
Author: Jason Brownlee
Time series forecasting can be challenging as there are many different methods you could use and many different hyperparameters for each method.
The Prophet library is an open-source library designed for making forecasts for univariate time series datasets. It is easy to use and designed to automatically find a good set of hyperparameters for the model in an effort to make skillful forecasts for data with trends and seasonal structure by default.
In this tutorial, you will discover how to use the Facebook Prophet library for time series forecasting.
After completing this tutorial, you will know:
- Prophet is an open-source library developed by Facebook and designed for automatic forecasting of univariate time series data.
- How to fit Prophet models and use them to make in-sample and out-of-sample forecasts.
- How to evaluate a Prophet model on a hold-out dataset.
Let’s get started.

Time Series Forecasting With Prophet in Python
Photo by Rinaldo Wurglitsch, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Prophet Forecasting Library
- Car Sales Dataset
- Load and Summarize Dataset
- Load and Plot Dataset
- Forecast Car Sales With Prophet
- Fit Prophet Model
- Make an In-Sample Forecast
- Make an Out-of-Sample Forecast
- Manually Evaluate Forecast Model
Prophet Forecasting Library
Prophet, or “Facebook Prophet,” is an open-source library for univariate (one variable) time series forecasting developed by Facebook.
Prophet implements what they refer to as an additive time series forecasting model, and the implementation supports trends, seasonality, and holidays.
Implements a procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects
— Package ‘prophet’, 2019.
It is designed to be easy and completely automatic, e.g. point it at a time series and get a forecast. As such, it is intended for internal company use, such as forecasting sales, capacity, etc.
For a great overview of Prophet and its capabilities, see the post:
The library provides two interfaces, including R and Python. We will focus on the Python interface in this tutorial.
The first step is to install the Prophet library using Pip, as follows:
sudo pip install fbprophet
Next, we can confirm that the library was installed correctly.
To do this, we can import the library and print the version number in Python. The complete example is listed below.
# check prophet version
import fbprophet
# print version number
print('Prophet %s' % fbprophet.__version__)
Running the example prints the installed version of Prophet.
You should have the same version or higher.
Prophet 0.5
Now that we have Prophet installed, let’s select a dataset we can use to explore using the library.
Car Sales Dataset
We will use the monthly car sales dataset.
It is a standard univariate time series dataset that contains both a trend and seasonality. The dataset has 108 months of data and a naive persistence forecast can achieve a mean absolute error of about 3,235 sales, providing a lower error limit.
No need to download the dataset as we will download it automatically as part of each example.
Load and Summarize Dataset
First, let’s load and summarize the dataset.
Prophet requires data to be in Pandas DataFrames. Therefore, we will load and summarize the data using Pandas.
We can load the data directly from the URL by calling the read_csv() Pandas function, then summarize the shape (number of rows and columns) of the data and view the first few rows of data.
The complete example is listed below.
# load the car sales dataset from pandas import read_csv # load data path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' df = read_csv(path, header=0) # summarize shape print(df.shape) # show first few rows print(df.head())
Running the example first reports the number of rows and columns, then lists the first five rows of data.
We can see that as we expected, there are 108 months worth of data and two columns. The first column is the date and the second is the number of sales.
Note that the first column in the output is a row index and is not a part of the dataset, just a helpful tool that Pandas uses to order rows.
(108, 2)
Month Sales
0 1960-01 6550
1 1960-02 8728
2 1960-03 12026
3 1960-04 14395
4 1960-05 14587
Load and Plot Dataset
A time-series dataset does not make sense to us until we plot it.
Plotting a time series helps us actually see if there is a trend, a seasonal cycle, outliers, and more. It gives us a feel for the data.
We can plot the data easily in Pandas by calling the plot() function on the DataFrame.
The complete example is listed below.
# load and plot the car sales dataset from pandas import read_csv from matplotlib import pyplot # load data path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' df = read_csv(path, header=0) # plot the time series df.plot() pyplot.show()
Running the example creates a plot of the time series.
We can clearly see the trend in sales over time and a monthly seasonal pattern to the sales. These are patterns we expect the forecast model to take into account.
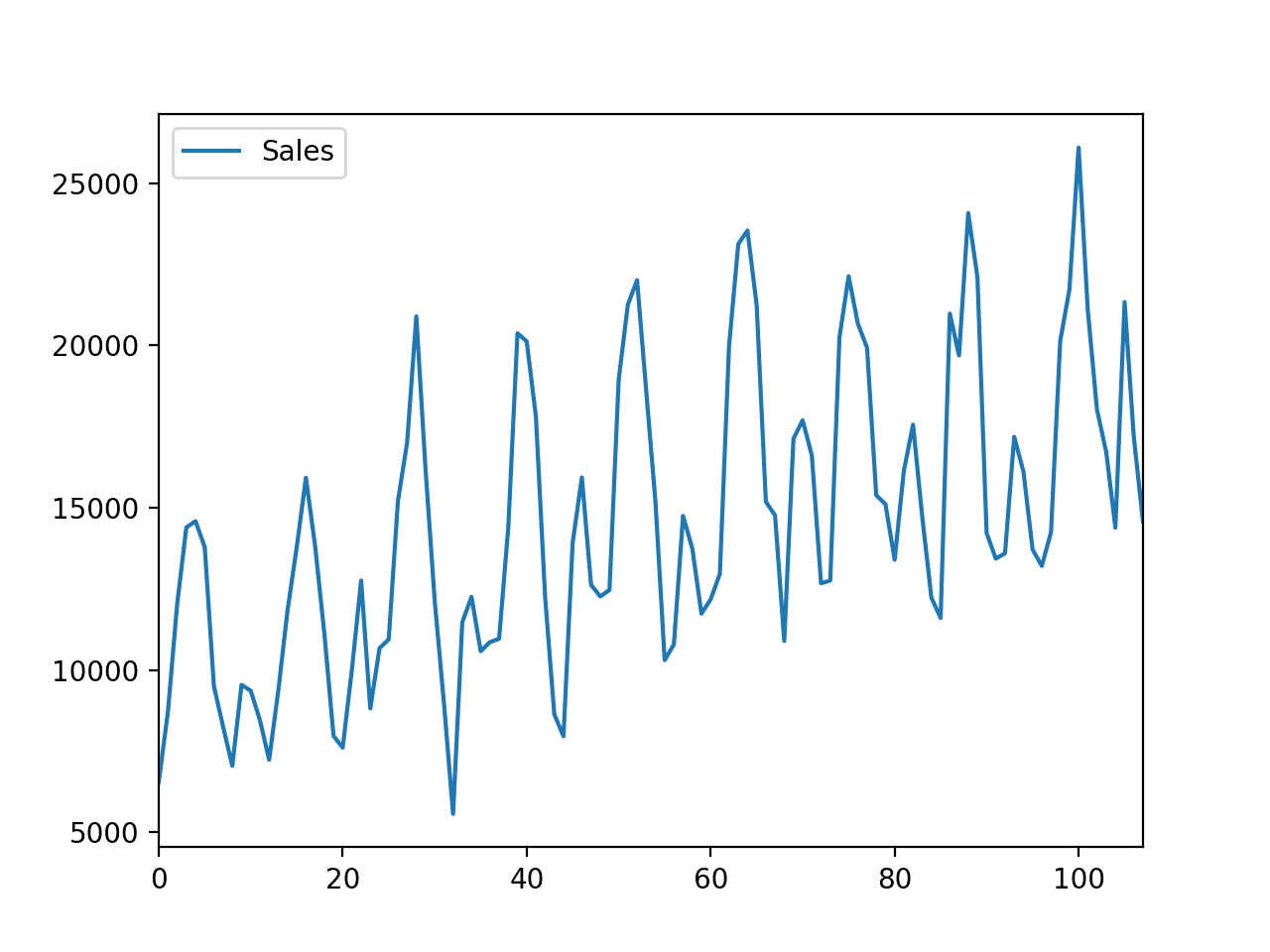
Line Plot of Car Sales Dataset
Now that we are familiar with the dataset, let’s explore how we can use the Prophet library to make forecasts.
Forecast Car Sales With Prophet
In this section, we will explore using the Prophet to forecast the car sales dataset.
Let’s start by fitting a model on the dataset
Fit Prophet Model
To use Prophet for forecasting, first, a Prophet() object is defined and configured, then it is fit on the dataset by calling the fit() function and passing the data.
The Prophet() object takes arguments to configure the type of model you want, such as the type of growth, the type of seasonality, and more. By default, the model will work hard to figure out almost everything automatically.
The fit() function takes a DataFrame of time series data. The DataFrame must have a specific format. The first column must have the name ‘ds‘ and contain the date-times. The second column must have the name ‘y‘ and contain the observations.
This means we change the column names in the dataset. It also requires that the first column be converted to date-time objects, if they are not already (e.g. this can be down as part of loading the dataset with the right arguments to read_csv).
For example, we can modify our loaded car sales dataset to have this expected structure, as follows:
... # prepare expected column names df.columns = ['ds', 'y'] df['ds']= to_datetime(df['ds'])
The complete example of fitting a Prophet model on the car sales dataset is listed below.
# fit prophet model on the car sales dataset from pandas import read_csv from pandas import to_datetime from fbprophet import Prophet # load data path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' df = read_csv(path, header=0) # prepare expected column names df.columns = ['ds', 'y'] df['ds']= to_datetime(df['ds']) # define the model model = Prophet() # fit the model model.fit(df)
Running the example loads the dataset, prepares the DataFrame in the expected format, and fits a Prophet model.
By default, the library provides a lot of verbose output during the fit process. I think it’s a bad idea in general as it trains developers to ignore output.
Nevertheless, the output summarizes what happened during the model fitting process, specifically the optimization processes that ran.
INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
Initial log joint probability = -4.39613
Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
99 270.121 0.00413718 75.7289 1 1 120
Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
179 270.265 0.00019681 84.1622 2.169e-06 0.001 273 LS failed, Hessian reset
199 270.283 1.38947e-05 87.8642 0.3402 1 299
Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
240 270.296 1.6343e-05 89.9117 1.953e-07 0.001 381 LS failed, Hessian reset
299 270.3 4.73573e-08 74.9719 0.3914 1 455
Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
300 270.3 8.25604e-09 74.4478 0.3522 0.3522 456
Optimization terminated normally:
Convergence detected: absolute parameter change was below tolerance
I will not reproduce this output in subsequent sections when we fit the model.
Next, let’s make a forecast.
Make an In-Sample Forecast
It can be useful to make a forecast on historical data.
That is, we can make a forecast on data used as input to train the model. Ideally, the model has seen the data before and would make a perfect prediction.
Nevertheless, this is not the case as the model tries to generalize across all cases in the data.
This is called making an in-sample (in training set sample) forecast and reviewing the results can give insight into how good the model is. That is, how well it learned the training data.
A forecast is made by calling the predict() function and passing a DataFrame that contains one column named ‘ds‘ and rows with date-times for all the intervals to be predicted.
There are many ways to create this “forecast” DataFrame. In this case, we will loop over one year of dates, e.g. the last 12 months in the dataset, and create a string for each month. We will then convert the list of dates into a DataFrame and convert the string values into date-time objects.
... # define the period for which we want a prediction future = list() for i in range(1, 13): date = '1968-%02d' % i future.append([date]) future = DataFrame(future) future.columns = ['ds'] future['ds']= to_datetime(future['ds'])
This DataFrame can then be provided to the predict() function to calculate a forecast.
The result of the predict() function is a DataFrame that contains many columns. Perhaps the most important columns are the forecast date time (‘ds‘), the forecasted value (‘yhat‘), and the lower and upper bounds on the predicted value (‘yhat_lower‘ and ‘yhat_upper‘) that provide uncertainty of the forecast.
For example, we can print the first few predictions as follows:
... # summarize the forecast print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head())
Prophet also provides a built-in tool for visualizing the prediction in the context of the training dataset.
This can be achieved by calling the plot() function on the model and passing it a result DataFrame. It will create a plot of the training dataset and overlay the prediction with the upper and lower bounds for the forecast dates.
... print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head()) # plot forecast model.plot(forecast) pyplot.show()
Tying this all together, a complete example of making an in-sample forecast is listed below.
# make an in-sample forecast from pandas import read_csv from pandas import to_datetime from pandas import DataFrame from fbprophet import Prophet from matplotlib import pyplot # load data path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' df = read_csv(path, header=0) # prepare expected column names df.columns = ['ds', 'y'] df['ds']= to_datetime(df['ds']) # define the model model = Prophet() # fit the model model.fit(df) # define the period for which we want a prediction future = list() for i in range(1, 13): date = '1968-%02d' % i future.append([date]) future = DataFrame(future) future.columns = ['ds'] future['ds']= to_datetime(future['ds']) # use the model to make a forecast forecast = model.predict(future) # summarize the forecast print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head()) # plot forecast model.plot(forecast) pyplot.show()
Running the example forecasts the last 12 months of the dataset.
The first five months of the prediction are reported and we can see that values are not too different from the actual sales values in the dataset.
ds yhat yhat_lower yhat_upper 0 1968-01-01 14364.866157 12816.266184 15956.555409 1 1968-02-01 14940.687225 13299.473640 16463.811658 2 1968-03-01 20858.282598 19439.403787 22345.747821 3 1968-04-01 22893.610396 21417.399440 24454.642588 4 1968-05-01 24212.079727 22667.146433 25816.191457
Next, a plot is created. We can see the training data are represented as black dots and the forecast is a blue line with upper and lower bounds in a blue shaded area.
We can see that the forecasted 12 months is a good match for the real observations, especially when the bounds are taken into account.
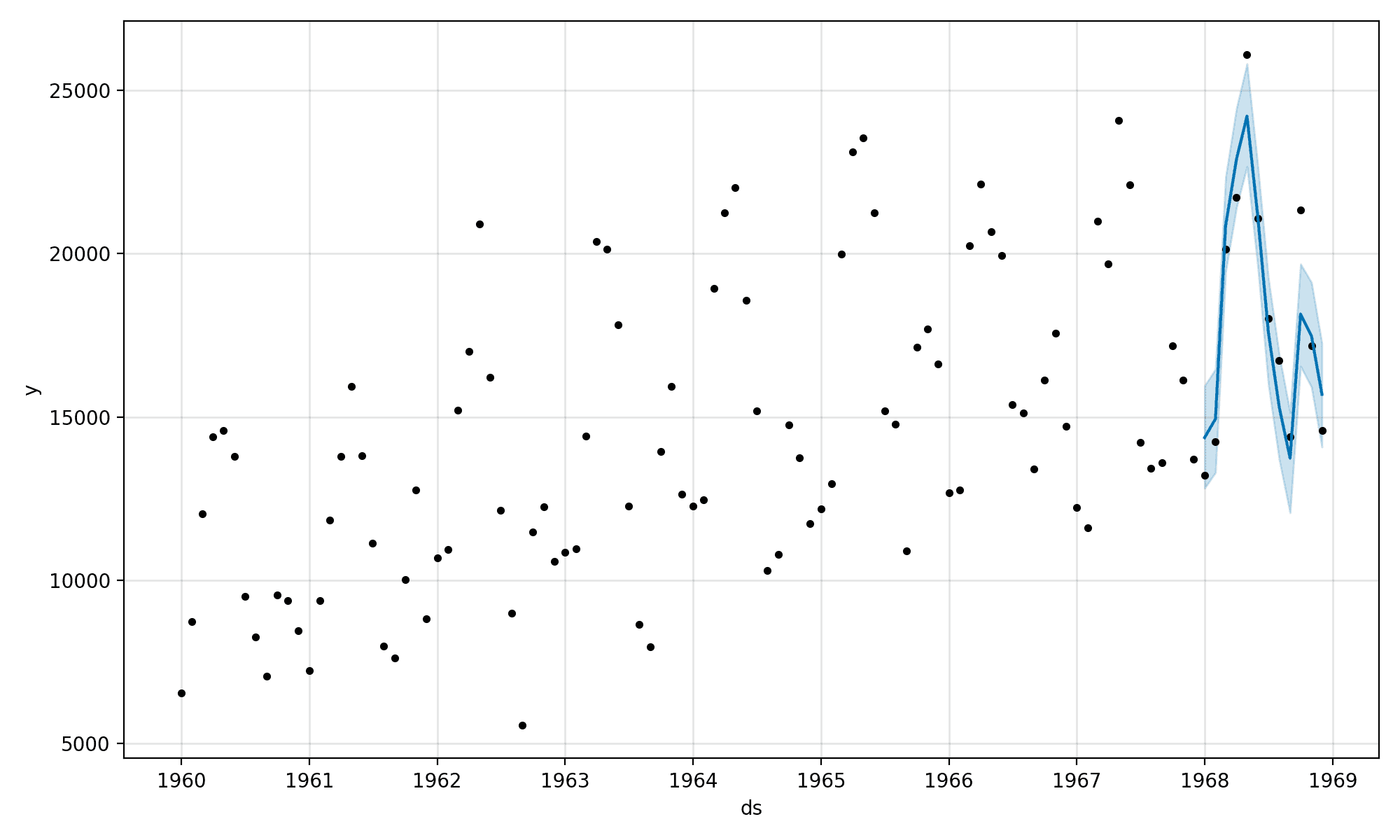
Plot of Time Series and In-Sample Forecast With Prophet
Make an Out-of-Sample Forecast
In practice, we really want a forecast model to make a prediction beyond the training data.
This is called an out-of-sample forecast.
We can achieve this in the same way as an in-sample forecast and simply specify a different forecast period.
In this case, a period beyond the end of the training dataset, starting 1969-01.
... # define the period for which we want a prediction future = list() for i in range(1, 13): date = '1969-%02d' % i future.append([date]) future = DataFrame(future) future.columns = ['ds'] future['ds']= to_datetime(future['ds'])
Tying this together, the complete example is listed below.
# make an out-of-sample forecast from pandas import read_csv from pandas import to_datetime from pandas import DataFrame from fbprophet import Prophet from matplotlib import pyplot # load data path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' df = read_csv(path, header=0) # prepare expected column names df.columns = ['ds', 'y'] df['ds']= to_datetime(df['ds']) # define the model model = Prophet() # fit the model model.fit(df) # define the period for which we want a prediction future = list() for i in range(1, 13): date = '1969-%02d' % i future.append([date]) future = DataFrame(future) future.columns = ['ds'] future['ds']= to_datetime(future['ds']) # use the model to make a forecast forecast = model.predict(future) # summarize the forecast print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head()) # plot forecast model.plot(forecast) pyplot.show()
Running the example makes an out-of-sample forecast for the car sales data.
The first five rows of the forecast are printed, although it is hard to get an idea of whether they are sensible or not.
ds yhat yhat_lower yhat_upper 0 1969-01-01 15406.401318 13751.534121 16789.969780 1 1969-02-01 16165.737458 14486.887740 17634.953132 2 1969-03-01 21384.120631 19738.950363 22926.857539 3 1969-04-01 23512.464086 21939.204670 25105.341478 4 1969-05-01 25026.039276 23544.081762 26718.820580
A plot is created to help us evaluate the prediction in the context of the training data.
The new one-year forecast does look sensible, at least by eye.
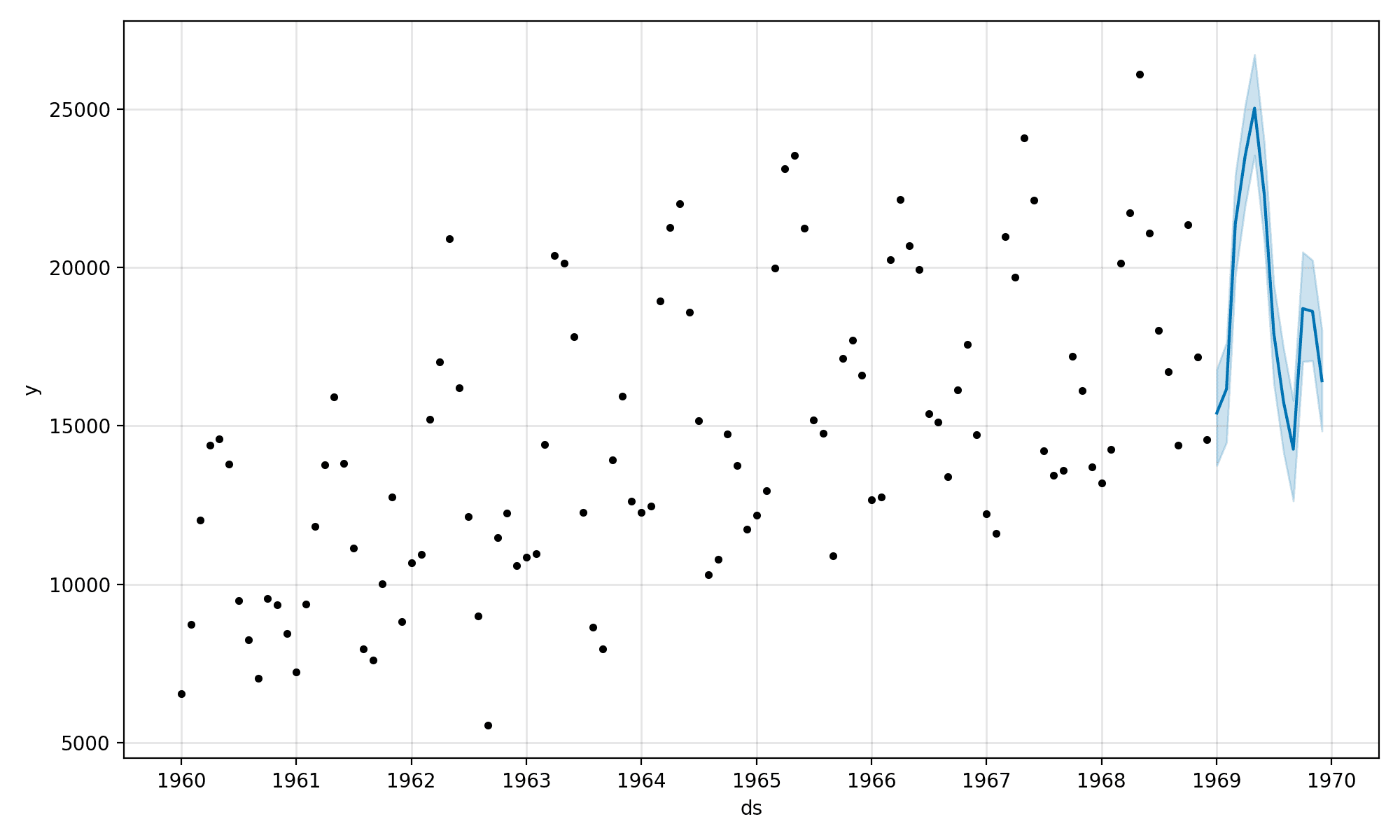
Plot of Time Series and Out-of-Sample Forecast With Prophet
Manually Evaluate Forecast Model
It is critical to develop an objective estimate of a forecast model’s performance.
This can be achieved by holding some data back from the model, such as the last 12 months. Then, fitting the model on the first portion of the data, using it to make predictions on the held-pack portion, and calculating an error measure, such as the mean absolute error across the forecasts. E.g. a simulated out-of-sample forecast.
The score gives an estimate of how well we might expect the model to perform on average when making an out-of-sample forecast.
We can do this with the samples data by creating a new DataFrame for training with the last 12 months removed.
... # create test dataset, remove last 12 months train = df.drop(df.index[-12:]) print(train.tail())
A forecast can then be made on the last 12 months of date-times.
We can then retrieve the forecast values and the expected values from the original dataset and calculate a mean absolute error metric using the scikit-learn library.
...
# calculate MAE between expected and predicted values for december
y_true = df['y'][-12:].values
y_pred = forecast['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
print('MAE: %.3f' % mae)
It can also be helpful to plot the expected vs. predicted values to see how well the out-of-sample prediction matches the known values.
... # plot expected vs actual pyplot.plot(y_true, label='Actual') pyplot.plot(y_pred, label='Predicted') pyplot.legend() pyplot.show()
Tying this together, the example below demonstrates how to evaluate a Prophet model on a hold-out dataset.
# evaluate prophet time series forecasting model on hold out dataset
from pandas import read_csv
from pandas import to_datetime
from pandas import DataFrame
from fbprophet import Prophet
from sklearn.metrics import mean_absolute_error
from matplotlib import pyplot
# load data
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv'
df = read_csv(path, header=0)
# prepare expected column names
df.columns = ['ds', 'y']
df['ds']= to_datetime(df['ds'])
# create test dataset, remove last 12 months
train = df.drop(df.index[-12:])
print(train.tail())
# define the model
model = Prophet()
# fit the model
model.fit(train)
# define the period for which we want a prediction
future = list()
for i in range(1, 13):
date = '1968-%02d' % i
future.append([date])
future = DataFrame(future)
future.columns = ['ds']
future['ds'] = to_datetime(future['ds'])
# use the model to make a forecast
forecast = model.predict(future)
# calculate MAE between expected and predicted values for december
y_true = df['y'][-12:].values
y_pred = forecast['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
print('MAE: %.3f' % mae)
# plot expected vs actual
pyplot.plot(y_true, label='Actual')
pyplot.plot(y_pred, label='Predicted')
pyplot.legend()
pyplot.show()
Running the example first reports the last few rows of the training dataset.
It confirms the training ends in the last month of 1967 and 1968 will be used as the hold-out dataset.
ds y 91 1967-08-01 13434 92 1967-09-01 13598 93 1967-10-01 17187 94 1967-11-01 16119 95 1967-12-01 13713
Next, a mean absolute error is calculated for the forecast period.
In this case we can see that the error is approximately 1,336 sales, which is much lower (better) than a naive persistence model that achieves an error of 3,235 sales over the same period.
MAE: 1336.814
Finally, a plot is created comparing the actual vs. predicted values. In this case, we can see that the forecast is a good fit. The model has skill and forecast that looks sensible.
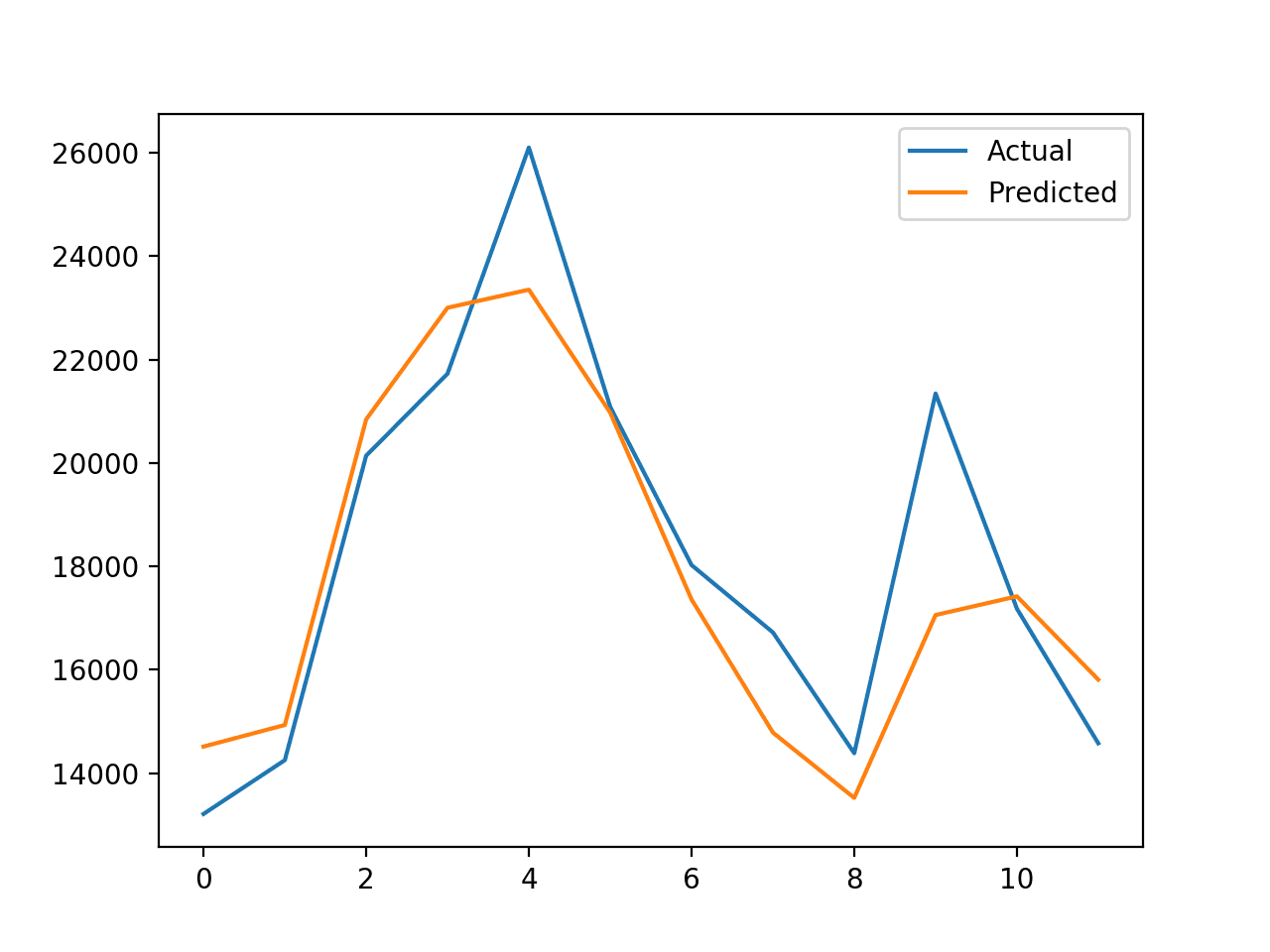
Plot of Actual vs. Predicted Values for Last 12 Months of Car Sales
The Prophet library also provides tools to automatically evaluate models and plot results, although those tools don’t appear to work well with data above one day in resolution.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Prophet Homepage.
- Prophet GitHub Project.
- Prophet API Documentation.
- Prophet: forecasting at scale, 2017.
- Forecasting at scale, 2017.
- Car Sales Dataset.
- Package ‘prophet’, R Documentation.
Summary
In this tutorial, you discovered how to use the Facebook Prophet library for time series forecasting.
Specifically, you learned:
- Prophet is an open-source library developed by Facebook and designed for automatic forecasting of univariate time series data.
- How to fit Prophet models and use them to make in-sample and out-of-sample forecasts.
- How to evaluate a Prophet model on a hold-out dataset.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Time Series Forecasting With Prophet in Python appeared first on Machine Learning Mastery.