Python, 2017.
Papers
- Generative Adversarial Networks, 2014.
- Tutorial: Generative Adversarial Networks, NIPS, 2016.
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
- Improved Techniques for Training GANs, 2016.
Articles
- How to Train a GAN? Tips and tricks to make GANs work
- Deconvolution and Checkerboard Artifacts, 2016.
Videos
- Ian Goodfellow, Introduction to GANs, NIPS 2016.
- Soumith Chintala, How to train a GAN, NIPS 2016 Workshop on Adversarial Training.
Summary
In this post, you discovered empirical heuristics for the configuration and training of stable general adversarial network models.
Specifically, you learned:
- The simultaneous training of generator and discriminator models in GANs is inherently unstable.
- Hard-earned empirically discovered configurations for the DCGAN provide a robust starting point for most GAN applications.
- Stable training of GANs remains an open problem and many other empirically discovered tips and tricks have been proposed and can be immediately adopted.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Tips for Training Stable Generative Adversarial Networks appeared first on Machine Learning Mastery.